《pandas》专题
-
 pandas pd.read_csv()函数中parse_dates()参数的用法说明
pandas pd.read_csv()函数中parse_dates()参数的用法说明本文向大家介绍pandas pd.read_csv()函数中parse_dates()参数的用法说明,包括了pandas pd.read_csv()函数中parse_dates()参数的用法说明的使用技巧和注意事项,需要的朋友参考一下 parse_dates : boolean or list of ints or names or list of lists or dict, default F
-
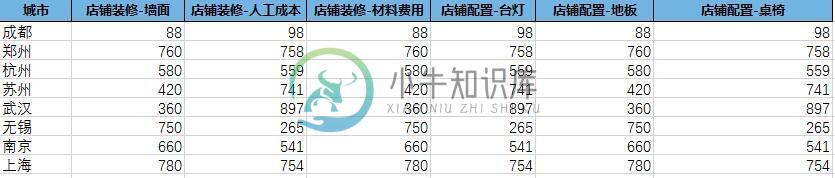 python pandas模糊匹配 读取Excel后 获取指定指标的操作
python pandas模糊匹配 读取Excel后 获取指定指标的操作本文向大家介绍python pandas模糊匹配 读取Excel后 获取指定指标的操作,包括了python pandas模糊匹配 读取Excel后 获取指定指标的操作的使用技巧和注意事项,需要的朋友参考一下 1.首先读取Excel文件 数据代表了各个城市店铺的装修和配置费用,要统计出装修和配置项的总费用并进行加和计算; 2.pandas实现过程 补充:pandas 中dataframe 中的模糊匹
-
解决一个pandas执行模糊查询sql的坑
本文向大家介绍解决一个pandas执行模糊查询sql的坑,包括了解决一个pandas执行模糊查询sql的坑的使用技巧和注意事项,需要的朋友参考一下 查询引擎使用了presto,在sql中使用了模糊查询。 一直报错: unsupported format character 解决方案 第一: 第二: 补充:pd.read_sql()知道这些就够用了 如下: 各参数意义 sql:SQL命令字符串 co
-
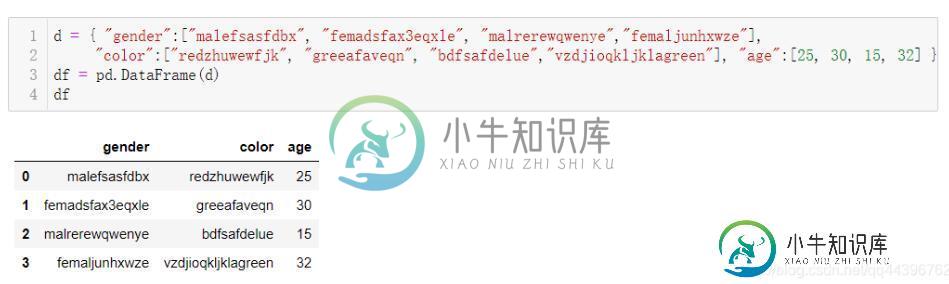 Pandas 模糊查询与替换的操作
Pandas 模糊查询与替换的操作本文向大家介绍Pandas 模糊查询与替换的操作,包括了Pandas 模糊查询与替换的操作的使用技巧和注意事项,需要的朋友参考一下 主要用到的工具:Pandas 、fuzzywuzzy Pandas:是基于numpy的一种工具,专门为分析大量数据而生,它包含大量的处理数据的函数和方法, 以下为pandas中文API: 缩写和包导入 在这个速查手册中,我们使用如下缩写: df:任意的Pandas D
-
Python Pandas,将DataFrame写入固定宽度文件(to_fwf?)
问题内容: 我知道熊猫有,但是有类似的东西吗?我正在寻找对字段宽度,数值精度和字符串对齐的支持。似乎没有做到这一点。 可以,但是我不想做: 那似乎是错误的。非常感谢您的想法。 问题答案: 除非有人在熊猫中实现此功能,否则您可以使用制表包:
-
pandas 快速处理 date_time 日期格式方法
本文向大家介绍pandas 快速处理 date_time 日期格式方法,包括了pandas 快速处理 date_time 日期格式方法的使用技巧和注意事项,需要的朋友参考一下 当数据很多,且日期格式不标准时的时候,如果pandas.to_datetime 函数使用不当,会使得处理时间变得很长,提升速度的关键在于format的使用。下面举例进行说明: 示例数据: date 格式:02.01.2013
-
Python Pandas:将选定的列保留为DataFrame而不是Series
问题内容: 从pandas DataFrame中选择单个列时(例如,或等),结果矢量将自动转换为Series而不是单列DataFrame。但是,我正在编写一些将DataFrame作为输入参数的函数。因此,我更喜欢处理单列DataFrame而不是Series,以便函数可以假定df.columns是可访问的。现在,我必须使用来将Series显式转换为DataFrame 。这似乎不是最干净的方法。是否有
-
将包含字符串的pandas系列转换为布尔值
问题内容: 我有一个名为数据帧作为 我想将列转换为布尔值(当状态为“已交付”而状态为“未交付”时),但是如果状态既不是“未交付”也不是“未交付”,则应将其视为“类似”。 我想用一个字典 所以我可以轻松地添加其他字符串,可以将其视为或。 问题答案: 您可以使用:
-
pandas每隔n行
问题内容: Dataframe.resample()仅适用于时间序列数据。我找不到从非时间序列数据中获取第n行的方法。最好的方法是什么? 问题答案: 我会使用,它根据整数位置并遵循常规python语法获取行/列切片。如果要每第5行:
-
Python Pandas为所选列的行最大值添加列
问题内容: data = {‘name’ : [‘bill’, ‘joe’, ‘steve’], ‘test1’ : [85, 75, 85], ‘test2’ : [35, 45, 83], ‘test3’ : [51, 61, 45]} frame = pd.DataFrame(data) 我想添加一个新列,以显示每一行的最大值。 所需的输出: 有时 可行,但大多数时候会出现此错误: Valu
-
将某些浮动数据框列格式化为pandas百分比
问题内容: 我正在尝试在IPython笔记本中写论文,但是在显示格式方面遇到了一些问题。说我有以下dataframe ,有什么方法可以格式化并转换为2位小数并转换为百分比。 内部数字不乘以100,例如-0.0057 = -0.57%。 问题答案: 使用round函数替换值,并格式化百分比数字的字符串表示形式: 舍入函数将浮点数舍入为该函数的第二个参数提供的小数位数。 字符串格式可让您根据需要表示数
-
获取总计pandas列
问题内容: 目标 我有一个Pandas数据框,如下所示,具有多个列,并希望获取列的总数。 数据框 -: 我的尝试 : 我试图使用和获得列的总和: 这将导致以下错误: 预期产量 我期望输出如下: 或者,我想编辑一个包含总数的新标题: 问题答案: 您应该使用: 然后与配合使用,在这种情况下,索引应设置为与需要求和的特定列相同: 因为如果传递标量,则将填充所有行的值: 另有两个解决方案,请参见以下应用程
-
利用Pandas和Numpy按时间戳将数据以Groupby方式分组
本文向大家介绍利用Pandas和Numpy按时间戳将数据以Groupby方式分组,包括了利用Pandas和Numpy按时间戳将数据以Groupby方式分组的使用技巧和注意事项,需要的朋友参考一下 首先说一下需求,我需要将数据以分钟为单位进行分组,然后每一分钟内的数据作为一行输出,因为不同时间的数据量不一样,所以所有数据按照最长的那组数据为准,不足的数据以各自的最后一个数据进行补足。 之后要介绍一下
-
删除pandas数据框中的未命名列
问题内容: 我有一个来自AG列的数据文件,如下所示,但是当我用它读取数据时,它毫无理由地在末尾打印了一个额外的列。 我已经多次查看过我的数据文件,但是其他任何列中都没有多余的数据。我在阅读时应如何删除此多余的列?谢谢 问题答案: df = df.loc[:, ~df.columns.str.contains(‘^Unnamed’)] 如果CSV文件的第一列具有索引值,则可以执行以下操作:
-
python pandas dataframe,是按值传递还是按引用传递
问题内容: 如果我将数据帧传递给函数并在函数内部对其进行修改,那么它是按值传递还是按引用传递? 我运行以下代码 函数调用后,的值不变。这是否意味着价值传递? 我也尝试了以下 事实证明,变化并没有。为什么会这样呢? 问题答案: 简短的答案是,Python始终会传递值,但每个Python变量实际上都是指向某个对象的指针,因此有时看起来像是传递引用。 在Python中,每个对象都是可变的或不可更改的。例