《本周投递记录》专题
-
如何在Jupyter笔记本上打开csv文件?
我已经从Kaggle(视频游戏与评级)下载了一个数据库,但我不能用我的木星笔记本打开它。 我从这两行代码开始,但它给了我一个错误。。。 ()1中的UnicodeDecodeError回溯(最后一次调用)作为pd导入---- ~\Anaconda3\lib\site-包\熊猫\io\parsers.pyparser_f(filepath_or_buffer,sep,分隔符,标头,名称,index_c
-
使用Python和Selenium从span标记获取文本
我正在尝试使用Python和Selenium获取此元素。 这就是我所尝试的: 我做错了什么?
-
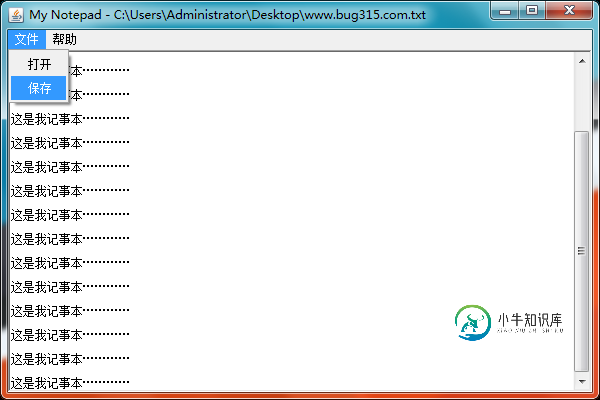 使用Java制作一个简单的记事本
使用Java制作一个简单的记事本本文向大家介绍使用Java制作一个简单的记事本,包括了使用Java制作一个简单的记事本的使用技巧和注意事项,需要的朋友参考一下 通过使用Java的Swing、IO来实现一个简单记事本,实现打开指定的text文本文件,然后将text文件的内容加载到Swing组件中,然后在Swing组件中编辑记事本内容,然后同菜单的保存选项将编辑后的内容保存到text文件中。代码如下: 效果图: 以上就是本文的全
-
 Java图形界面开发之简易记事本
Java图形界面开发之简易记事本本文向大家介绍Java图形界面开发之简易记事本,包括了Java图形界面开发之简易记事本的使用技巧和注意事项,需要的朋友参考一下 在学习了Java事件之后,自己写了一个极其简单的记事本。用到了MenuBar,Menu,MenuITem等控件,事件包括ActionListener以及KeyListener。 代码如下: 运行结果如图所示: 本程序实现的功能有: (1)可以打开某个文件,并且可以编辑。
-
在Python的ElementTree中的标记后提取文本
问题内容: 这是XML的一部分: 提取标签很容易。做就是了: 但是,如何立即获得文本( 猫的照片 )呢?执行以下操作将返回一个空白字符串: 问题答案: 元素具有属性-因此,您要求的不是。 或者,例如: 这也适用于普通的ElementTree:
-
 删除Ttk笔记本电脑的标签虚线
删除Ttk笔记本电脑的标签虚线问题内容: 我正在尝试制作看起来不像tkinter应用程序的tkinter应用程序。我使用的是ttk笔记本,并且在选中选项卡时,这些选项在文本的周围都有一点点虚线。它看起来很糟糕,我找不到使用样式或配置删除它的方法。这是要说明的屏幕截图: 编辑代码(我认为这不会有很大帮助,因为我实际上只是在尝试删除默认样式的东西。): 这是笔记本的创建: 填写: 相关样式: 问题答案: 您可以通过更改选项卡小部件
-
如何增加Jupyter笔记本的内存限制?
问题内容: 我在Windows 10上使用带Python3的jupyter笔记本。我的计算机具有8GB RAM,至少4GB RAM是可用的。 但是当我想使用以下命令制作大小为6000 * 6000的numpy ndArray时 : 我认为这不会使用超过100MB的RAM。我试图更改数字以查看发生了什么。我可以做的最大数组是(5000,5000)。在估计需要多少RAM时是否犯了错误? 问题答案: J
-
如何与非程序员共享Jupyter笔记本?
问题内容: 我试图用Jupyter做我不能做的事情。 我的内部服务器上运行着Jupyter服务器,可通过VPN和受密码保护的服务器进行访问。 我是唯一实际创建笔记本的人,但是我想以只读方式使其他团队成员可以看到一些笔记本。理想情况下,我可以与他们共享一个URL,当他们想查看带有刷新数据的笔记本时,他们将为其添加书签。 我看到了导出选项,但找不到任何有关“发布”或“公开”本地现场笔记本的信息。这不可
-
MySQL中的基本查询语句学习笔记
本文向大家介绍MySQL中的基本查询语句学习笔记,包括了MySQL中的基本查询语句学习笔记的使用技巧和注意事项,需要的朋友参考一下 1.基本查询语句 select 属性列表 from 表名和视图列表 [where 条件表达式1] [group by 属性名1 [having 条件表达式2]] [order by 属性名2 [asc|desc]] 2.单表查询 1)使用*查询所有字段 2) 查询指定
-
如何在Python中设置gamma值(jupyter笔记本)
当我运行这个代码时,我有一个警告。 !!! 警告如下!!! C:\Users#\Anaconda3\lib\site packages\sklearn\svm\base.py:193:futurearning: 如何避免这种警告?或者如何将gamma的值设置为缩放?
-
maven 2.2.1版本准备自定义标记格式
我工作场所的配置管理团队要求人工制品的4位版本号——比如,1.2.3.4——用于发布的人工制品,1.2.3.5-SNAPSHOT用于开发pom 除此之外,我们的版本管理系统(clearcase)具有预标签触发器,它强制执行标签/标签的特定命名约定。 因此,如果pom版本是1.2.3.4-SNAPSHOT,而artifactId是shopcart,那么根据标签命名要求,标签名称应该是: XXX\u
-
在IPython笔记本中自动运行%matplotlib内联
每次启动IPython笔记本时,我运行的第一个命令是 有没有办法改变我的配置文件,以便当我启动IPython时,它自动处于这种模式?
-
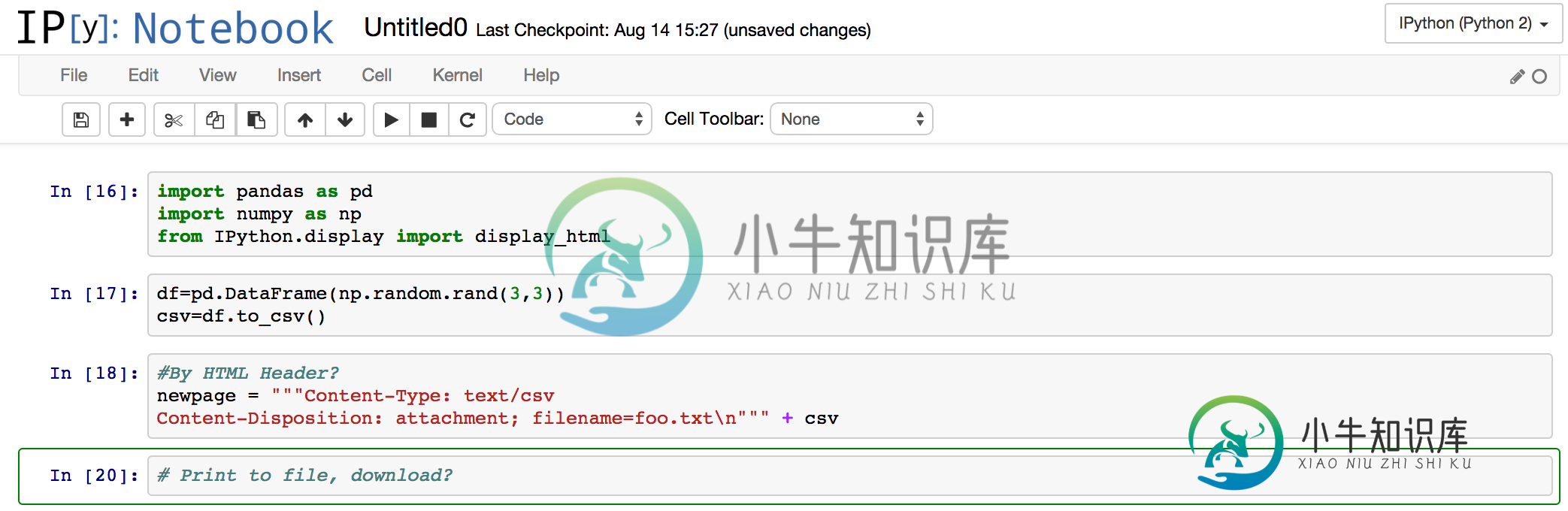 在iPython笔记本中下载触发器文件
在iPython笔记本中下载触发器文件给定一个在外部服务器上运行的iPython笔记本,是否有方法触发文件下载? 我希望笔记本能够将外部服务器上的文件下载到本地呈现笔记本的位置,或者从笔记本工作区执行直接字符串转储到文本文件中,本地下载。 一、 E.一个强大的工具是一个笔记本,它可以从数据库中查询、更改数据,并将查询结果下载为CSV文件。 一个快速的实验表明,包含以下内容的单元格会呈现一个下载文件的链接。我希望有一个比将数据呈现到ht
-
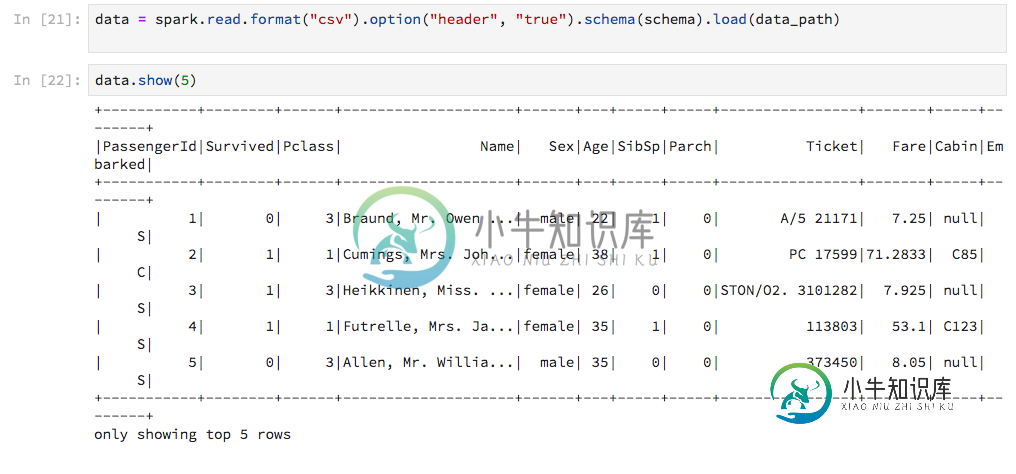 改进PySpark DataFrame.show输出以适合Jupyter笔记本
改进PySpark DataFrame.show输出以适合Jupyter笔记本在Jupyter笔记本中使用PySpark,Spark的的技术含量较低。我想“好吧,它很管用”,直到我得到这个: 输出未根据笔记本的宽度进行调整,因此线条以难看的方式缠绕。有没有办法定制这个?更好的是,有没有一种方法可以获得输出Pandas样式(显然不转换为)?
-
使用Python ElementTree提取XML标记中的文本
我有一个包含数万个XML文件(小文件)的语料库,我正在尝试使用Python并提取其中一个XML标记中包含的文本,例如,body标记之间的所有内容,例如: 然后编写一个包含此字符串的文本文档,然后向下移动XML文件列表。 我正在使用effbot的ELementTree,但找不到正确的命令/语法来做到这一点。我找到了一个使用迷你DOM的dom.getElementsByTagName的网站,但我不确定