《2024毕业生求职有问必答》专题
-
HTTP 请求支持的方法有哪些?
本文向大家介绍HTTP 请求支持的方法有哪些?相关面试题,主要包含被问及HTTP 请求支持的方法有哪些?时的应答技巧和注意事项,需要的朋友参考一下 参考回答:
-
Laravel将所有请求重定向到HTTPS
我们的整个网站将通过https提供服务。我在每条路线上都有“https”。但是,如果他们试图通过http将其重定向到https,我该如何将其重定向到https?
-
DASH mpd向所有请求添加http头
我正在编写一个mdp文件,并且我正在寻找一种方法来指定(或修改)客户端为特定演示文稿所做的所有请求的HTTP标头。我想在超文本传输协议请求中添加一个授权字段。我希望在不编辑客户端sw的情况下这样做。 我已经阅读了ISO/IEC 23009-1,但我没有发现任何关于它的信息。有人知道怎么做吗?
-
Apache Beam Java 2.26.0:BigQueryIO“请求中没有行”
自从Beam更新后,我们在Java SDK流数据管道中遇到了错误。我们已经调查这个问题很长时间了,但无法找到根本原因。当降级到时,管道按预期工作。 BigQuery的DATETIME类型现在映射到Beam逻辑类型org.apache.Beam.sdk.schemas.logicaltypes.sqltypes.DATETIME Java BigQuery流插入现在默认情况下启用了超时。传递以恢复到
-
 邮递员:带有附件的SOAP请求
邮递员:带有附件的SOAP请求如何在Postman中将附件添加到SOAP请求中? 我有以下设置,并且在“原始”文本框中有我的SOAP xml。 (我可以在SoapUI中做到这一点,但想使用Postman。)
-
Android凌空双帖时有慢的要求
我在慢速网络上的Volley POST请求有问题。每次我在我的LogCat中看到BasicNetwork.logSlow请求,我的POST请求都会执行两次或更多次,导致1个请求的多次(2次或更多)发布。我已经将重试策略设置为0,但它没有帮助。 这是我的LogCat 截击(5984):[19807]基本网络。logSlowRequests:请求的HTTP响应= 这是我的密码 请帮助,我拼命寻找解决这
-
带有https请求多线程Spring的JPA
我正在使用spring 和< code>HTTP post请求,逐行获取数据,然后将数据发送到API的HTTP请求中,这对我来说很好,但这里我使用的是大量数据,所以我必须使用多线程,但我是java和spring的新手,我如何实现使用10个线程,每个线程每次并行读取1k的数据? 我读过关于10个线程的多线程,其中每个线程每次读取1k行,我的数据库中有大约1000万条记录 访问DataJpaAppli
-
带有ajax请求的CORS错误[重复]
我正在用ajax执行这个请求,但是关于CORS我仍然有以下错误:XMLHttpRequest不能加载https://cubber.zendesk.com/api/v2/organizations/37520251/users.json。在飞行前响应中,Access-Control-Allog-Headers不允许请求头字段Access-Control-Allog-Origin。你能帮我pls吗?我
-
通过改装取消所有请求2
我使用youtube API制作了一个应用程序。首先,我使用< code > retrieve 加载视频列表,然后我继续使用< code > retrieve 加载列表中视频的所有信息。 由于<code>列表视图<code>支持刷新和加载更多,我需要<code>取消<code>所有调用请求。 我知道调用了<code>cancel()cancel()。 还有更好的解决方案吗?
-
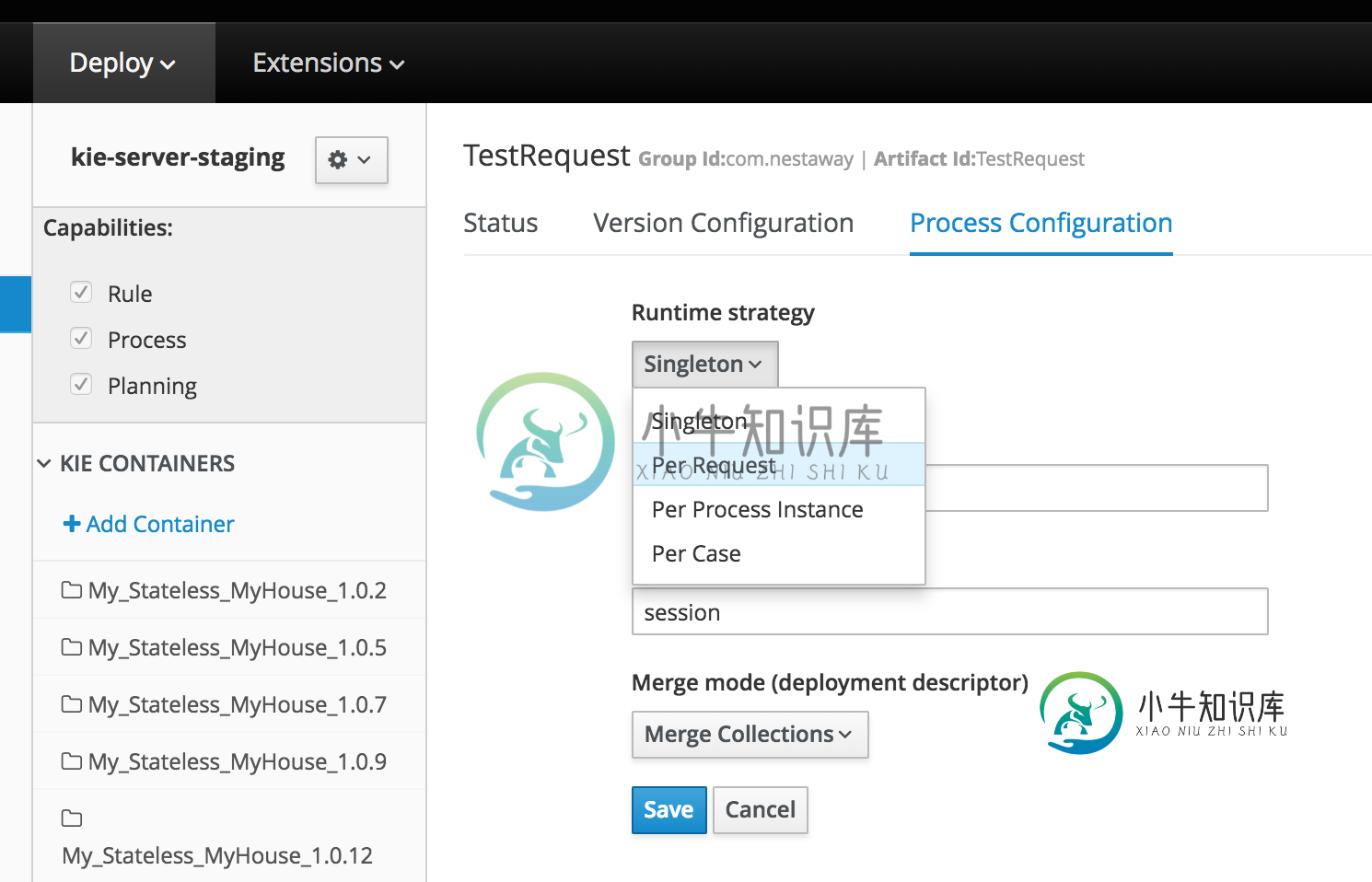 每个请求的Drools有状态会话
每个请求的Drools有状态会话我们正在尝试使用Drool作为我们的规则引擎服务。我们到目前为止所做的如下 部署的工作台7.2.final 已部署的KIE服务器7.2.0。final 配置了一些数据对象、规则,将更改部署到KIE服务器,我们可以使用rest API执行规则 无状态会话满足了我们的大部分需求(给出一组数据,执行规则并返回数据,仅此而已)。但是使用无状态时,我们必须牺牲Drools有状态会话提供的许多重要特性。 我们
-
Python常见问题解答:“异常有多快?”
问题内容: 我只是在查看Python FAQ,因为它是另一个问题中提到的。以前从未真正详细地研究过它,我遇到了一个问题:“例外情况有多快?”: try / except块非常有效。实际上捕获异常是昂贵的。在2.0之前的Python版本中,通常使用以下习惯用法: 我对 “捕获异常代价高昂”这一 部分感到有些惊讶。这是否仅是指您实际上将异常保存在变量中的情况,或者通常是所有s(包括上面示例中的一个)的
-
由于未找到带有URI警告的HTTP请求的映射而导致的CSS问题
每当我向RequestMapping路径添加任何内容时,我都有一个问题,那就是解析CSS文件的路径。在下面的示例中,如果更改
-
跨多个作业聚合Hadoop作业计数器
Hadoop:(ver-1.2.1),(1+8节点集群) 我的用例是,我试图获得执行特定pig脚本所花费的时间,以及从mapreduce的角度来看,这些时间是如何花费的。我需要多次运行pig脚本(比如说100),以获得平均时间。我启用了,这使我在每个udf函数上花费时间作为mapreduce计数器。我还对每个作业报告的其他延迟、内存度量(cpu时间、堆使用率)感兴趣。我可以从jobtracker
-
最小瓶颈生成树与最小生成树有何不同?
赋权图G的最小瓶颈生成树是G的生成树,使得生成树中任何边的最大权值最小。MBST不一定是MST(最小生成树)。 请举例说明这些说法有意义的地方。
-
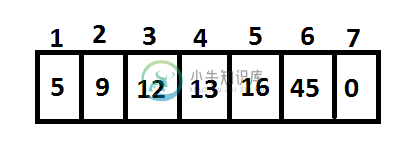 我们必须创建一个所有节点都有3个子节点的树吗?
我们必须创建一个所有节点都有3个子节点的树吗?构建哈夫曼树的步骤输入是唯一字符的数组及其出现频率,输出是哈夫曼树。 > 为每个唯一字符创建一个叶节点,并构建所有叶节点的最小堆(最小堆用作优先级队列。频率字段的值用于比较最小堆中的两个节点。最初,最不频繁的字符位于根) 从最小堆中以最小频率提取两个节点。 创建一个新的内部节点,其频率等于两个节点频率之和。将第一个提取的节点作为其左子节点,将另一个提取的节点作为其右子节点。将此节点添加到最小堆。