《apache》专题
-
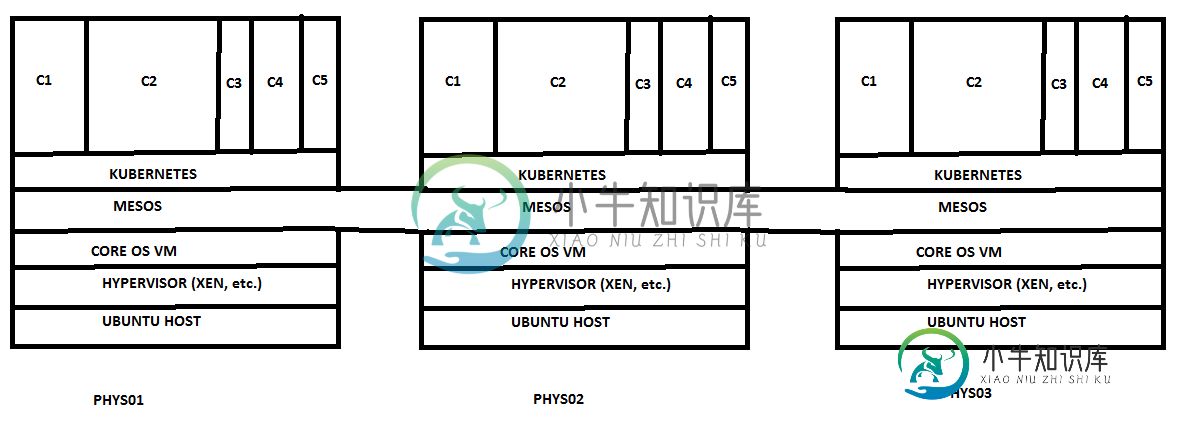 Apache Mesos实际上是做什么的?
Apache Mesos实际上是做什么的?我正试图把我的头缠在Apache Mesos上,需要澄清几个项目。 我对Mesos的理解是,它是一个安装在集群中的每个物理/VM服务器(“节点”)上的可执行文件,然后提供一个Java API(不知何故),将每个单独的节点视为计算资源(CPU/RAM/等)的集体池。因此,对于使用Java API编码的程序,他们只看到一组资源,而不必担心如何/在哪里部署代码。 因此,首先,我在这里的理解可能是根本错误
-
如何在2.2.0中得到一个给定的Apache Spark Dataframe的Cassandra cql字符串?
看起来我可以创建一个新的TableDef,但是我必须自己完成整个映射,而且在某些情况下,像ColumnType这样的必要函数在Java中是不可访问的。例如,我试图创建一个新的ColumnDef,如下所示 目的:从Spark DataFrame中获取CQL create语句。 Input My dataframe可以有任意数量的列,这些列具有各自的Spark类型。假设我有一个有100列的Spark
-
查找Apache Storm中运行的拓扑jar版本
我有一个运行的storm拓扑开始使用一个打包的JAR。我正在尝试查找拓扑正在运行的jar的版本。据我所知,Storm只会显示正在运行的Storm版本,而不会显示正在运行的拓扑版本。 运行“storm version”命令只给出storm运行的版本,我在storm UI的拓扑部分中没有看到任何指示拓扑版本的内容。 有没有办法让Storm报告这一点,还是我最好的办法设置一个属性文件?理想情况下,这将通
-
Apache Spark:如何强制使用一定数量的核心?
但是我仍然不能强迫spark使用100个内核,这是我在对早期测试进行基准测试时所需要的。 我使用的是Apache Spark 1.6.1。集群上的每个节点包括驱动程序都有16个内核和112GB内存。它们在Azure(hdinsight集群)上。2个驱动节点+7个工作节点。
-
在单个节点上运行的Apache Spark和Mesos
我对在Mesos上测试Spark运行感兴趣。我在Virtualbox中创建了一个Hadoop2.6.0单节点集群,并在其上安装了Spark。我可以使用Spark成功地处理HDFS中的文件。
-
Cassandra连接器Apache Spark:本地类不兼容
我试图使用Cassandra Spark连接器将rdd与Cassandra表连接起来: 它在独立模式下工作,但当我在集群模式下执行时,我会得到以下错误: 会发生什么事?
-
Apache Spark配置
我在运行spark配置时面临内存问题,我已经将设置更改为最大内存,但它仍然不能工作。请查看以下问题:命令- 错误-错误集群。YarnScheduler:Ampanacdddbp01.au.amp.local上丢失的遗嘱执行人9:123643 ms后Executor heartbeat超时警告调度器。TaskSetManager:在阶段0.0中丢失任务19.0(TID 19,ampanacdddbp
-
apachekafka分区
我已经在kafka上工作了相当长的六个月,我对用户延迟和存储到主题分区中的数据有一些疑问。 问题1:最初,当我开始阅读Kafka并了解如何使用Kafka的功能时,我被教导说,一个只有一部分和一个复制因子的主题会创造奇迹。经过相当长的六个月的工作,将我的项目迁移到live之后,使用我的主题消息的消费者开始给我一个延迟。我阅读了许多关于消费者延迟的堆栈溢出答案,得出结论,如果我增加某个主题的分区和复制
-
Apache Spark如何实现洗牌阶段?
它是否执行map1,然后按键分区,并将中间数据保存在磁盘(内存)上? 然后读取中间文件2次,一次用于map2 map3分支,第二次用于map4 map5,而不再次计算rddB,即使我们没有在rddB上执行隐式缓存?
-
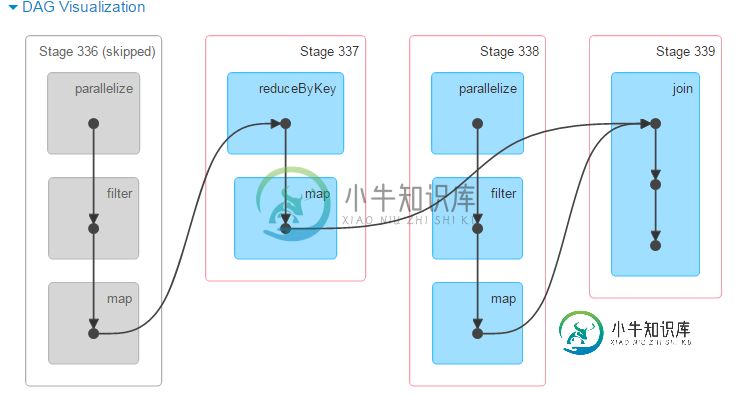 在Apache Spark web UI中,“跳过的阶段”是什么意思?
在Apache Spark web UI中,“跳过的阶段”是什么意思?从我的火花UI。跳过是什么意思?
-
运行python的apache spark流示例
我试图运行示例目录中给出的python spark流作业- https://spark.apache.org/docs/2.1.1/streaming-programming-guide.html
-
使用Apache POI生成的Excel已损坏,返回fronm API REST spring boot
编辑: 如果我直接从浏览器命中endpoint,文件就会被正确下载。所以我猜问题出在前面,以及用接收到的数据创建和保存文件的方式。 我有一个Java/spring boot的应用程序,我想在其中构建一个APIendpoint,它创建并返回一个可下载的excel文件。以下是我的控制器endpoint: 这是角度控制器: 和服务: 生成成功,文件已下载,但我认为它已损坏,因为Excel无法打开它。 有
-
在 Oracle 数据库中使用 Apache FOP 生成包含 SVG 图像的 PDF
我正在尝试使用Apache FOP在Oracle 11g数据库中生成PDF文档。我已经使用loadjava工具将以下JAR文件中的类安装到我的模式中: < Li > commons-logging-1 . 0 . 4 . jar < li>commons-io-1.3.1.jar < Li > Avalon-framework-4 . 2 . 0 . jar < li>xml-apis-ext-1
-
Apache FOP embedded,如何使用配置文件
我正在使用Apache FOP将SVG渲染为PDF。这个SVG有一种特殊的字体,我也想在生成的PDF中使用。 我使用的配置文件如下所示: 我从示例配置中复制并粘贴了它,并编辑了所有不需要的渲染器。现在我尝试使用这样的配置: 这将呈现一个完美的PDF,但是没有使用字体。当我尝试cfg.getValue()时,我也会收到这条消息 文件/path/to/conf.xml:1:20中没有与配置元素“fop
-
断字不适用于dita-ot 2.5.1和Apache FOP
我使用dia-ot渲染到pdf。最近,我从dia-ot 1.8. M2升级到2.5.1更新我的pdf插件是相当多的工作,但我唯一不能正常工作的是断字。 我按照Apache网站上的描述做了这一切。 详细说明相关说明: 从OFFO下载预编译的JAR,并将其放在{fop dir}/lib目录中,或放在您选择的目录中(并将JAR的完整路径附加到环境变量fop_HYPHENATION_path中) 这就是它