《数据结构》专题
-
基础的数据结构quicklist
主要内容:一、quicklist,二、源码分析,三、总结一、quicklist 再看一下quicklist,它是从Redis3.2才提供的一个数据结构。从字面意思上理解,这个应该比list快。但是同样是list,为什么它要快?就得找一下原因。在普通的list中,可以通过拥有的前向和后向指针进行前后的遍历和查找。但是,当数据量大时,这两个指针占用的空间就非常明显了。而在前面的ziplist中,可以看到,通过指示本Entry的长度配合相关标识,就可以去除这
-
 基础的数据结构ziplist
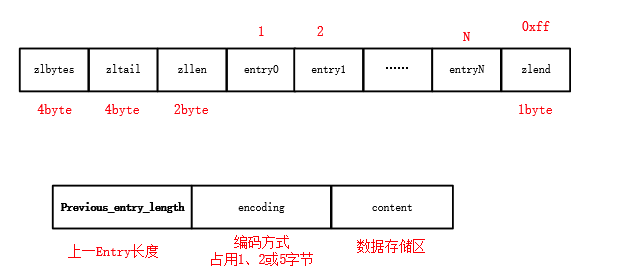
基础的数据结构ziplist主要内容:一、ziplist压缩列表,二、源码分析,三、总结一、ziplist压缩列表 压缩列表是HASH和跳表的小数据时的数据结构,这个在前面提到过。压缩列表的定义和使用其实在源码的头部说明中是很清楚的。看一下英文的注释: The ziplist is a specially encoded dually linked list that is designed to be very memory efficient. It stores both st
-
 基础的数据结构skiplist
基础的数据结构skiplist主要内容:一、skiplist 跳表,二、源码分析,三、总结一、skiplist 跳表 跳表这个数据结构是新生的,在学习数据结构的时候儿是没有这个的。当然,也可以理解成是对数据结构的进一步的封装,这样理解的话,可能就会更准确一些。为什么叫跳表?想想生活中跳的动作,一般人走路是一步一步的走,而如果跳跃的话,一下子可以走好几步,但是付出的代价就是要多费些力气。 其实跳表也是如此,正常的链表list,访问的时候儿是从头到尾(或者反过来)一条条的遍历,而跳表由于多
-
 基础的数据结构SDS
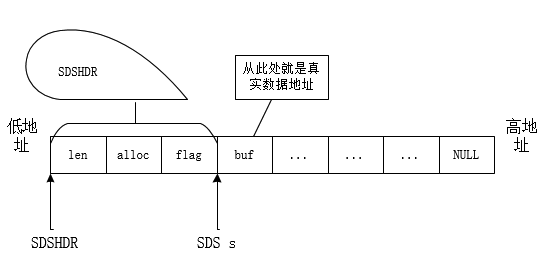
基础的数据结构SDS主要内容:一、SDS,二、源码分析,三、总结一、SDS 在前面的初步介绍中,知道Redis中的字符串是SDS——simple dynamic string,可能对于非c++人员有点不好理解,其实如果看STL的代码中std::string的实现,可能就会发现,其实有些类似,而且SDS相对简单不少。SDS除了可以实现字符串,其实还可以用来做缓冲区,毕竟char*的定义本身在C/C++中都是天然做为缓冲区的。 使用char*来操作字符串,但是底层
-
 C#常用数据结构和算法总结
C#常用数据结构和算法总结本文向大家介绍C#常用数据结构和算法总结,包括了C#常用数据结构和算法总结的使用技巧和注意事项,需要的朋友参考一下 1.数据 数据(Data)是外部世界信息的载体, 是能够被计算机识别,加工,存储的。在现实生活中也就是我们的产品原材料。 计算机中的数据包括数值数据,图片,影音资料等. 2. 数据元素和数据项 数据元素(Data Element)是数据的基本单位,在计算机处理的过程中通常
-
用于存储历史数据的数据库结构
问题内容: 前言:前几天,我在考虑为新应用程序使用新的数据库结构,并意识到我们需要一种有效地存储历史数据的方法。我想让其他人看一看,看看这种结构是否有任何问题。我意识到这种存储数据的方法很可能以前就已经发明了(我几乎可以肯定已经有了),但是我不知道它是否有名称,并且我尝试过的一些Google搜索都没有产生任何结果。 问题:假设您有一个订单表,并且订单与下订单的客户的客户表相关。在正常的数据库结构中
-
数据类型和数据结构之间的区别
本文向大家介绍数据类型和数据结构之间的区别,包括了数据类型和数据结构之间的区别的使用技巧和注意事项,需要的朋友参考一下 众所周知,编程完全围绕数据展开。数据是实现所有业务逻辑的基础,而数据流则是构成应用程序或项目功能的数据。因此,组织和存储数据以使其最优化使用并使用良好的数据模型进行有效编程就变得非常重要。 通常,数据类型和数据结构似乎都与处理数据的性质和组织相同,但是其中两个描述了数据的类型和性
-
详解 linux mysqldump 导出数据库、数据、表结构
本文向大家介绍详解 linux mysqldump 导出数据库、数据、表结构,包括了详解 linux mysqldump 导出数据库、数据、表结构的使用技巧和注意事项,需要的朋友参考一下 详解 linux mysqldump 导出数据库、数据、表结构 导出完整的数据库备份: 说明:--add-locks:导出过程中锁定表,完成后回解锁。-q:不缓冲查询,直接导出至标准输出 导出完整的数据库表结构
-
数据结构-链表2 存放点数据(x,y)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Document</title> </head> <body> <script> function Node(element){ this.element=element; this.next=null; } function Point(x,
-
第二章 云计算技术 - 1 结构化数据与非结构化数据
相对于结构化数据(即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据)而言,不方便用数据库二维逻辑表来表现的数据即称为非结构化数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。 非结构化数据库是指其字段长度可变,并且每个字段的记录又可以由可重复或不可重复的子字段构成的数据库,用它不仅可以处理结构化数据(如数字、符
-
数据结构中的ADT数组表示
本文向大家介绍数据结构中的ADT数组表示,包括了数据结构中的ADT数组表示的使用技巧和注意事项,需要的朋友参考一下 基本概念 ADT表示抽象数据类型。 数组被定义为ADT,因为它们能够以相同的顺序保存连续的元素。他们允许 通过索引或位置访问特定元素。 它们是抽象的,因为它们可以是String,int或Person 好处 快速随机访问项目或元素。 内存效率很高,除了存储内容所需的内存很少。 缺点 元
-
数据结构-队列2-基数排序
第一次按个位上的数字进行排序,第二次按十位上的数字进行排序 排序:91, 46, 85, 15, 92, 35, 31, 22 经过基数排序第一次扫描之后,数字被分配到如下盒子中: Bin 0: Bin 1: 91, 31 Bin 2: 92, 22 Bin 3: Bin 4: Bin 5: 85, 15, 35 Bin 6: 46 Bin 7: Bin 8: Bin 9: 根据盒子的顺序,对数字
-
数据库结构用Flyway/Liquibase,数据库插入用DBUnit?
我的应用程序有以下场景: 1个生产服务器 1个测试服务器 n开发计算机 对于数据库迁移,我们使用Hibernate Schema Update For the Schema和DBUnit来填充所有生产数据(在所有服务器/计算机上)。当模式更新完成后,我为新模式生成一个新的DTD文件,这样我就可以重新导入DBUnitXML。应用程序在启动时使用XML文件更新数据库(仅在开发和测试服务器/计算机上!)
-
Redis数据结构空间要求
问题内容: Redis中排序后的集合和列表之间的空间差异是什么?我的猜测是排序集是某种平衡的二叉树,而列表是链接列表。这意味着,在我为它们分别编码的三个值(键,分数,值)之上,尽管我将为链表的分数和值一起拼凑,但开销是链表需要跟踪一个其他节点,并且二叉树需要跟踪两个,因此使用排序集的空间开销为O(N)。 如果我的值和得分都为long,而指向其他节点的指针也为long,则在64位计算机上,单个节点的
-
Java中的持久数据结构
问题内容: 有没有人知道一个库或至少一些有关在Java中创建和使用持久性数据结构的研究?我不是将持久性称为长期存储,而是将持久性称为不变性(请参阅Wikipedia条目)。 我目前正在探索为持久性结构建模api的不同方法。使用构建器似乎是一个有趣的解决方案: 但这仍然感觉有些呆板。有任何想法吗? 问题答案: 我想显而易见的选择是: o切换到临时数据结构(构建器)进行更新。这是很正常的。用于操纵例如