《九号机器人》专题
-
CSS选择器中是否允许使用括号?
问题内容: 在下面的示例中,我想创建一个仅适用于带有文本“ Blockhead”的标头的CSS规则。 我可以使用括号吗?如果没有,我有什么选择? 问题答案: 不,括号不是CSS选择器中的有效运算符。他们是保留给功能符号,如,和。 无论如何,您不需要它们。本身就可以正常工作。 这是因为选择器和组合器的序列始终是线性读取的。组合器没有任何优先级。选择器可以解释为 选择 紧跟在class类元素之后的元素
-
 理解样式组件组件选择器和&号
理解样式组件组件选择器和&号在样式化组件文档中,它们有以下示例: https://www.styled-components.com/docs/advanced#referring-连接到其他组件 当您将鼠标悬停在其父对象(在本例中为链接)上时,它会显示一个改变颜色的图标。 从文件中,我们知道: 文档注释#1:样式化组件通过“组件选择器”模式清晰地解决了这个用例。每当一个组件被styled()工厂函数创建或包装时,它也会被分
-
火花独立编号执行器/核心控制
我不明白的是,当我提交作业并指定: 应该只占用4个核心。然而,当提交作业时,它将使用所有16个内核,并跳过参数而旋转8个执行器。但是,如果我将参数更改为,它将相应地调整,4个executors将向上旋转。
-
Slack-Clone项目中的表情符号拾取器
在我的slack克隆中有一个聊天输入字段。我遵循了一个关于添加emoji选择器(emoji-mart)的简单教程。聊天输入 然而,当我点击表情图标时,它会弹出表情图标所在的容器内的表情选择器窗口。(所以在聊天输入容器内部,同时改变其高度以包含emoji窗口)。emoji选择器窗口 我的问题是,我如何才能让它弹出聊天输入的上方而不是里面就像图片中原来的一样。是造型的问题还是我必须添加任何特殊的功能?
-
Redux @connect装饰器中的“ @”(符号处)是什么?
问题内容: 我正在用React学习Redux,偶然发现了这段代码。我不确定它是否特定于Redux,但我在其中一个示例中看到了以下代码片段。 虽然功能非常简单,但我不明白之前。如果我没有记错的话,它甚至都不是JavaScript运算符。 有人可以解释一下这是什么,为什么使用它? 更新: 实际上,它的一部分用于将React组件连接到Redux存储。 问题答案: 实际上,该符号是一个JavaScript
-
冒号分隔标记的XML解析器?[闭门]
如果我有冒号分隔的xml标签,比如
-
iReport设计器字符被问号替换?[副本]
怎么解决这个???
-
Redux@connect装饰器中的“@”(at符号)是什么?
它实际上是的一部分,用于将React组件连接到Redux存储。
-
Tomcat服务器不能使用任何端口号
当我试图在Eclipse中打开服务器时,我得到了“Server Tomcat V6.0 Server at localhost失败启动”的错误。我试着打开和关闭计算机,重新安装Tomcat,并反复更改服务器端口值。有没有人认识到以下错误代码中的任何东西,可能会帮助我弄清楚为什么我不能让我的服务器工作。
-
爪哇车辆登记号码验证器[副本]
我试过这个密码。 但在检查DL10G4839时,即使是幸运标志,也显示无效。号码。它不能正常工作。
-
将主机端口转发到Docker容器
问题内容: 主机可以打开Docker容器访问端口吗?具体来说,我在主机上运行了MongoDB和RabbitMQ,我想在Docker容器中运行一个进程以侦听队列并(可选)写入数据库。 我知道我可以将端口从容器转发到主机(通过- p选项),并可以从Docker容器中连接到外部环境(即Internet),但我不想公开RabbitMQ和MongoDB端口从主持人到外界 编辑:一些澄清: 我必须执行此技巧才
-
如何在当前机器上运行jvm
问题内容: 想象一下:两个Java项目在JDK1.5和JDK1.6上运行。两个在JDK 1.7上运行。如何获取正在运行的jvm名称,pid和项目名称就可以了。 结果应该看起来像: pid 1234,projec_tname prj1,java_version JDK1.6 pid 4354,projec_tname prj2,java_version JDK1.5 pid 6234,projec_
-
在Javascript中植入随机数生成器
问题内容: 是否可以在Javascript中植入随机数生成器(Math.random)? 问题答案: 不,不是,但是编写自己的生成器相当容易,或者最好使用现有的生成器。签出: 另外,请参阅David
-
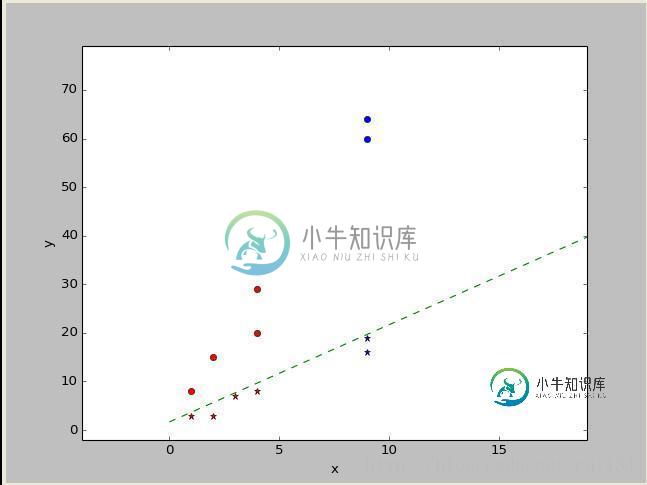 python机器学习之神经网络(一)
python机器学习之神经网络(一)本文向大家介绍python机器学习之神经网络(一),包括了python机器学习之神经网络(一)的使用技巧和注意事项,需要的朋友参考一下 python有专门的神经网络库,但为了加深印象,我自己在numpy库的基础上,自己编写了一个简单的神经网络程序,是基于Rosenblatt感知器的,这个感知器建立在一个线性神经元之上,神经元模型的求和节点计算作用于突触输入的线性组合,同时结合外部作用的偏置,对若干
-
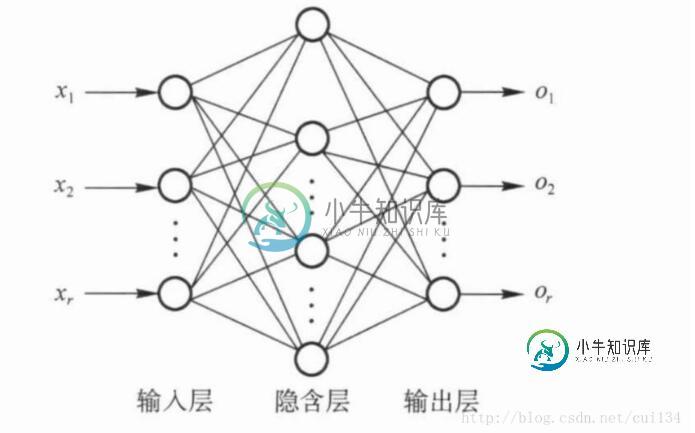 python机器学习之神经网络(二)
python机器学习之神经网络(二)本文向大家介绍python机器学习之神经网络(二),包括了python机器学习之神经网络(二)的使用技巧和注意事项,需要的朋友参考一下 由于Rosenblatt感知器的局限性,对于非线性分类的效果不理想。为了对线性分类无法区分的数据进行分类,需要构建多层感知器结构对数据进行分类,多层感知器结构如下: 该网络由输入层,隐藏层,和输出层构成,能表示种类繁多的非线性曲面,每一个隐藏层都有一个激活函数,将