《HPC高性能计算工程师》专题
-
第 22 章 高可用性模式
注意 The High Availability features are only available in the Neo4j Enterprise Edition. Neo4j High Availability or “Neo4j HA” provides the following two main features: 1.It enables a fault-tolerant data
-
如何编写可以用Java计算能力的函数。无循环
问题内容: 我一直在尝试用Java编写一个简单的函数,该函数可以不使用循环就可以计算出n次方的数字。 然后,我发现 Math.pow(a,b) 类…或方法仍然无法区分两者,理论上不太好。所以我写了这个 然后,我想制作自己的 Math.pow 而不使用循环,我希望它看起来比循环更简单,就像使用某种类型的 Repeat一样, 我做了很多研究,直到遇到遇到使用 StringUtils.repeat 的
-
PHP常用函数之根据生日计算年龄功能示例
本文向大家介绍PHP常用函数之根据生日计算年龄功能示例,包括了PHP常用函数之根据生日计算年龄功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP常用函数之根据生日计算年龄功能。分享给大家供大家参考,具体如下: 运行结果: 31 PS:这里再为大家推荐几款时间及日期相关工具供大家参考: 在线日期/天数计算器: http://tools.jb51.net/jisuanqi/date
-
计算C ++中给定周长可能的直角三角形数量
本文向大家介绍计算C ++中给定周长可能的直角三角形数量,包括了计算C ++中给定周长可能的直角三角形数量的使用技巧和注意事项,需要的朋友参考一下 给定三角形的周长P。周长是三角形所有边的总和。目的是找到可以制造的具有相同周长的直角三角形的数量。 如果三角形的边是a,b和c。然后a + b + c = P和a2 + b2 = c2(a,b和c的任意组合的毕达哥拉斯定理) 我们将通过从1到p / 2
-
如何计算游戏中的可能成功率:x随机(12)=>y
我正在尝试编写一行Ruby代码,用于计算文本冒险游戏中简单技能测试的可能成功率。测试是“如果x随机(12)= 在游戏中,玩家有一定的技能,并且偶尔必须测试这些技能加上一个随机数才能获得大于或等于给定难度的数字。我想计算能够赢得该技能测试的成功率百分比。 作为冒险游戏的一个例子,你试图在丛林中追踪一些动物。要做到这一点,你必须测试你的跟踪技能。例如,如果你的追踪技能为3,并且你在1-12之间添加了一
-
新的BigInteger(String)性能/复杂性
问题内容: 我想知道使用 构造函数构造BigInteger* 对象的性能/ 复杂性 。 * 请考虑以下方法: 此方法在开头创建带有数字的String对象,并且每次迭代都会增加它的数量。它测量并输出构造相应对象所需的时间。 在我的机器(Intel Core i5 660,JDK 6 Update 25 32位)上,输出为: 尽管忽略了高达10 ^ 5的行(由于(处理器)缓存效果,JIT编译等可能引入
-
性能 & 优化 - 数据本地性
Spark 是一个并行数据处理框架,这意味着任务应该在离数据尽可能近的地方执行(既 最少的数据传输)。 检查本地性 检查任务是否在本地运行的最好方式是在 Spark UI 上查看 stage 信息,注意下面截图中的 "Locality Level" 列显示任务运行在哪个地方。 调整本地性配置 你可以调整 Spark 在每个数据本地性阶段(data local --> process local -
-
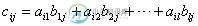 C语言科学计算入门之矩阵乘法的相关计算
C语言科学计算入门之矩阵乘法的相关计算本文向大家介绍C语言科学计算入门之矩阵乘法的相关计算,包括了C语言科学计算入门之矩阵乘法的相关计算的使用技巧和注意事项,需要的朋友参考一下 1.矩阵相乘 矩阵相乘应满足的条件: (1) 矩阵A的列数必须等于矩阵B的行数,矩阵A与矩阵B才能相乘; (2) 矩阵C的行数等于矩阵A的行数,矩阵C的列数等于矩阵B的列数; (3) 矩阵C中第i行第j列的元素等于矩阵A的第i行元素与矩阵B的第j列元素对应乘积
-
第1章 简介异构计算 - 1.8 使用OpenCL进行异构计算
读者们应该对并行原理和异构计算的背景有了一定的了解,下面我们来看看哪些特性在OpenCL中得到了支持。这里我们也来简单的回顾一下OpenCL的历史。 OpenCL是一个异构编程架构,其管理者是非盈利技术组织Khronos Group[3]。OpenCL是一个应用开发框架,在其框架下开发的应用,能够在不同的硬件供应商的设备上运行。第一版的OpenCL(1.0)标准在2008年正式发布,并出现在苹果M
-
【深入理解计算机系统】第 1 章:计算机系统漫游
编译系统的四个阶段 预处理:将头文件的内容直接插入到文本 编译:源码到汇编 汇编:汇编指令到机器指令,这时得到的可重定位目标程序还无法执行 链接:将标准库函数所在的预编译文件合入到上一步的程序中,得到最终的可执行文件 系统硬件组成 32 位、64 位也是计算机总线依次传递的字的大小 控制器和适配器:控制器存在硬件上,硬件直接与 I/O 总线相连,在主板内部;适配器:不在主机内部而是通过扩展槽相连到
-
 Linux面试题(调试篇)网络性能工具有哪些?
Linux面试题(调试篇)网络性能工具有哪些?沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇章一起了解下网络性能工具。 一、网络性能指标 二、netstat 三、route 四、iptables 一、网络性能指标 从网络性能指标出发,你更容易把性能工具同系统工作原理关联起来,对性能问题有宏观的认识和把握。这样,当你想查看某个性能指标时,就能清楚知道,可以用哪些工具。 二、netstat Netstat是一个用于检查各种网络相关信息
-
如何使用Python的timeit计时代码段以测试性能?
问题内容: 我有一个Python脚本,该脚本可以正常工作,但是我需要编写执行时间。我已经用谷歌搜索了,但是我似乎无法使它正常工作。 我的Python脚本如下所示: 我需要的是执行查询并将其写入文件所需的时间。目的是使用不同的索引和调整机制来测试数据库的更新语句。 问题答案: 您可以在要计时的块之前或之后使用或。 此方法不完全精确(它不会平均运行几次),但是很简单。 (在Windows和Linux中
-
为什么我的反向传播算法的性能会停滞?
我正在学习如何编写神经网络,目前我正在研究一种具有一个输入层、一个隐藏层和一个输出层的反向传播算法。算法正在运行,当我抛出一些测试数据时 在我的算法中,使用3个隐藏单元的默认值和10e-4的默认学习率, 我得到了很好的结果: 每次平方误差之和都会像我预期的那样下降一个十进制。然而,当我使用这样的测试数据时 没有什么真正的改变。我检查了我的隐藏单位、梯度和权重矩阵,它们都不同,梯度确实在缩小,就像我
-
Bellman-Ford算法的正确性,我们还能做得更好吗?
我了解到Bellman-Ford算法的运行时间为O(| E |*| V |),其中E是边的数量,V是顶点的数量。假设图没有任何负加权圈。 我的第一个问题是,我们如何证明在(| V |-1)迭代中(每次迭代检查E中的每条边),它更新到每个可能节点的最短路径,给定一个特定的起始节点?有没有可能我们已经迭代了(|V |-1)次,但仍然没有得到到每个节点的最短路径? 假设算法正确,我们真的能做得更好吗?我
-
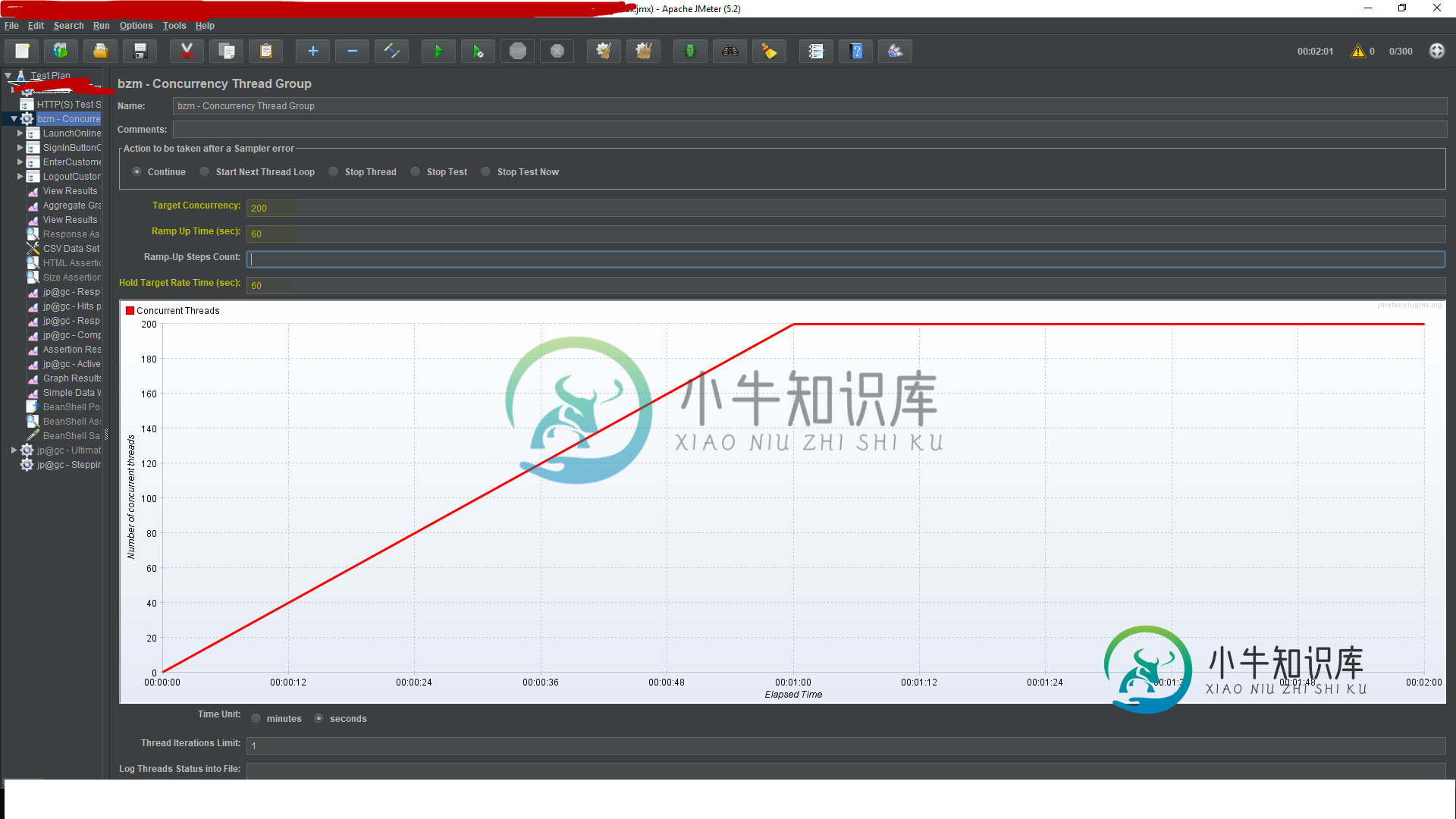 并发线程和最终线程组及性能基准标记
并发线程和最终线程组及性能基准标记在理解并发线程和最终线程组的概念时,我对运行并发线程或最终线程组时的汇总/聚合报告结果的理解感到困惑,例如,如果我有200个用户,上升时间为60秒,那么在成功完成执行后,我并没有看到所有的采样请求都是200个样本,而只有少数采样请求有200个样本。当我使用普通线程组时,每次采样请求完成后,我总是得到相同的线程数。 对于更多用户的实际负载测试,您能否建议我应该选择哪一个线程组。 您是否可以提供一些有