《九号机器人》专题
-
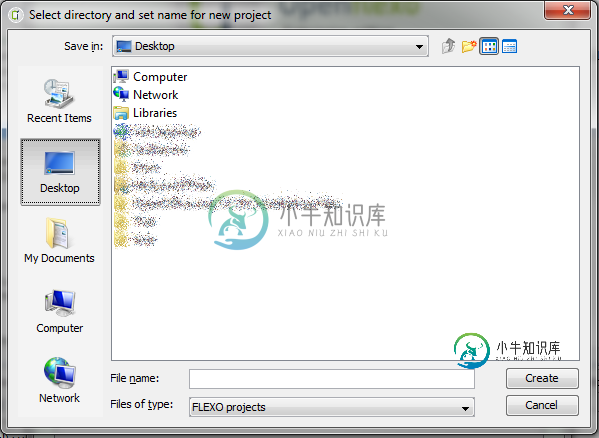 java 中的 Windows 本机文件选择器
java 中的 Windows 本机文件选择器我比第一个更喜欢它,因为: 您可以直接在顶部输入您的文件路径 您可以搜索文件夹 左边的直接访问包含整个文件树 如何在 Java 中获取它?
-
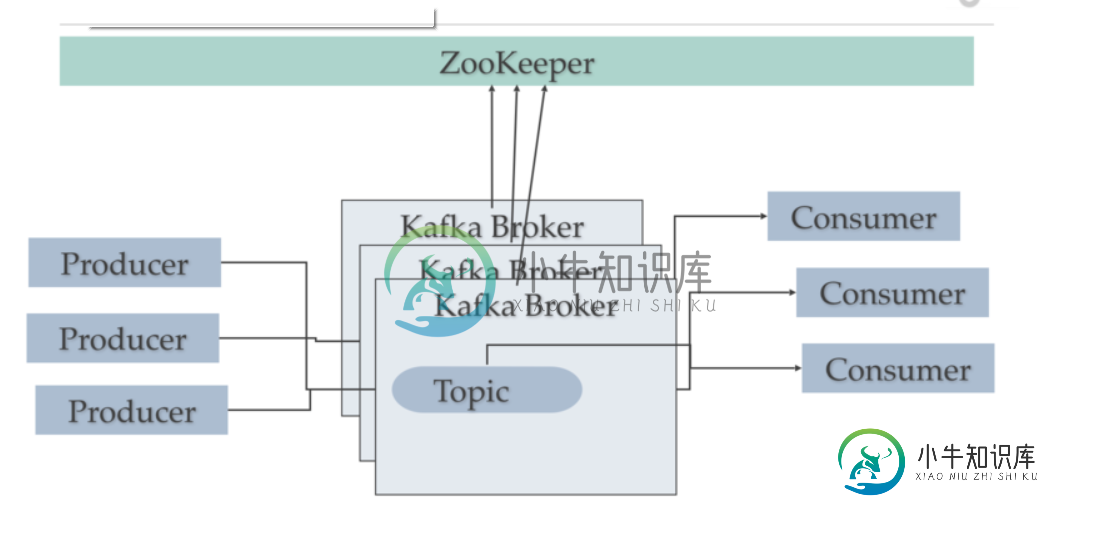 集群中的Kafka机器与Kafka通信
集群中的Kafka机器与Kafka通信我们有kafka集群,包含3个kafka代理节点和3个zookeepers服务器 Kafka版本- 10.1 ( hortonworks) 根据我的理解,因为所有的元数据都位于zookeeper服务器上,kafka代理正在使用这些数据(kafka通过端口2181与zookeeper服务器对话) 我只是想知道是否每台kafka机器都与集群中的其他kafka交谈,或者kafka可能只在动物园管理员服务
-
无法从主机访问jupyter docker容器
我有一个关于这个问题的问题https://hub.docker.com/r/jupyter/scipy-notebook.我正在尝试使用docker compose运行此图像: 组成: Dockerfile 我用手够不着它http://locahost:8888 .... 网址。我使用Windows10作为主机,并尝试从这个docker compose和这些工作中访问其他服务。
-
从docker容器访问主机数据库
-
Windows机器上jenkins中sonarQube扫描错误
我正在尝试从我的jenkins节点运行soanrQube扫描,Sonar scanner版本是SonarQube scanner 3.1.0.1141,SonarQube服务器是SonarQube服务器5.6.4。得到以下错误,有谁能在这方面帮助我。
-
Azure机器学习指定输入大小
我刚开始使用Azure ML,我正试图找出如何为模型指定输入大小。具体地说,我有一个很大的数据训练集,但我想一次只输入250条记录到PCA算法中。似乎我所能做的就是将整个数据集连接到PCA模块中。 我知道如何为X验证划分数据,但我希望一个分区(比如10000条记录)每次只向模型提供250条记录。
-
容器内机密的 k8s 管理/处理
我目前正在将我的docker部署迁移到k8s清单,我想知道如何处理秘密。目前,我的docker容器获取/run/secrets/app_secret_key以env-var的形式获取容器内的敏感信息。但与k8s机密处理相比,这有什么好处吗?因为在另一方面,我也可以在我的声明中这样做。yaml: 然后直接将秘密作为env变量放入容器中...我能够注意到的唯一区别是,如果我在容器内提取/run/sec
-
Firefox headless在headless redhat linux机器上崩溃
我正在尝试使用firefox headless在headless redhat linux构建机器上运行selenium测试。我创建驱动程序的方法如下所示: 我在日志文件中看到的错误如下所示: 我已经检查了机器上是否安装了gtk、glib、pango、xorg和libstdc的正确版本。以前有人在使用无头制造机时遇到过这个问题吗? Firefox版本:|Selenium版本:|GeckDrive版
-
 机器学习面试题与解析1
机器学习面试题与解析1面试高频题1: 题目:了解决策树吗 答案解析: 决策树是一种机器学习的方法。决策树的生成算法有ID3, C4.5和C5.0等。决策树是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。 决策树的构造过程: 决策树的构造过程一般分为3个部分,分别是特征选择、决策树生产和决策树裁剪。 (1)特征选择: 特征选择表示从众多的特征中选择一个
-
 机器学习面试题与解析2
机器学习面试题与解析2面试高频题11: 题目:L1、L2的原理?两者区别? 答案解析: 原理: L1正则是基于L1范数和项,即参数的绝对值和参数的积项;L2正则是基于L2范数,即在目标函数后面加上参数的平方和与参数的积项。 区别: 1.鲁棒性:L1对异常点不敏感,L2对异常点有放大效果。 2.稳定性:对于新数据的调整,L1变动很大,L2整体变动不大。 答案解析 数据分析只需要简单知道原理和区别就行,公式推导不需要,面试
-
 oppo机器学习算法实习面经
oppo机器学习算法实习面经前言: 岗位:机器学习算法实习 笔试情况:无笔试 一面 1.自我介绍(非科班硕,一份水实习); 2.介绍项目,并由此引出一系列八股文: 介绍gbdt算法的原理与实现 说说xgboost对于gbdt所做的主要优化 3.介绍实习工作 简单介绍resnet及其主要改进(shortcut连接,BN层),说说这些改进为什么work 介绍transformer及self-attention机制实现方式 了解哪
-
 星环_机器学习_提前批笔试
星环_机器学习_提前批笔试牛客上星环的帖子很少,我来分享下。 2道选择题10分,3道问答题30分,3道简答题60分 3道简答题是3选2,题目量不大,时间充裕。 题目考的内容就是统计学习,概率论,深度学习理论 跟牛客星环题库里的那套算法真题一样。 感觉挺复杂的,有些基础知识还是得系统梳理下😅 #星环科技##提前批#
-
 大疆8.7机器学习笔试A卷
大疆8.7机器学习笔试A卷不知道题目是不是随机抽的 感觉考了好多模型压缩问题,唉,好多选择题不会 简答三道,第一题是介绍至少三种模型压缩方法,第二题是考非对称算法和int8的卷积,第三题是考各个优化器 第二题完全没听过,直接跳过了,孩子会不会直接挂了唉 一个编程题,超级简单,完全二叉树的S遍历 统计一下大家简答题和编程题 #大疆##算法##投票##大疆2023校招笔试心得体会#
-
机器学习:贝叶斯、KNN、决策树
贝叶斯分类:贝叶斯分类是一类分类算法的总称,这类算法均已贝叶斯定理为基础,故统称为贝叶斯分类。 先验概率:根据以往经验和分析得到的概率。我们用 \small P(Y) 来代表在没有训练数据前假设\small Y拥有的初始概率。 后验概率:根据已经发生的事件来分析得到的概率。以 \small P(Y|X) 代表假设\small X 成立的情下观察到 \small Y数据的概率,因为它反映了在看到训练数据\small X后\small Y成立的置信度。
-
传感器和执行机构总线 - UART
链接 uLanding Radar