《九号机器人》专题
-
如何增加docker机器的Mac内存
问题内容: 我是Docker的新手,并尝试通过本教程从Docker映像设置MemSQL- http: //docs.memsql.com/4.0/setup/docker/ 。我在Mac上,该教程使用的似乎已被弃用。 VM需要4GB内存才能运行。本教程指定了如何执行此操作,但我找不到使用docker-machine / docker工具箱执行此操作的方法。 这是我正在使用的命令,也是我在不更改bo
-
Elixir连接不同机器上的节点
本文向大家介绍Elixir连接不同机器上的节点,包括了Elixir连接不同机器上的节点的使用技巧和注意事项,需要的朋友参考一下 例子 在一个IP地址上启动命名进程: 在另一个IP地址上启动另一个命名进程:
-
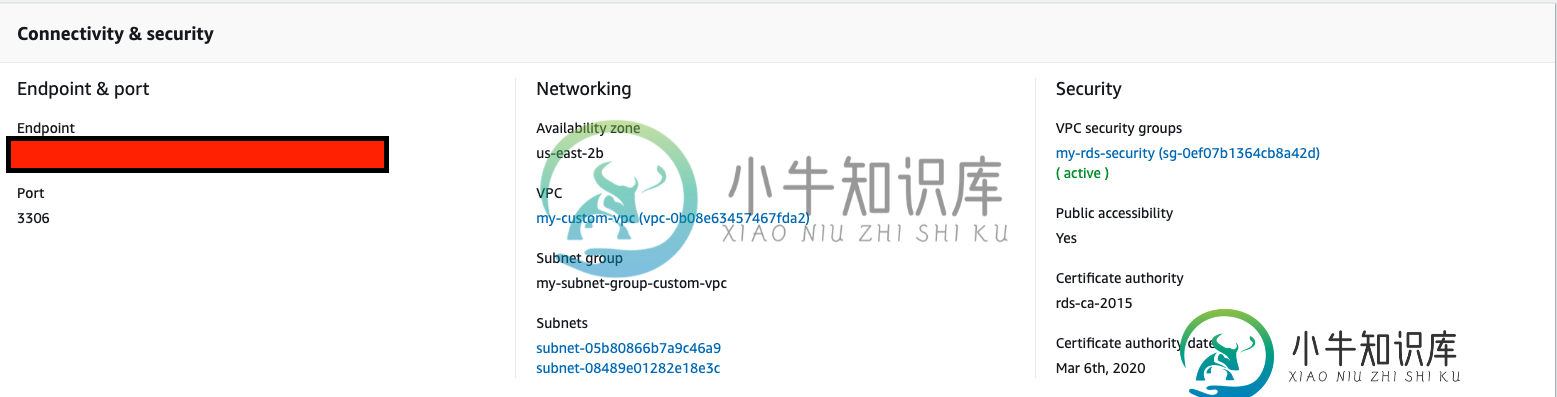 无法从本地机器连接到rds
无法从本地机器连接到rds我正在尝试使用rds部署带有MySQL引擎的rds实例。数据库子网组位于公用子网中。 我已执行以下检查:-允许安全组在端口3306上进行公共访问-在端口3306上的endpointURL上成功执行Telnet命令 配置如下: 日志记录详细信息: 正在尝试使用console连接到rds
-
如何使用MersenNetWisterng随机数生成器
我试图在Java程序中实现一个随机数生成器。我在用数学。random(),但这似乎效果不太好。然后我尝试使用SecureRandom,但这对我的游戏来说太长了。然而,我遇到了这个生成器,MersenNetWisterng随机数生成器。这似乎是我想要的;速度很快,但仍然是随机的。 然而,我已经很长时间没有用Java编写了,只有2个月,我对API既不了解也不了解。如果有人能帮我解释一下如何在我的代码中
-
使用KDE Dolphin连接到远程机器
我知道我可以使用KDE dolphin在远程机器中打开一个目录,我可以通过ssh直接访问该目录,但如果该机器距离我们只有一跳呢?通常,当我必须打开此类机器上的终端(我们称之为目的地)时,我会发出以下命令: 这允许我连接到“中间”服务器。然后,从: 如何使用KDE Dolphin从本地机器在目标中打开文件浏览器?
-
docker swarm容器连接到主机端口
我有一个swarm集群,我在其中创建了一个全局服务,在集群中的所有docker主机上运行。 目标是让此服务的每个容器实例连接到侦听docker主机上的端口。 有关详细信息,我将遵循此Docker守护进程指标指南,以在所有主机上公开新的docker指标API,然后将该主机端口代理到覆盖网络中,以便Prometheus可以从所有群主机中抓取指标。 我已经阅读了多个docker github问题#839
-
口译员如何使用机器指令?
我在网上的某个地方发现这样一句话:“解释器是一个程序,它使用编程语言的基本指令集作为其机器语言来实现或模拟虚拟机。”在上述引用的上下文中,有人能解释一下解释器是如何实际完成高级指令的执行的吗?网上的教程只涉及抽象的方式,即一次只需要一行代码就可以执行。它是使用机器指令库还是如何使用?我很想知道这件事。
-
Springboot客户机-服务器体系结构
创建Eureka发现客户端和服务器架构。在客户端有userInfo服务CRUD opeartion。它在启动时显示错误。错误是创建在类路径资源[org/springFramework/cloud/autoconfiure/ConfigurationProperty tiesRebinderAutoConfiguration.class]中定义的名为“配置属性Beans”的bean的错误:合并bea
-
允许docker容器访问本地主机
以下图片: 当我运行这个命令时,我可以在http://localhost:4444/上看到Selenium 任何帮助让这两种方式中的任何一种有效。
-
MAMP本地主机服务器不工作
LocalHost显示空白页。我将Apache的端口更改为80,当我按下open page时,它会转到localhost/mamp。当我删除/mamp时,我得到的只是一个空白页。我尝试过多种方法,比如关闭mamp,启动它,重新启动我的机器。我已经检查了文件夹设置,一切正常。 我通过创建一个新的文件页索引来测试它。html,它打开的很好。 我不知道它为什么不打开我的索引。php文件。下面是我的php
-
Android - 语音识别器和有线耳机
我想使用有线耳机作为的音频源。我阅读了诸如Android之类的问题 - 通过听筒播放音频和Android - 从听筒播放音频。最后我来: 但这不起作用。蓝牙耳机使用方法解决的问题 我没有找到替代< code > audio manager . startbluetoothsco();适用于有线耳机。能否将< code>SpeechRecognizer与有线耳机结合使用?
-
如何制作非随机数生成器?
我想构造一个像随机数生成器一样工作的对象,但它会以指定的顺序生成数字。 上面代码的问题,我不能在最后一行调用,因为它是一个生成器。我知道重写上述代码最直接的方法是简单地循环非随机数,而不是定义生成器。我更愿意让上面的例子起作用,因为我正在处理一大块代码,其中包括一个函数,该函数接受一个随机数生成器作为参数,我想添加传递非随机数序列的功能,而无需重写整个代码。
-
如何在EC2 Linux机器上安装java11?
但我一直有404错误。 这个命令“sudo amazon-linux-extras install java-openjdk11”只是声明amazon-linux-extras不存在。
-
Kotlin中的随机数生成器[重复]
您好,如何在kotlin中生成0到10之间的随机整数?我尝试了<code>Random()。nextInt()和,但我无法生成一个。谢谢
-
在本地主机启动tomcat服务器
当我在Eclipse中的服务器上运行我的应用程序时,我会得到这样的消息:“Tomcat V8.0服务器在localhost上所需的端口8080已经在使用中。该服务器可能已经在另一个进程中运行,或者某个系统进程正在使用该端口。要启动该服务器,您需要停止其他进程或更改端口号”。其他项目关闭。有人能帮我解决这个问题吗?我是爪哇初学者。