《数据结构》专题
-
数据结构 / 字典
字典类似于你通过联系人名字查找地址和联系人详细情况的地址簿,即,我们把键(名字)和值(详细情况)联系在一起。注意,键必须是唯一的,就像如果有两个人恰巧同名的话,你无法找到正确的信息。 注意,你只能使用不可变的对象(比如字符串)来作为字典的键,但是你可以不可变或可变的对象作为字典的值。基本说来就是,你应该只使用简单的对象作为键。 键值对在字典中以这样的方式标记:d = {key1 : value1,
-
数据结构 / 元组
元组和列表十分类似,只不过元组和字符串一样是 不可变的 即你不能修改元组。元组通过圆括号中用逗号分割的项目定义。元组通常用在使语句或用户定义的函数能够安全地采用一组值的时候,即被使用的元组的值不会改变。 使用元组 例9.2 使用元组 #!/usr/bin/python # Filename: using_tuple.py zoo = ('wolf','elephant','penguin') pr
-
数据结构 / 列表
list是处理一组有序项目的数据结构,即你可以在一个列表中存储一个 序列 的项目。假想你有一个购物列表,上面记载着你要买的东西,你就容易理解列表了。只不过在你的购物表上,可能每样东西都独自占有一行,而在Python中,你在每个项目之间用逗号分割。 列表中的项目应该包括在方括号中,这样Python就知道你是在指明一个列表。一旦你创建了一个列表,你可以添加、删除或是搜索列表中的项目。由于你可以增加或删
-
数据结构 / 简介
目录表 简介 列表 对象与类的快速入门 使用列表 元组 使用元组 元组与打印语句 字典 使用字典 序列 使用序列 参考 对象与参考 更多字符串的内容 字符串的方法 概括 简介 数据结构基本上就是——它们是可以处理一些 数据 的 结构 。或者说,它们是用来存储一组相关数据的。 在Python中有三种内建的数据结构——列表、元组和字典。我们将会学习如何使用它们,以及它们如何使编程变得简单。
-
数据结构(Data Structure)
学习如何在Java编程中使用数据结构。 以下是最常用的示例 - 如何打印n个数字的总和? 如何获取链表的第一个和最后一个元素? 如何在链表的第一个和最后一个位置添加元素? 如何将中缀表达式转换为后缀表达式? How to implement Queue? 如何使用堆栈反转字符串? 如何搜索链表中的元素? How to implement stack? 如何在向量中交换两个元素? 如何更新链表? 如
-
数据结构(Data Structures)
从语法的角度来看,Python数据结构非常直观,并且它们提供了大量的操作选择。 您需要选择Python数据结构,具体取决于数据涉及的内容,是否需要修改,或者是否是固定数据以及需要哪种访问类型,例如在开头/结尾/随机等。 Lists List表示Python中最通用的数据结构类型。 列表是一个容器,它在方括号之间包含逗号分隔值(项或元素)。 当我们想要处理多个相关值时,列表很有用。 当列表将数据保持
-
 数据结构思维
数据结构思维数据结构和算法是过去 50 年来最重要的发明之一,它们是软件工程师需要了解的基础工具。但是在我看来,这些话题的大部分书籍都过于理论,过于庞大,也是“自底向上”的
-
数据结构(Data Structures)
Java实用程序包提供的数据结构非常强大,可以执行各种功能。 这些数据结构由以下接口和类组成 - Enumeration BitSet Vector Stack Dictionary Hashtable Properties 所有这些类现在都是遗留的,Java-2引入了一个名为Collections Framework的新框架,将在下一章中讨论。 - 枚举 Enumeration接口本身不是数据结
-
内核数据结构
这不是 linux-insides-zh 中的一般章节。正如你从题目中理解到的,它主要描述 Linux 内核中的内部系统数据结构。比如说,中断描述符表 (Interrupt Descriptor Table), 全局描述符表 (Global Descriptor Table) 。 大部分信息来自于 Intel 和 AMD 官方手册。
-
数据结构-稀疏数组
稀疏数组核心 第一行表示了稀疏数组的组成核心,稀疏数组一共只有三列 第一行第一列表示数组一共有多少行,第一行第二列表示数组一共有多少行,第一行第三列表示数组中有多少个特殊值 从第一行之后的所有行表示数据行,第一列表示数据所在的行数,第二列表示数据坐在的列数,第三列表述具体数据的值 def get_sparse_arr(arr: 'sparse_arr') -> 'sparse_arr':
-
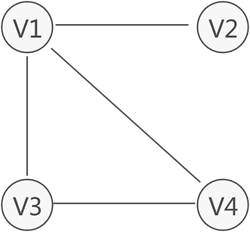 数据结构的图存储结构
数据结构的图存储结构主要内容:图存储结构基本常识,图存储结构的分类我们知道,数据之间的关系有 3 种,分别是 "一对一"、"一对多" 和 "多对多",前两种关系的数据可分别用 线性表和树结构存储,本节学习存储具有"多对多"逻辑关系数据的结构—— 图存储结构。 图 1 图存储结构示意图 图 1 所示为存储 V1、V2、V3、V4 的图结构,从图中可以清楚的看出数据之间具有的"多对多"关系。例如,V1 与 V4 和 V2 建立着联系,V4 与 V1 和 V3 建立着
-
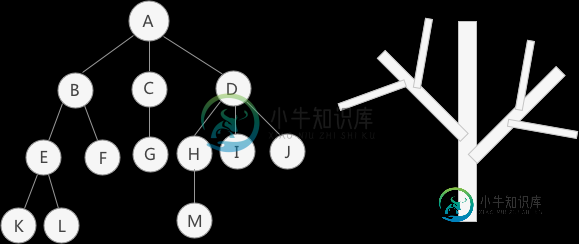 数据结构的树存储结构
数据结构的树存储结构主要内容:树的结点,子树和空树,结点的度和层次,有序树和无序树,森林,树的表示方法,总结之前介绍的所有的 数据结构都是 线性存储结构。本章所介绍的树结构是一种非线性存储结构,存储的是具有“一对多”关系的数据元素的集合。 (A)
-
6.18.Map抽象数据结构总结
在前面两章中,我们已经研究了可以用于实现 Map 抽象数据类型的几个数据结构。二叉搜索表,散列表,二叉搜索树和平衡二叉搜索树。 总结这一节,让我们总结 Map ADT 定义的关键操作的每个数据结构的性能(见 Table 1)。
-
Jython-使用Python数据结构还是Java数据结构更快?
我试图理解是否以及在什么情况下应该使用Python类和/或Java类。 如果要制作一个专门的字典/地图类,应该从Python的dict或者Java的HashMap或者TreeMap等中提取一个子类? 很容易使用Python的,因为它们更简单、更性感。但是Jython运行相对较慢的一个原因(在我看来是这样)似乎与动态键入有关。我最好说我对所有这些都不太清楚,而且我也没有花晚上的时间仔细研究Pytho
-
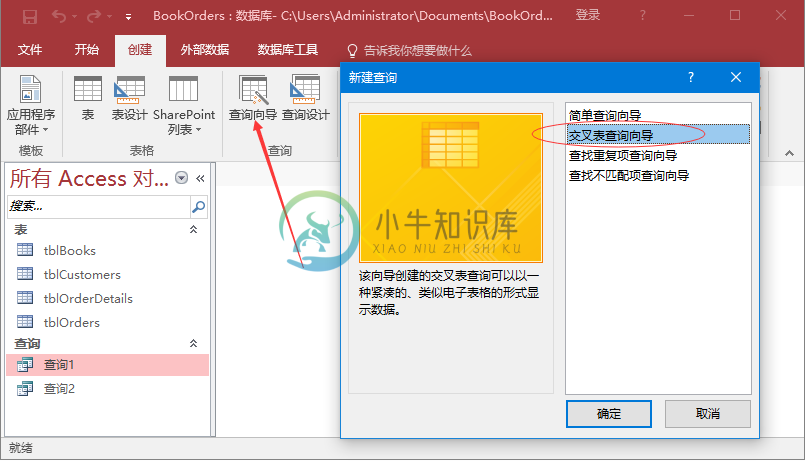 Access总结数据
Access总结数据如果您只是查找一个特定的数字,则聚合查询是非常好的,但是如果您想汇总信息(如电子表格式摘要),则可能需要考虑尝试交叉表查询。 如果要重构摘要数据以便于阅读和理解,请考虑使用交叉表查询。 交叉表查询是一种选择查询。 当您运行交叉表查询时,结果将显示在数据表中。 本数据表与其他类型的数据表有不同的结构。 如下面的截图所示,交叉表查询的结构可以使读取更容易,而不是显示相同数据的简单选择查询。 到目前为止