《数据结构》专题
-
Spark:数据帧Flatten中的嵌套数据结构
我需要展平一个数据帧,以便将其与Spark(Scala)中的另一个数据帧连接起来。 基本上,我的2个数据帧有以下模式: 数据流1 DF2 老实说,我不知道如何使DF2变平。最后,我需要连接DF.field4 = DF2.field9上的2个数据帧 我用的是2.1.0 我的第一个想法是使用爆炸,但在Spark 2.1.0中已经被否决了,有人能给我一点提示吗?
-
如何将平面数据结构显示为分层数据结构(Java)?
问题内容: 我最近在求职的实际测试中面对这个问题。 假设您得到了一个像这样的平面数据结构: 现在,从上面的平面数据结构中,我们想要显示类似下面的分层树结构的内容。 然后,如果我要向我的数组添加另一个条目,例如: 然后它应该在下面显示条目。 所以对于我目前正在使用的这类东西,可以遍历到第二级,但是不能遍历第三级。那么执行此操作的最佳方法是什么? 谢谢 编辑: 我被要求仅使用基于DOS的Java应用程
-
找到中位数的数据结构
这是一个面试问题。设计一个类,它存储整数并提供两个操作: 我想我可以使用BST,以便取O(logN)和取O(logN)(对于我应该添加每个节点的左/右子节点的数量)。 现在我想知道这是否是最有效的解决方案,没有更好的解决方案。
-
数据结构与算法 - Javascript数组
数组是一种线性表数据结构,它用一组连续的内存空间,来存储一组具有相同类型的数据(JS里可以是任意类型)。 关键点:连续的存储空间(数组可以进行随机访问) // js let data = [] // c int data[200] = { 0 }; // 编译时 就已经确定所有的值为零 // java int data[] = new int[3]; // 开辟了一个长度为3的数组 在Ch
-
四、数据结构:对象和数组
四、数据结构:对象和数组 On two occasions I have been asked, ‘Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?’ [...] I am not able rightly to apprehend the kind of c
-
OrientDB冻结数据库
无论何时可能需要将数据库状态设置为静态,意味着数据库未响应任何读取和写入操作的状态。 简单地说,数据库处于冻结状态。 在本章中,可以学习如何从OrientDB命令行冻结数据库。 以下语句是冻结数据库命令的基本语法。 注 - 只有在连接到远程或本地数据库中的特定数据库后,才能使用此命令。 示例 在这个例子中,我们将使用我们在前一章中创建的名为的数据库。 我们将从CLI冻结这个数据库。 可以使用以下命
-
复杂的数据结构Redis
问题内容: 可以说我有一个散列,例如 存储这种数据结构的“通常”方式是什么(或者您不会吗?) 您是否可以直接获得价值(例如,获取哈利:年龄? 一旦存储,您是否可以直接更改子键的值(例如,sally:weight = 100) 问题答案: 存储这种数据结构的“通常”方式是什么(或者您不会吗?) 例如,哈利(Harry)和莎莉(Sally)将分别存储在单独的散列中,其中字段代表其属性,例如年龄和体重。
-
内存中的数据结构
到目前为止,我们已经讨论了为了实现文件系统而需要存在于硬盘上的数据结构。 在这里,我们将了解要实现文件系统需要存在于内存中的数据结构。 内存数据结构用于文件系统管理以及通过缓存提高性能。 该信息在安装时间加载并在弹出时丢弃。 1. 内存安装表 内存中安装表包含正在安装到系统的所有设备的列表。 每当连接维护到设备时,其输入将在安装表中完成。 2. 内存目录结构缓存 这是CPU最近访问的目录列表。列表
-
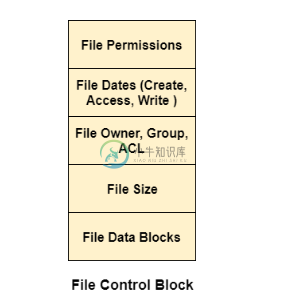 磁盘中的数据结构
磁盘中的数据结构有多种磁盘数据结构用于实现文件系统。 该结构可能会因操作系统而异。 1. 引导控制块 启动控制块包含从该卷启动操作系统所需的所有信息。 它在UNIX文件系统中被称为引导块。 在NTFS中,它被称为分区引导扇区。 2. 卷控制块 卷控制会阻止有关该音量的所有信息,如块的数量,每个块的大小,分区表,指向空闲块和空闲FCB块的指针。 在UNIX文件系统中,它被称为超级块。 在NTFS中,此信息存储在主文
-
Linux Data Structures ( Linux 数据结构)
本附录列出了本书中描述的 Linux 使用的主要的数据结构。为了在页面上访得下,它们经过了少量的编辑。 Block_dev_struct block_dev_struct 数据结构用于登记可用的块设备,让 buffer cache 使用。它们放在 blk_dev 向量表中。 参见 include/linux/blkdev.h struct blk_dev_struct { void (*reque
-
数据结构中的R *树
本文向大家介绍数据结构中的R *树,包括了数据结构中的R *树的使用技巧和注意事项,需要的朋友参考一下 基本概念 在数据处理的情况下,R *树被定义为为索引空间信息而实现的R树的变体。 R *树比标准R树的建造成本稍高,因为可能需要重新插入数据。但是生成的树通常具有更好的查询性能。与标准R树相同,它可以存储点和空间数据。R *树的概念由Norbert Beckmann,Hans-Peter Kri
-
可变模板数据结构
可变参数模板是接收不同数量参数的模板,可用于可与泛型类型一起运行的模型 法典: 观察:问这个问题的原因是为了理解varidiac模板操作,因此我不关心程序的使用,在上面的示例中:测试类正在失去对生成的子类的访问权(rest…) 问题是: 第一个值得怀疑的话题是:我知道函数和类可以有模板,但模板有什么用呢 疑问的第二个主题:在函数“Print2”中,为什么为Print2调用推导的模板是 怀疑的第三个
-
设计O(1)数据结构
null 高++;storage.put(high,element); 低++; 高--;
-
数据结构-随机队列
我目前正在研究普林斯顿算法第一部分的队列分配。其中一个任务是实现随机队列。这是一个关于使用不同数据结构的实现和权衡的问题。 问题: 随机化队列类似于堆栈或队列,只是从数据结构中的项中均匀随机地选择删除的项。创建实现以下API的通用数据类型: 这里的问题是实现de队列操作和迭代器,因为de队列删除并返回随机元素,迭代器以随机顺序迭代队列。 1.数组实现: 我考虑的主要实现是数组实现。除了随机性之外,
-
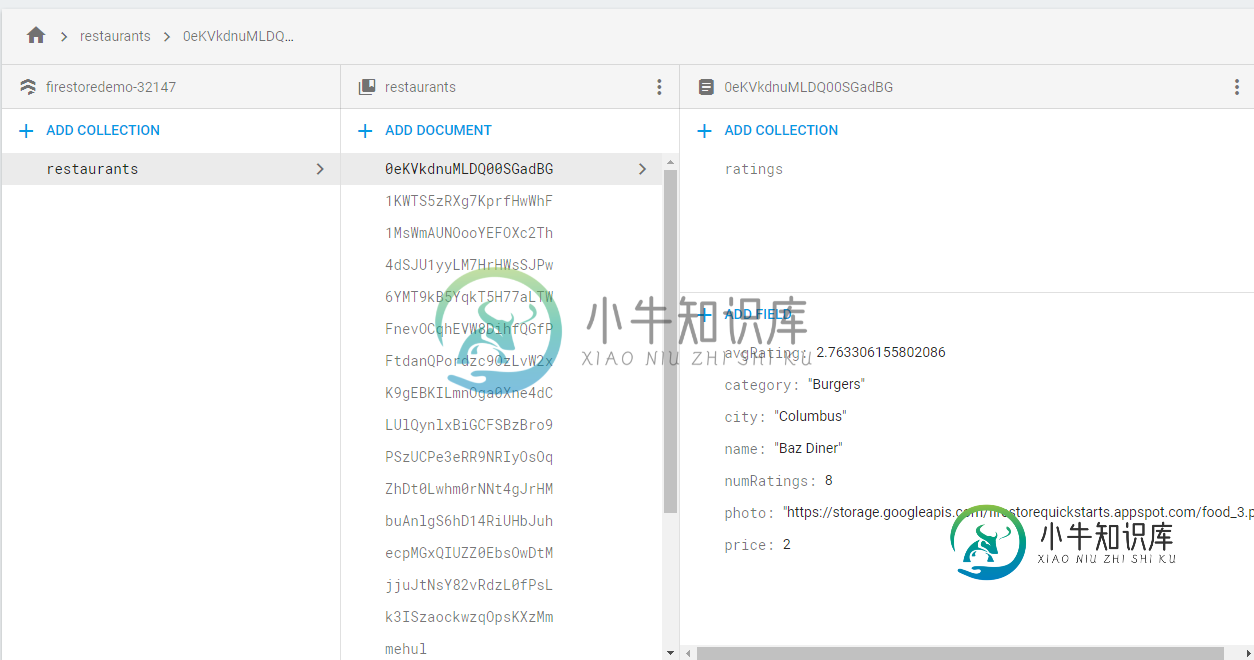 Cloud Firestore数据库结构化
Cloud Firestore数据库结构化云Firestore的Android示例应用的数据库结构如下所示: 现在考虑这样一种情况:第一家餐厅有大量的评级(这里评级是第一家餐厅id中的其他文档的集合),我只想显示所有餐厅的基本细节,如名称和城市。 我将通过创建如下所示的引用来实现这一点: 我对此有以下问题: 这是正确的方法吗?因为我正在获取一个文档快照,其中还包括我现在不需要的评级集合,因为它会降低加载速度? 我是否应该像在firebas