《HPC高性能计算工程师》专题
-
 字节AML高性能计算提前批一面经
字节AML高性能计算提前批一面经1,25分钟简历+项目周边八股,开始面了之后才知道现在都all in 大模型了,看到我简历上有大模型相关的就狂问大模型训练、微调、分布式等等细节,之前准备的高性能八股一点没问。。。 2,算法题是手撕attention算子,只用写前向不用写反向,基于numpy实现,还需要自己手写softmax,这个我之前看过llama的推理源码,能回忆起来一些,大致写出来了,但是v的shape有一些问题,最终跑通了
-
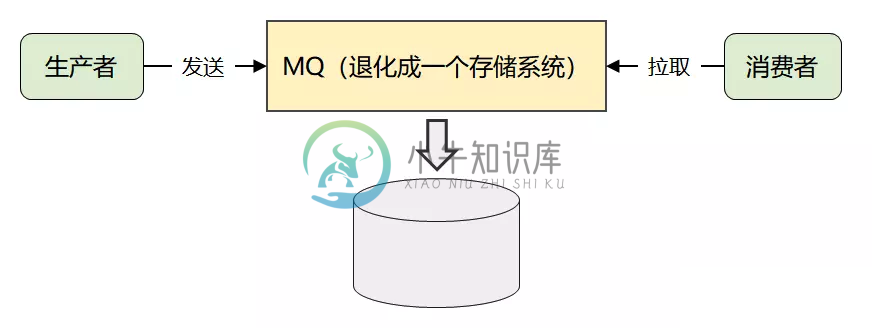 Kafka高性能设计之架构设计
Kafka高性能设计之架构设计主要内容:1.Kafka 的技术难点,2.Kafka 架构设计,3.Kafka的宏观架构设计,4.Kafka 的整体架构1.Kafka 的技术难点 Kafka 为实时日志流而生,要处理的并发和数据量非常大。可见,Kafka 本身就是一个高并发系统,它必然会遇到高并发场景下典型的三高挑战:高性能、高可用和高扩展。 为了简化实现的复杂度,Kafka 最终采用了很巧妙的消息模型:它将所有消息进行了持久化存储,让消费者自己各取所需,想取哪个消息,想什么时候取都行,只需要传递一个消息的 offset 进行
-
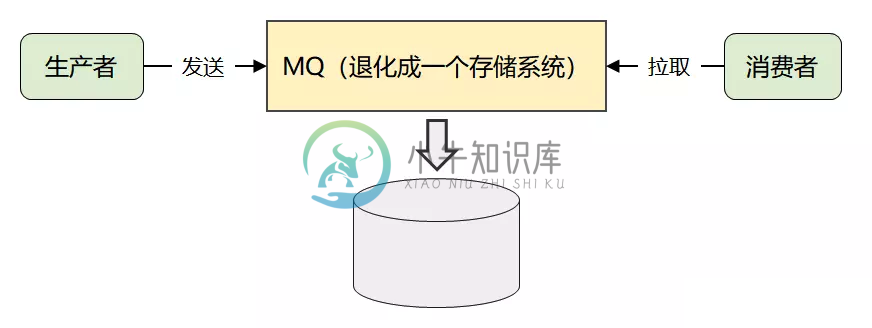 Kafka高性能设计之存储设计
Kafka高性能设计之存储设计主要内容:1.Kafka存储难度,2.Kafka 的存储选型分析,3.Kafka 的存储设计Kafka使用的是Logging(日志文件)这种很原始的方式来存储消息 对于存储设计有一些知识点: Append Only、Linear Scans、磁盘顺序写、页缓存、零拷贝、稀疏索引、二分查找等等。 Append Only Data Structures 的一些存储系统比如HBase, Cassandra, RocksDB 1.Kafka存储难度 Kafka 通过简化消息模型,将自己退化成了一
-
如何提高图中心度计算的并行性能?
我得到的性能下降后,并行化的代码,计算图中心。图比较大,100K顶点。单线程应用程序大约需要7分钟。根据julialang站点(http://julia.readthedocs.org/en/latest/manual/parallel-computing/#man-parallel-computing)的建议,我修改了代码并使用pmap api来并行计算。我开始计算8个过程(julia-p 8c
-
位运算性能,如何提高
我有一个简单的任务:确定需要多少字节来将某个数字(字节数组长度)编码到字节数组并编码最终值(实现本文:编码长度和值字节)。 最初我写了一个快速完成任务的方法: 这是一段旧代码,编写方式很糟糕。 现在我正在尝试使用按位运算符或类来优化代码。这是按位版本的示例: 以及类的最终实现: 所有方法都按预期工作。我使用秒表类页面中的一个示例来衡量性能。性能测试让我惊讶。我的测试方法执行了1000次该方法的运行
-
 影石 高性能算法 笔试
影石 高性能算法 笔试#24届软开秋招面试经验大赏# 投递岗位:高性能算法工程师 笔试时间 showmebug平台 100min 笔试题型:2个编程,2个问题 1、手写C++ string类,编程 2、二分查找,编程 3、对cache的理解,问答 4、数据结构顺序存储和链式存储的优缺点,问答 感觉难度还可以,就是showmebug这个平台用不惯,不太会用
-
 高性能计算,模型部署面经历 后摩智能实习
高性能计算,模型部署面经历 后摩智能实习后摩智能实习,线下面试 自我介绍 梯度下降,怎么求导,链式求导 relu激活函数,0点怎么求导 softmax实现,溢出问题 问给我发过来让我学习的量化相关的论文,adaquant,i-vit 答的都不好,说不没认真看,大三学生都比我学的好,还做了ppt来讲。都好卷,呜呜呜。 面试官人很好,但我太菜了基本忘关了,都没答上来,细节基本都说不清楚,只能懂个大概。后面还是要把基础知识和项目细节好好的准备
-
 元戎启行(上来就做仨题真没绷住)高性能计算工程师校招一面面经
元戎启行(上来就做仨题真没绷住)高性能计算工程师校招一面面经真没啥好说的,上来就写仨题 写题 concat如果有四个维度,每个维度该如何拼接 CUDA写concat,四个维度。每个维度都怎么写 LRU ------------------------------------ 面了。。。感觉又没面#元戎启行求职进展汇总#
-
 25秋招-元戎启行高性能计算一面凉经
25秋招-元戎启行高性能计算一面凉经总体感觉面试官还是挺有水平的,计算图,执行图讲的条理很清晰 先是自我介绍 项目经历 简单问了问项目经历 写一道题 时间多写两道 手撕是关于构造图相关的 给定一个节点类 里面有生产者 消费者 一个unordered_map 是一个邻接矩阵 记录节点和节点 前面的节点为先 后面的节点为后 要求输出一个vector 是这些节点的先后顺序 需要先对unordered_map迭代 然后先找第一层 的节点 后
-
 高德SLAM算法工程师面经
高德SLAM算法工程师面经投的是SLAM/三维重建/图文多模态算法工程师-视觉团队的岗位 一面 1、五分钟自我介绍 2、简历上项目深挖 3、由于简历中提到了矢量化相关的工作,因此面试官出的题目是给定一组二维点拟合直线,使用最小二乘实现函数功能即可,可以使用eigen库 4、反问环节 一些碎碎念 其实整体面下来我可以感受到面试官应该是做感知出身的,至于为什么会安排专业不太对口的面试官来面我也不太理解 今年SLAM岗位真的很少
-
用Java设计高性能状态机
问题内容: 我正在开始编写Java库以实现高性能的有限状态机。 我知道那里有很多库,但是我想从头开始编写自己的库,因为那里几乎所有的库都构造了自动机,每次只处理一个就优化了。 我想知道在实现这样的高性能库时,SO社区中涉足状态机设计的人们认为最重要/最好的设计原则。 注意事项 生成的自动机通常并不庞大。(〜100-500个州)。 该实现应该能够 扩展 。 该实现应支持 快速转换 (最小化,确定化等
-
计算子句中的列-性能
问题内容: 由于您不能在MySQL的where子句中使用计算列,如下所示: 你必须使用 计算(在该示例中,“(a * b + c)”是每行执行一次还是两次执行?有没有一种方法可以使速度更快?我觉得很奇怪,可以对列进行ORDER但没有WHERE- 条款。 问题答案: 您可以使用HAVING来过滤计算列: 请注意,您需要将其包括在SELECT子句中才能起作用。
-
HPC Toolkit
HPCToolkit 是一组多平台的工具,用于应用程序的性能分析。
-
Vue.js教程之计算属性
本文向大家介绍Vue.js教程之计算属性,包括了Vue.js教程之计算属性的使用技巧和注意事项,需要的朋友参考一下 Vue.js 的内联表达式非常方便,但它最合适的使用场景是简单的布尔操作或字符串拼接。如果涉及更复杂的逻辑,你应该使用计算属性。 计算属性是用来声明式的描述一个值依赖了其它的值。当你在模板里把数据绑定到一个计算属性上时,Vue 会在其依赖的任何值导致该计算属性改变时更新 DOM。这个
-
 虹软 -- 计算机视觉工程师
虹软 -- 计算机视觉工程师7.24 笔试 8.11 一面 自我介绍 项目1介绍(深挖) 项目2介绍(深挖) 代码:找到离给定两个节点最近的节点(力扣2359) 8.29 二面 自我介绍 项目1介绍(细挖) 项目2介绍(细挖) 专利介绍 反问 9.1 HR面 自我介绍 家庭情况 大学生活 研究生生活 未来规划 对象问题 #虹软#