《机器学习算法面试》专题
-
 美团机器学习面经
美团机器学习面经美团笔试4道a了3,面完挂了一次被捞起来,然后面了两轮因为不太匹配又被丢回人才库了,今天又通知被捞了起来…… 记录一下前两轮面试吧,希望这次被捞能有好结果 优选一面(1h 凉) 一直问项目,目标检测的,数据集、模型…… 问图生图的,评价指标,模型结构 以上问了四十多分钟 写题:LeetCode 152. 乘积最大子数组 题不难,脑抽了,初始化一直有问题(你这个方法应该没啥问题,过不了的话你回去再调
-
 快手机器学习 一面
快手机器学习 一面自我介绍 介绍项目 介绍实习,面试官问的内容和ML的关系不太大,可能是和部门的工作比较契合所以就没为难我。 面试官向我介绍部门的工作内容,了解到和我目前实习工作相关性较强。 手撕:比较版本号 反问,因为投的是深圳+北京,所以问了一下base地。
-
 腾讯机器学习面经
腾讯机器学习面经冬招的第一个offer 一面 先拷打项目 然后手撕多头注意力机制和一道算法题:lcr08长度最小子数组 然后问了一些八股 linux如何查看某个文件有多少行 linux如何查看某个文件的第几列 git回滚的指令 合并分支的指令 弹一弹熟悉的激活函数和优缺点 fasterrcnn的优化 yolov5v8的优化 为什么业内yolov5用的比较多而不是yolov8 多头注意力机制和单头相比有什么优势 正
-
 小米机器学习面经
小米机器学习面经一面 自我介绍 结合项目描述RNN、LSTM结构,描述模型改进原理 残差连接的优势 梯度消失问题——对比深度网络的梯度消失和循环网络的梯度消失 数据不平衡问题原因与解决措施 性能指标F1分数的计算方式 DDQN项目的环境介绍与网络模型 深度学习和强化学习的关联 Adam优化器的原理,SGD的原理 手撕: 最长有效的括号字符子序列(返回所有最长的子序列)(10分钟) 反问: 1分钟 emmm手撕ha
-
 美的机器学习群面
美的机器学习群面遇到了全是技术岗的群面,一起讨论怎么ai技术加入产品 总结:一定要读题!!!针对题来每点说自己的想法,最好把自我介绍压缩一下,组里好几个人没有说完就被下一个了,而且顺序不是按照公众号的个人编号。 读题5min,自我介绍➕想法1.5min,讨论20min,总结5min 就算没有抢到主持人,中途理清团队的思路也很重要!!!我的组两个技术大佬一直不统一。。。导致其他人也没有发表什么明确的想法和意见,我发
-
 高德机器学习一面
高德机器学习一面时长70分钟左右,主要在问项目,其他八股挺常规的 八股: transfromers和RNN, LSTM的区别 解释一下梯度爆炸和解决方法 BN和LN的区别 讲讲了解的激活函数 怎么识别 / 解决过拟合问题 XGBoost和随机森林的区别 算法题: 最长公共子串 面完第二天秒挂,可能是笔试做得太烂了
-
 快手 机器学习 一面
快手 机器学习 一面今天下午面了快手的机器学习,部门是做搜广推的,面试官小哥哥介绍了一下部门情况,看到我是做图像的,感觉有点不太匹配,然后问我愿不愿意面试,我当然愿意了 时长:50min 1.自我介绍2分钟 2.介绍一下自己的项目,面试小哥不太懂我的这个项目,这里讲了比较多 3.二分类问题常用的评估指标?其中提到了召回率,出了个场景题说一下怎么计算 4.AUC怎么计算? 5.AUC接近1可能的原因是什么? 6.手撕:
-
 小米机器学习二面
小米机器学习二面自我介绍,三道编程题(二叉树和图,a了两道),项目深挖
-
第七章 机器学习 - 7.1 K 近邻算法
1.1、什么是K近邻算法 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1时,算法便成了最近邻算法,即寻找最近的那个邻居。为何要找邻居?打个比方来说,假设你来到一个陌生的村庄,现在你要找到与你有着相似特征的人群融入他们,所谓入伙。 用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的
-
 机器学习和深度学习
机器学习和深度学习主要内容:机器学习,深度学习,机器学习与深度学习的区别,机器学习和深度学习的应用人工智能是近几年来最流行的趋势之一。机器学习和深度学习构成了人工智能。下面显示的维恩图解释了机器学习和深度学习的关系 - 机器学习 机器学习是让计算机按照设计和编程的算法行事的科学艺术。许多研究人员认为机器学习是实现人类AI的最佳方式。机器学习包括以下类型的模式 - 监督学习模式 无监督学习模式 深度学习 深度学习是机器学习的一个子领域,其中有关算法的灵感来自大脑的结构和功能,称为人工神经网络。
-
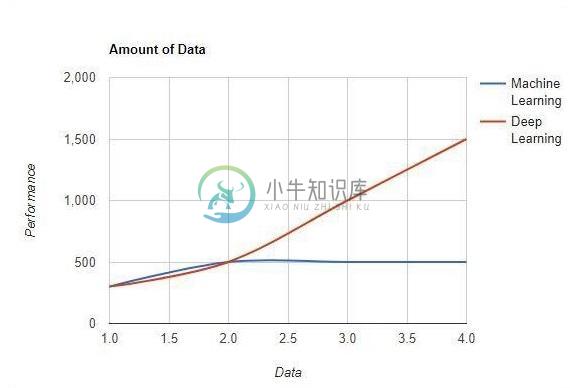
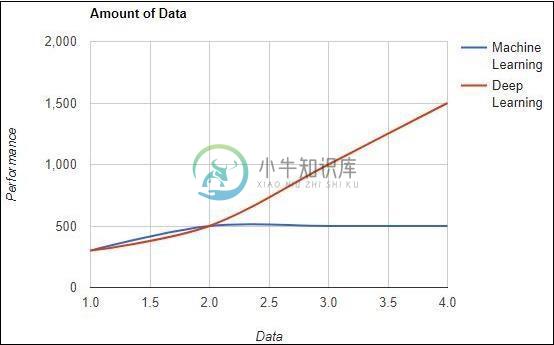 机器学习与深度学习
机器学习与深度学习主要内容:数据量,硬件依赖,特色工程在本章中,我们将讨论机器和深度学习概念之间的主要区别。 数据量 机器学习使用不同数量的数据,主要用于少量数据。另一方面,如果数据量迅速增加,深度学习可以有效地工作。下图描绘了机器学习和深度学习在数据量方面的工作 - 硬件依赖 与传统的机器学习算法相反,深度学习算法设计为在很大程度上依赖于高端机器。深度学习算法执行大量矩阵乘法运算,这需要巨大的硬件支持。 特色工程 特征工程是将领域知识放入指定特征的
-
Azure机器学习
我已经找了几个小时了,但找不到一个能回答这个问题的东西。我已经创建并发布了一个新的Azure机器学习服务,并创建了一个endpoint。我可以使用Postman REST客户机调用服务,但是通过JavaScript网页访问它会返回一个控制台日志,说明该服务启用了CORS。现在,对于我来说,我想不出如何为Azure机器学习服务禁用CORS。如有任何帮助,不胜感激,谢谢!
-
8. 机器学习
@subpage tutorial_py_knn_index_cn 学习使用kNN分类器。 同时学习编写一个基于kNN的手写字符识别程序。 @subpage tutorial_py_svm_index_cn 理解SVM的概念。 @subpage tutorial_py_kmeans_index_cn 学习使用K-Means聚类将数据分组到多个集合中。 另外我们会学习使用K-Means聚类进行颜色量
-
 AiLearning 机器学习
AiLearning 机器学习机器学习(Machine Learning,ML) 是使用计算机来彰显数据背后的真实含义,它为了把无序的数据转换成有用的信息。是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。 源代码:https://www.wenjiangs.com/wp-content/uploads/2022/09/src.zip
-
 Python 机器学习
Python 机器学习机器学习是一门研究如何使用计算机模拟人类行为,以获取新的知识与技能的学科。它是人工智能的核心,同时也是处理大数据的关键技术之一。机器学习的主要目标是自动地从数据中发现价值的模式,亦即将原始信息自动转换为人们可以加以利用的知识。