《HPC高性能计算工程师》专题
-
 摩尔线程 AI高性能计算
摩尔线程 AI高性能计算1、自我介绍 2、项目介绍 3、主要做了什么,为什么这样做 4、模型结构 5、与原算法比较,优势和不足 6、在学校有没有学过机器学习深度学习相关课程 7、滤波器(不会) 8、怎样部署(不会) 9、评价指标 10、倾向于做什么方向 11、线性回归与逻辑回归 12、朴素贝叶斯 13、代码题:单位园随机采样 #摩尔线程##摩尔线程智能科技(北京)有限责任公司#
-
 小米高性能计算
小米高性能计算👥面试题目 一面 项目 cuda详细说(好久了有的忘记了说的磕磕巴巴的) 然后 讲了实习的东西 感觉和他们目前的业务比较match 基础问题 c加加和cuda的基础问题 一个膨胀卷积实现的手撕 呃问我怎么优化 没回答出来 给我讲解了我还是没明白 笑死 面试官无语 反问 两轮技术面 技术业务偏向移动端硬件优化这边 面试官比较友好 亲切 没开摄像头 希望可以进二面 跪求
-
 旷视2023提前批高性能计算工程师一面
旷视2023提前批高性能计算工程师一面前面大部分时间在聊项目,一共大概五十分钟 自动微分的流程、怎么写? 你用的动态图还是静态图? 动态图和静态图的优势劣势? 框架中用了什么技巧了吗? 怎么加入分支?(不知道,就让我说CPU中的分支预测了,说完补充了一些GPU中的分支) Cache的层次结构?如何高效利用cache(讲了集中优化方法,更换访存策略,tiling等) 讲一下roofline model?你有没有用roofline分析过什
-
 好未来 - HPC 算法工程师 - 二面
好未来 - HPC 算法工程师 - 二面自我介绍。学习过程。 CUDA 基本知识。 CUDA 基本术语。 CUDA 学习书籍。 CUDA 编程 IDE 使用,CUDA debug 怎么做。 CUDA graph 了解不。并不,所以不继续问下去了。 用 CUDA 对数组排序。答用奇偶变换排序,但觉得20分钟写不出来,遂放弃。 三个方向,对哪个方向感兴趣。单机单卡算法机器学习算法移植;多级多卡大模型(类ChatGpt)移植;多机多卡计算机视
-
用于高性能计算的C++类
最简单的经验法则之一是记住硬件喜欢数组,并且针对数组的迭代进行了高度优化。对许多问题的一个简单优化只是停止使用花哨的数据结构,只使用简单的数组(或C++中的std::vectors)。这需要一些时间来适应。 C++类是那种“奇特的数据结构”,即一种可以用数组代替的数据类型,以在C++程序中获得更高的性能吗?
-
 蔚来 高性能计算 1 2 3面
蔚来 高性能计算 1 2 3面【名称】蔚来高性能计算日常实习 1 2 3面 【时间】23.07 【公司】蔚来 【岗位】高性能计算 【面经】个人 一面: 1. 自我介绍 2. 深挖实习 3. 你用过TensorRT 讲讲对 TensorRT的理解 4. 讲讲TensorRT 和 OpenVINO的区别 C++ 八股: 5. C++面向对象特性 面向对象特性分别如何体现的 6. 讲一下继承 7. 讲一下虚函数 8. 讲一下vect
-
7. 计算性能
校验者: @曲晓峰 @小瑶 翻译者: @小瑶 对于某些 applications (应用),estimators(估计器)的性能(主要是 prediction time (预测时间)的 latency (延迟)和 throughput (吞吐量))至关重要。考虑 training throughput (训练吞吐量)也可能是有意义的,但是在 production setup (生产设置)(通常在脱
-
云计算工程师技能图谱
运维 DevOps 持续交付 持续集成 部署 蓝绿部署 灰度发布 金丝雀发布 Canary 部署 PHOENIX 部署 AWS CloudFormation 配置 Chef Puppet Ansible AWS OpsWorks 开发 流程 Scrum Crystal FDD 语言 Java Python Go JavaScript PHP Ruby Clojure Julia 架构 分布式消息
-
AnyLogic:提高网络模型的计算性能
我正在研究一个基于代理的流行病模型。这个想法是单个代理根据他们在网络中观察到的情况(基于距离)做出决定。我在每个代理中都有几个功能,可以动态更新受感染接触者的数量,接触者表现出特定行为等。 下面的代码用于计算代理网络中受感染的联系人。 至少还有3个这样的函数可以保持表示代理网络中其他功能的其他代理的计数。现在,当我 有没有一种计算效率更高的方法来跟踪更大人口的网络统计数据?
-
 百度提前批高性能计算 一面
百度提前批高性能计算 一面投的上海的高性能计算被挂了,被北京的高性能计算的语音技术部捞了 百度面试官非常好,体验感非常棒,奈何自己太菜了,全程道歉 一面 8.2 项目深挖 算子开发相关涉及知识点 GPU架构,内存模型 并发编程 锁 信号量 创建线程的几种方式 lambda表达式的底层是怎么实现的 std::move 使用场景,他比赋值构造好在哪 lock_guard相比较于lock/unlock能防止什么问题? cuda
-
 原粒半导体 - AI 高性能算子工程师 - 技术面
原粒半导体 - AI 高性能算子工程师 - 技术面1. 介绍项目。巴拉巴拉... 2. 说说 Reduction 算子调优实现策略;Conv 呢,是滑窗实现的还是怎么;其它的算子知道吗,比如 Softmax,Droupot。 - Reduction。巴拉巴拉... - Conv 按滑窗策略实现。还有 img2col 方式,不过我没看过源码。 - Gemm、Transpose,其它不了解,只知道有通用现成的解决方案,没时间学。 3. C++ 重载;
-
 百度提前批(直接开始二战) 高性能计算工程师一面面经
百度提前批(直接开始二战) 高性能计算工程师一面面经没想到吧兄弟们,直接开始二战了。捞了我就面呗~这回面的挺爽的。 点名表扬语音部门,面试至少感觉respect。 八股/经历 自我介绍:懂得都懂,开源+实习 讲了讲在字节的实习工作:大模型训练模拟器 根据这个他问了我TP PP DP都是什么,具体流程 如何根据TP PP的通信量进行取舍 问了量化相关,什么是per tensor,per channel,group wise 不同的量化方法之间的区别,
-
 Kafka高性能设计-3
Kafka高性能设计-3主要内容:1.消费消息的性能优化手段,2.消费者组1.消费消息的性能优化手段 1.1 稀疏索引 Kafka 利用offset 和 timestamp 查到消息。 B Tree 类的索引并不适用于 Kafka。哈希索引看起来却非常合适。 为了加快读操作,如果只需要在内存中维护一个「从 offset 到日志文件偏移量」的映射关系即可,每次根据 offset 查找消息时,从哈希表中得到偏移量,再去读文件即可。(根据 timestamp 查消息也可以采用
-
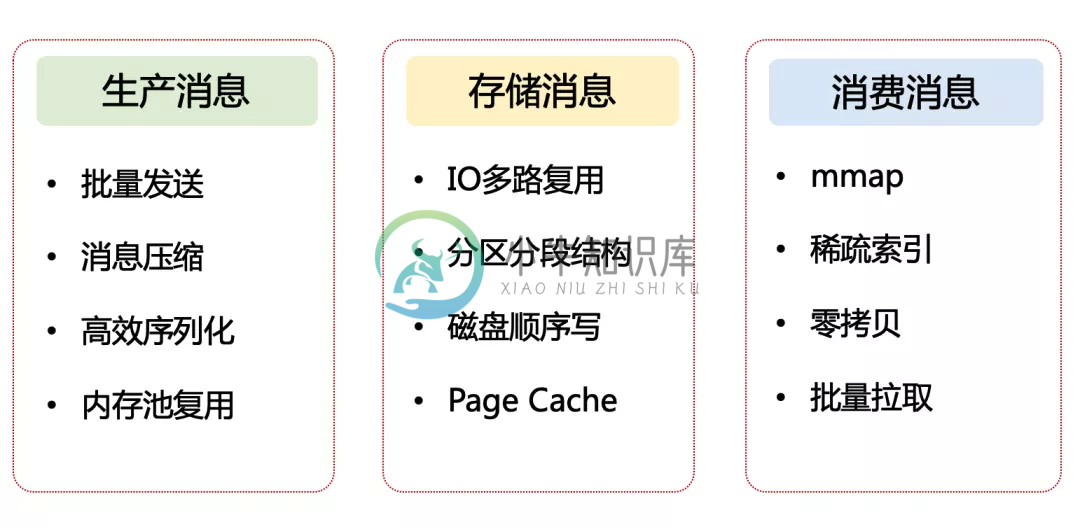 Kafka高性能设计-2
Kafka高性能设计-2主要内容:1. 存储消息的性能优化手段1. 存储消息的性能优化手段 存储消息属于 Broker 端的核心功能 IO多路复用, 磁盘顺序写, page缓存, 分区分段结构 1.1 IO 多路复用 对于 Kafka Broker 来说,要做到高性能,首先要考虑的是:设计出一个高效的网络通信模型,用来处理它和 Producer 以及 Consumer 之间的消息传递问题。 SocketServer : Kafka采用的是Reactor 网络
-
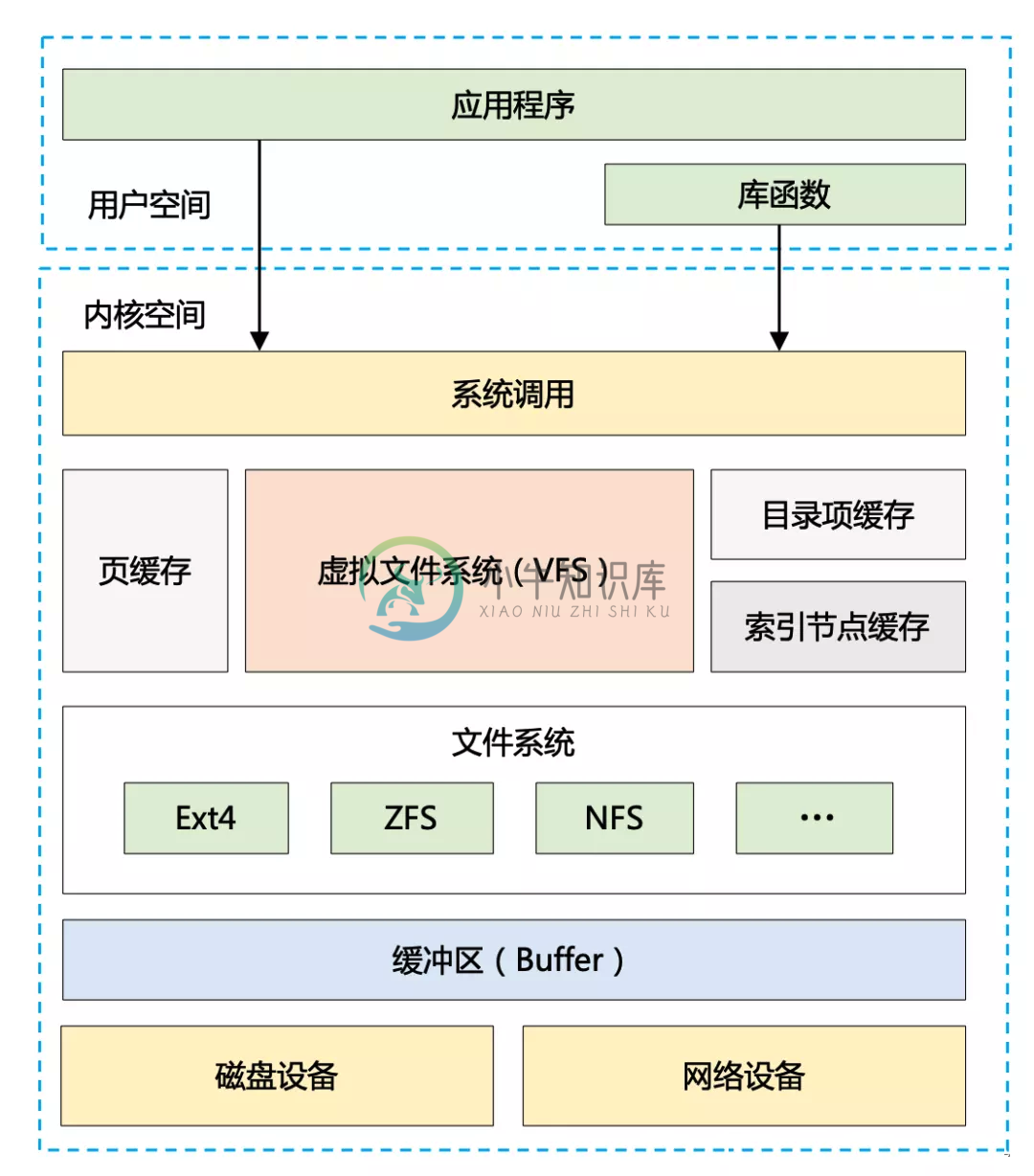 Kafka高性能设计-1
Kafka高性能设计-1主要内容:1. 如何理解高性能设计,2. Kafka 高性能设计的全景图,3. 生产消息的性能优化手段,4.Kafka源码分析Kafka 的高性能设计可以说是全方位的,从 Prodcuer 、到 Broker、再到 Consumer, 1. 如何理解高性能设计 对于线程池、多级缓存、IO 多路复用、零拷贝等技术是一个系统性的问题,至少需要深入到操作系统层面。从 CPU 和存储入手,去了解底层的实现机制,然后再自底往上,一层一层去解密和贯穿起来。 高性能设计离不开的就是计算和IO 计算: 1、让更