《apache》专题
-
使用Apache HttpClient的Facade时,是否可以同时获取状态代码和正文内容?[重复]
我在一些示例代码中使用Apache的HttpClient Fluent Facade,供开发人员扩展。他们非常喜欢fluent facade,它可以直接调用: 此外,我还可以通过调用以下命令获取状态代码: 不幸的是,在一些情况下,我除了需要主体之外还需要状态代码。基于这个问题,我认为我可以让他们学习HttpClient对象- 但是,这意味着初始化HttpClient对象并似乎拒绝Fluent接口和
-
在使用Apache的HTTP客户端时,建议使用什么方法将HTTP响应作为字符串获取?[副本]
我刚刚开始使用Apache的HTTP客户端库,并注意到没有一个内置的方法将HTTP响应作为字符串获取。我只是想把它作为字符串,这样我就可以把它传递给我正在使用的任何解析库。 以字符串形式获取HTTP响应的推荐方法是什么?以下是我提出请求的代码:
-
apache lucene 4的自定义标记器
我有一个标记化的文本(拆分的句子和拆分的单词)。并将基于此结构创建Apache Lucene索引。什么是最简单的方法来扩展或替换一个standart标记器使用自定义标记。我正在查看StandardTokenizerImpl,但似乎非常复杂。可能还有别的办法吗?
-
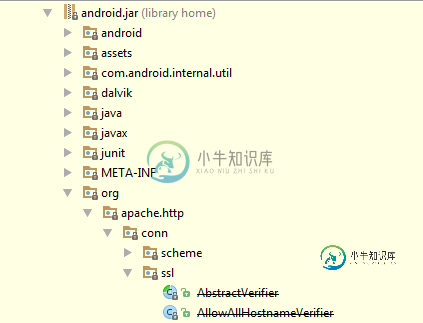 API23更新后Android SDK与Apache HTTP的冲突
API23更新后Android SDK与Apache HTTP的冲突在我的项目中,我使用了以下库: 一切都很好,直到我为API23更新了Android工具。然后,当我尝试执行HttpPost时,会出现以下异常: 这是发生这种情况的库代码: 在查看外部库时,我可以看到Android.jar下的类: 提前感谢!
-
在Apache Camel中,如果一个endpoint不存在,我如何接收一个错误?
我们使用Camel fluent构建器来设置一系列复杂的路由,其中我们使用RecipientList功能使用动态路由。 我们遇到过这样的问题:在某些情况下,收件人列表包含不存在的消息传递endpoint(例如,之类的东西)。 一个简单的例子是这样的: 我如何配置路由,以便如果交换机尝试路由到一个不存在的endpoint,就会抛出错误? 我正在使用Camel 2.9. x,并且我已经尝试了死信通道和
-
在Apache Camel中测试死信通道
我一直在关注向死信频道发送消息的例子,但还没有找到如何测试这一点。消息确实会被路由到DLC,但我想确保这是经过测试的。 例如,我将如何测试消息是否在 log:dead endpoint上接收。此代码位于从 CamelTestSupport 扩展的测试类中: 一种选择是将其写入新的路由,但我希望使用开箱即用的记录器。
-
异常未传播到 Apache Camel 中的错误处理程序
我有一个定义doTry-doCatch块的路由。当在doCatch块中处理异常时,我希望将其传播到错误处理程序,以确保在本地处理后将消息添加到死信队列中。问题是我无法让错误处理程序的传播工作(“defaultErrorHandler called!”未打印到控制台)。我也尝试过onException,但也没有成功。 任何提示都非常感谢。此致,奥利弗
-
如何在apachecamel中拆分json数组
我从基于apache-camel-spark的rest接口获得一个json数组作为输入。开始时,我想通过apache camels路线分割json-array来处理每个元素。我该怎么做? 我的测试输入json: 对于这个问题,我在stackoverflow上找到了一些间接描述的问题: link 1, link 2, link 3。 根据这些示例,我尝试了以下骆驼路线: 当我这样做时,我总是得到以下
-
Apache Camel启动包时出错
学习Apache Camel-尝试在jboss-fuse-6.1.0.redhat上部署应用程序-379。 POM如下 在数据库配置文件中配置了以下内容 并在路由中调用了sql组件 在引信上部署时- 已经使用wrap:install安装了jar,仍然出现上述错误 请帮我弄清楚。谢谢
-
Apache Camel:属性和属性占位符无效的RecipientList
我正在尝试使用骆驼JavaDSL将文件路由到SFTP服务器,如下所示: 但是,当消息到达此终结点时,Camel 会引发以下异常: 我可以看到在堆栈跟踪中打印的交易所上设置了目标目录属性。如果我替换 exchangeProperty(destinationDir) 在具有实际目标目录(tmp/目标/dir 1/)的路由中,它工作正常。问题是,我需要目标目录是动态的。我尝试过在路由中使用( 在调试Ca
-
Apache-cxf wsdlvalidator在MIME中返回错误:部分
Apache-cxf wsdlvalidator返回 wsdl文档示例来自:https://github.com/wso2/wso2-axis2/blob/master/modules/xmlbeans/test-resources/mime-doc.wsdl。(我还尝试了其他例子) 如果将“mime:part”更改为“part”,验证器将返回错误: WSDLValidator错误:javax.w
-
通过相关管道处理DataFlow/Apache Beam中的拒绝
我有一个从BigQuery获取数据并将其写入GCS的管道,但是,如果我发现任何拒绝,我希望将它们正确地添加到一个BigQuery表中。我将拒绝收集到一个全局列表变量中,然后将列表加载到BigQuery表中。当我在本地运行它时,这个过程工作得很好,因为管道以正确的顺序运行。当我使用dataflowrunner运行它时,它不能保证顺序(我希望pipeline1在Pipeline2之前运行。有没有一种方
-
优化apache beam/cloud数据流启动
我用apache-beam做了几个测试,使用了自动缩放工作人员和1个工作人员,每次我看到启动时间大约为2分钟。是否有可能缩短启动时间,如果有,建议哪些最佳做法来缩短启动时间?
-
Apache分束DoFn不会在数据流上将工作分散到多个工作人员
我正在学习使用可拆分DOFN。我预计我的工作将分配给500名员工,但Dataflow只运行了1或2名员工。我是否错误地理解或实现了可拆分DoFn? 我的beam版本是2.16.0
-
在Apache Beam中添加2个Dofn之间的依赖关系
是否有任何方法我可以创建2个Dofn之间的依赖关系,以便它将等待第一个Dofn方法完成,然后第二个Dofn方法将运行。只是想知道如何实现这个用例。