《HPC高性能计算工程师》专题
-
高精度计算的应用
什么是高精度算法?它是处理大数字的数学计算方法。在一般的科学计算中,会经常算到小数点后几百位或者更多,当然也可能是几千亿几百亿的大数字。一般这类数字我们统称为高精度数。但近几年的CSPJ/S复赛貌似从未单独考过高精度算法,但有时会和其他算法一起考。所以还是有学习的必要。 一、高精度计算 高精度计算是指参与运算的数的范围大大超出了标准数据类型能表示的范围的运算。如100位数字和100位数字的加减乘除
-
1.5 Scipy:高级科学计算
scipy 包含许多专注于科学计算中的常见问题的工具箱。它的子模块对应于不同的应用,比如插值、积分、优化、图像处理、统计和特殊功能等。 scipy 可以与其他标准科学计算包相对比,比如GSL (C和C++的GNU科学计算包), 或者Matlab的工具箱。scipy是Python中科学程序的核心程序包;这意味着有效的操作 numpy 数组,因此,numpy和scipy可以一起工作。 在实现一个程序前
-
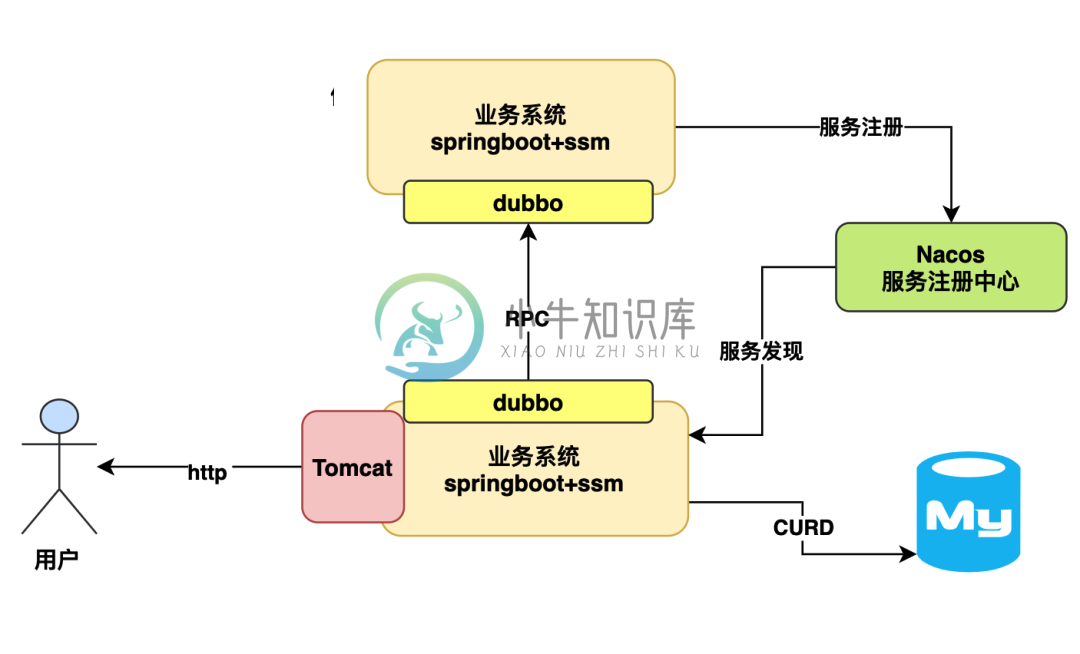 如何设计高性能的MySQL数据库架构?
如何设计高性能的MySQL数据库架构?主要内容:一般业务系统运行流程图,一台 4 核 8G 的机器能扛多少并发量呢?,高并发来袭时数据库会先被打死吗?,8 核 16G 的数据库每秒大概可以抗多少并发压力?,数据库架构可以从哪些方面优化?,总结今天给大家分享一个知识点,是关于 MySQL 数据库架构演进的,因为很多兄弟天天基于 MySQL 做系统开发,但是写的系统都是那种低并发压力、小数据量的,所以哪怕上线了也就是这么正常跑着而已。 但是你知道你连接的这个 MySQL 数据库他到底能抗多大并发压力吗?如果 MySQL 数据库扛不住压力
-
 大华(提前批)--智能算法工程师
大华(提前批)--智能算法工程师6.27 笔试 7.4 一面 自我介绍 项目1介绍(细挖) 项目2介绍(又是细挖) 语义分割和像素级分类的区别 项目里的方法是其他论文里的,还是自己的 C/C++语言如何申请内存 7.16 二面 自我介绍 研究生参加比赛情况 Anchor-free和Anchor-base的区别 密集目标的处理方式 概率分布图如何处理密集目标 基线为什么不用Anchor-free 语义分割,实例分割,场景分割 为什
-
 寒武纪c++高性能算法库开发面经
寒武纪c++高性能算法库开发面经9.7 一面 60分钟 1.实习项目介绍 2.实习相关问题 3.stl问题 4.c++11 内容 5.浮点数的表示方式 剩下记不得了 算法题: 1.相交链表找交点 2.两个字符串找最长相同连续子串 3.矩阵最长递增路径 反问 #寒武纪##寒武纪校招##C++工程师##C/C++##面经#
-
流和惰性计算
我读了Java8API中关于流抽象的内容,但我不太理解这句话: 当筛选操作创建一个新流时,该流是否包含已筛选的元素?它似乎理解了流只有在遍历时才包含元素,即使用终端操作。但是,than,什么包含过滤后的流?我糊涂了!!!
-
全局计算属性
在VitePress中,一些核心的 计算属性 可用在默认主题或自定义主题中。也可以直接用在使用Vue的Markdown页面中,例如使用$frontmatter.title可以获取在页面frontmatter中定义的标题。 $site 这是当前访问站点的$site值: { base: '/', lang: 'en-US', title: 'VitePress', descriptio
-
计算属性(Computed Properties)
计算属性将函数声明为属性,Ember.js在需要时自动调用计算属性,并在一个变量中组合一个或多个属性。 下表列出了计算属性的属性 - S.No. 属性和描述 1 链接计算属性 链接计算属性用于与一个或多个预定义的计算属性聚合。 2 Dynamic Updating 在调用计算属性时动态更新它们。 3 Setting Computed Properties 通过使用setter和getter方法帮助
-
 北森云计算 2024实习-后端工程师
北森云计算 2024实习-后端工程师视频面40分钟 自我介绍 两个栈实现队列(麻了,现场想了好久才想到,之前看过搞完了) 哈希冲突说一下,解决方法(开放地址法,拉链法),拉链法的缺点 什么叫父类引用指向子类引用,好处(就是问多态,没背熟) HashMap里面解决链表长度过长查询速度变慢的方法(背),链表和红黑树的查询时间复杂度 Java中的异常是怎么处理的(try catch, throw) 列举一些你知道的异常 finally代码
-
 好未来-计算机视觉算法工程师-实习转正
好未来-计算机视觉算法工程师-实习转正##好未来#秋招:一面面经,应该是凉经,趁着热乎记录一下。 1、30分钟的项目,根据你的简历上的项目进行提问,问的地方比较细,也会问你对这个方向的一些看法和理解。 2、5分钟左右的八股,但是这个八股主要还是涉及到多模态大模型的部分,我不太了解,只是在一个项目中用过多模态大模型,所以这部分比较快 3、手撕,竟然没手撕力扣的,手撕一个分割的评价指标,我主要做检测的,分割很久不碰了,不过在帮助下还是磕磕
-
 提高Flink广播性能
提高Flink广播性能我有一个管道,我在其中对事件流应用转换规则(从广播状态);当我运行广播时 我已附上两种情况的快照: 顶部行显示来自Kafka的流消耗事件,底部行显示消耗的规则
-
提高Kafka Producer的性能
我们运行在apache kafka 0.10.0. x和Spring 3. x上,不能使用Spring kafka,因为它支持Spring框架版本4. x。 因此,我们使用原生的Kafka Producer API来生成消息。 现在我关心的是我的制片人的表现。问题是我相信有人打电话给是真正连接到Kafka broker,然后将消息放入缓冲区,然后尝试发送,然后可能会调用。 现在,KafkaProd
-
提高MMO游戏性能
我们都知道MMO游戏的流行趋势。玩家面对面直播。 我关心的领域是玩家移动和游戏结果的存储。 通过NPGSQL适配器使用Csharp和PostgreSql v9.0 游戏客户端是基于浏览器的ASP.NET并调用所有与数据库相关的处理 为了理解我的查询,请考虑以下场景 我们将游戏进度存储在postgres表中。 例如,锦标赛从四名玩家开始,并遵循以下活动 < li >每个玩家从100点生命值开始 <
-
提高PostgreSQL查询性能
我正在数据库中运行以下查询: 它输出500行,其中只有一个结果列,运行大约需要1分钟43秒。输出以下计划: 逻辑是:对于每个选择的(在500个id的列表中)计算整数列,返回该金额与数字2147483647之间的较小值。结果必须包含500行,每个id对应一行,我们已经知道它们将与子查询中的至少一行匹配,因此不会生成空值。 索引仅是上的一个b树,属于整数类型。索引是主键上的b树,也是整数类型。表中的每
-
提高 After Effects 的性能
您可以通过优化您的计算机系统、After Effects、您的项目和您的工作流程来改进性能。此处提供的某些建议不是通过提高渲染速度而是通过降低其他操作(例如,打开项目)所需的时间来改进性能的。 注意:到目前为止,用来改进总体性能的最好方法是提前规划、针对您的工作流程和输出管道运行早期测试、并确认您所提供的内容是您的客户实际需要和预期的内容。(请参阅规划您的工作。) Lloyd Alvarez 在