《同花顺2024春招交流讨论》专题
-
Java中的同步代码输出顺序错误
我目前正在学习Java,我已经达到同步的主题。 由于某些原因,下面的代码(基于完全参考JAVA-赫伯特·席尔特第七版,第239-240页的代码)没有给出所需的输出。 代码: 所需输出: 实际输出(我在2013年底使用Macbook Pro上的Eclipse): 我已经读到,所有这些主题的输出都因计算机而异。 有人能解释一下为什么这行不通吗?
-
春云流兔子活页夹:向DLQ发送批量消息出错
我正在尝试用rabbit活页夹配置一个Spring-Cloud-Stream应用程序 下面是我的配置: 我的消费者java代码: 当没有错误发生时,所有工作正常。但当我模拟一个异常时,我得到了以下异常: 当兔子绑定器尝试将消息发送回 DLQ 时,会引发此错误。 事实上,错误消息有效负载包含一个 函数中使用< code>StreamBridge发送消息时,我也遇到了同样的问题。如果发送功能失败,我不
-
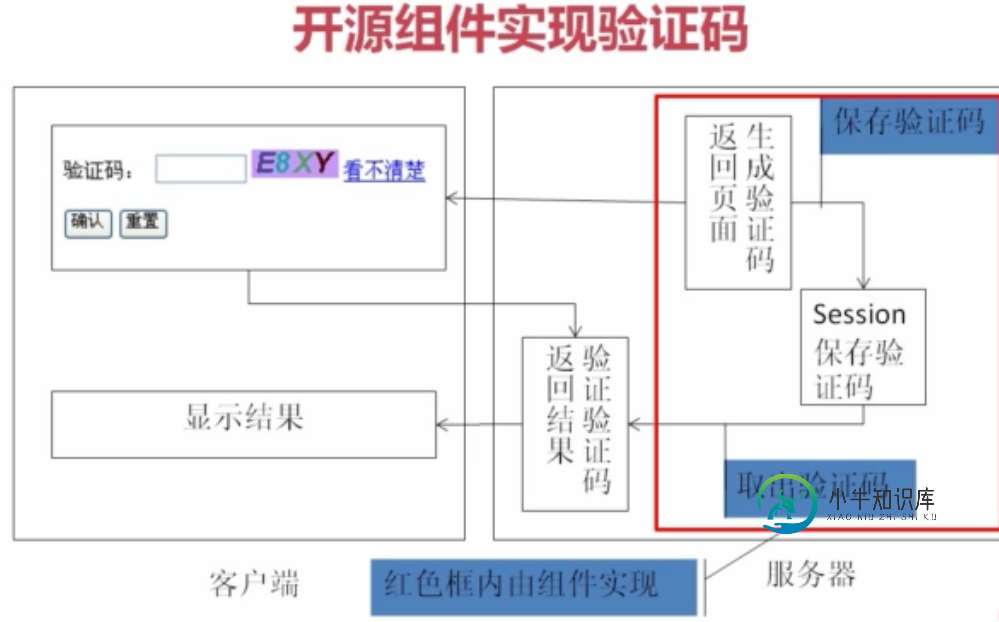 探讨Java验证码制作(下篇)
探讨Java验证码制作(下篇)本文向大家介绍探讨Java验证码制作(下篇),包括了探讨Java验证码制作(下篇)的使用技巧和注意事项,需要的朋友参考一下 接着上篇java验证码制作(上篇)给大家介绍有关java验证码的相关知识! 方法三: 用开源组件Jcaptcha实现,与Spring组合使用可产生多种形式的验证码,JCaptcha 即为Java版本的 CAPTCHA 项目,其是一个开源项目,支持生成图形和声音版的验证码,在生
-
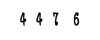 探讨Java验证码制作(上篇)
探讨Java验证码制作(上篇)本文向大家介绍探讨Java验证码制作(上篇),包括了探讨Java验证码制作(上篇)的使用技巧和注意事项,需要的朋友参考一下 相信大家对验证码这玩意不会陌生,无论是申请账号还是某些情况下登录时都会要求输入验证码。经过统计,验证码一次验证就成功通过的概率是90%,并不高,那么很多人对于这种降低用户体验度的设计肯定会怀疑他的必要性,但黑格尔说过:凡是合乎理性的东西都是现实的;凡是现实的东西都是合乎理性的
-
JavaScript中伪协议 javascript:使用探讨
本文向大家介绍JavaScript中伪协议 javascript:使用探讨,包括了JavaScript中伪协议 javascript:使用探讨的使用技巧和注意事项,需要的朋友参考一下 将javascript代码添加到客户端的方法是把它放置在伪协议说明符javascript:后的URL中。这个特殊的协议类型声明了URL的主体是任意的javascript代码,它由javascript的解释器运行。如果
-
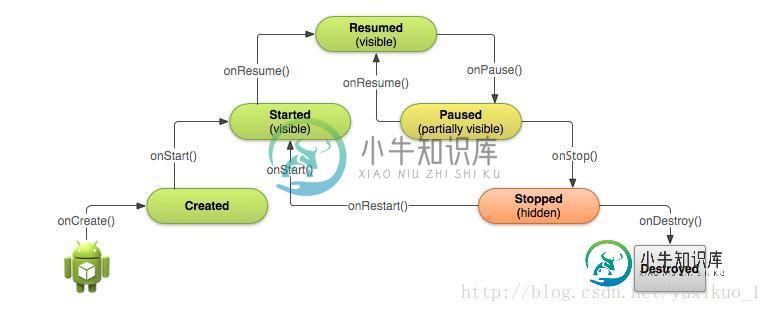 Android中Activity的生命周期探讨
Android中Activity的生命周期探讨本文向大家介绍Android中Activity的生命周期探讨,包括了Android中Activity的生命周期探讨的使用技巧和注意事项,需要的朋友参考一下 1、完整生命周期 上图是Android Activity的生命周期图,其中Resumed、Paused、Stopped状态是静态的,这三个状态下的Activity存在时间较长。 (1)Resumed:在此状态时,用户可以与Activity进行交
-
探讨Ajax中的一些小问题
本文向大家介绍探讨Ajax中的一些小问题,包括了探讨Ajax中的一些小问题的使用技巧和注意事项,需要的朋友参考一下 1.ajax跨域传递值是所需要的回传的类型为jsonp dataType 类型:String 预期服务器返回的数据类型。如果不指定,jQuery 将自动根据 HTTP 包 MIME 信息来智能判断,比如 XML MIME 类型就被识别为 XML。在 1.4 中,JSON 就会生成一个
-
Java 8-流,映射和计数不同
问题内容: 我第一次尝试使用Java 8流… 我有一个对象Bid,它表示用户对拍卖项目的出价。我有一个投标清单,我想制作一张地图,计算出用户投标的拍卖次数(不同)。 这是我的看法: 它有效,但是我感觉自己在作弊,因为我流式传输了地图的条目集,而不是在初始流上进行了操作……这一定是更正确的方法,但是我无法确定出来… 谢谢 问题答案: 您可以执行两次: 这样,您就可以确定每个用户在每次拍卖中有多少个出
-
访问相同的系统输入流
上面的代码片段目前不起作用,因为我猜每个类都有自己的输入流。我该怎么做呢?
-
使用Flink同步处理2个流
我有两个流A和B。 我开始同时吃A和B。 流A仅在每分钟的第59秒获得记录。 流B在每分钟的任何一秒都有记录。 我希望处理使两个流同步。 示例:在10:01:59之后从流A中,我将在10:02:59收到一条记录,直到10:02:59,我也不想从流B中读取任何内容。 这可以在Flink中实现吗?
-
按相同元素分组的Java流
我有一个单词流,我想根据相同元素的出现对它们进行排序。 例如:{hello,world,hello} 至 你好,{你好,你好} 谢谢你
-
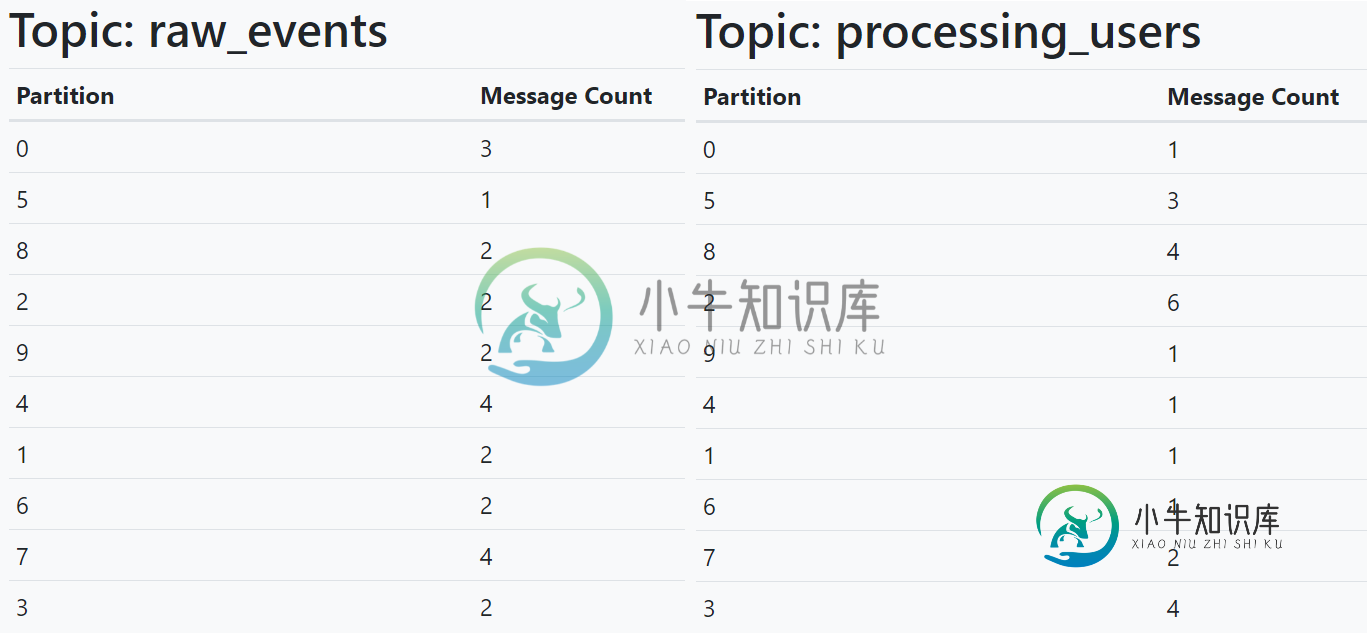 同键主题未能加入Kafka流
同键主题未能加入Kafka流我最近在一个streams应用程序中遇到了一个以前没有遇到过的问题,它很难跟踪与键控/连接相关的问题(以及更新后的分区问题)。 我有两个主题(raw_events和processed_users),这两个主题的密钥相同,但是当我试图对这两个主题执行连接时,尽管密钥相同,但只有一些连接是成功的。 为简洁起见,应用程序的基本工作流程如下: null 问题本身是在步骤5中产生的。由于主题和主题之间的连接
-
为什么在Java 8中按顺序收集并行流
问题内容: 为什么总是以随机顺序打印数字,而始终从原始顺序收集元素,即使是从并行流中呢? 输出: 问题答案: 这里有两种不同的“排序”,使讨论变得混乱。 一种是 遇到顺序 ,该 顺序 在流文档中定义。考虑这一点的一种好方法是源集合中元素的 空间 顺序或 从左到右的 顺序。如果源是,请考虑将较早的元素放在较后的元素的左侧。 还有文档中未定义的 处理 或 时间 顺序,但这是由不同线程处理元素的时间顺序
-
流星订阅不会更新集合的排序顺序
问题内容: 当我做… 邮政文档被添加并显示在列表的末尾,与我的发布功能中指定的降序相反。关于我在做什么错的任何想法吗? 谢谢! 问题答案: 发布功能确定哪些记录应同步到任何订阅客户端的mini- mongo数据库。因此,使用publish函数对数据进行排序实际上对客户端没有影响,因为客户端数据库可能会以其他方式存储它们。 当然,您可能希望在发布者的目录中使用sort,以将记录数限制为最近的N条-
-
AWS Lambda是否严格按顺序处理DynamoDB流事件?
我正在编写一个Lambda函数,用于处理DynamoDB流中的项。 我认为Lambda背后的部分观点是,如果我有一个大的事件突发,它将启动足够多的实例来同时通过它们,而不是通过单个实例顺序地提供它们。只要两个事件具有不同的键,我就可以不按顺序处理它们。 然而,我刚刚阅读了关于了解重试行为的这一页,上面说: 对于基于流的事件源(Amazon Kinesis Data Streams和DynamoDB