《人工智能算法》专题
-
 人工智能会取代人类吗?
人工智能会取代人类吗?让我从一句来自1950年的引言开始吧。当时的世界是个简单得多的地方。电视是黑白的。喷气式飞机尚未进入民用领域。硅晶体管还没发明问世。全世界一共只有十来台电脑。每台都是满满当当的真空管、继电器、插接板和电容器的华丽组合,能塞满整个房间。 因此,只有一个胆量十足的人才敢预测说:我相信,到了20世纪末,语言的用法和受过教育者的普遍观点将会出现重大转变,人可以说 机器在思考,且不认为这自相矛盾。多么大胆的
-
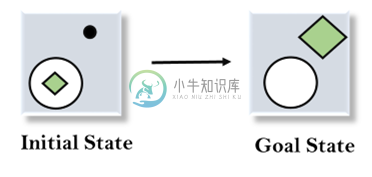 人工智能结束分析
人工智能结束分析主要内容:手段结束分析的工作原理,运算符子目标,均值分析算法人工智能中的手段 - 结束分析 前面已经学习了向前或向后推理的策略,但是两个方向的混合适合于解决复杂和大的问题。这样一种混合策略,使得有可能首先解决问题的主要部分,然后回过头来解决在组合问题的大部分期间出现的小问题。这种技术称为手段 - 末端分析。 Means-Ends分析是人工智能中用于限制AI程序中搜索的问题解决技术。 它是向后和向前搜索技术的混合体。 MEA技术于1961年由Allen Ne
-
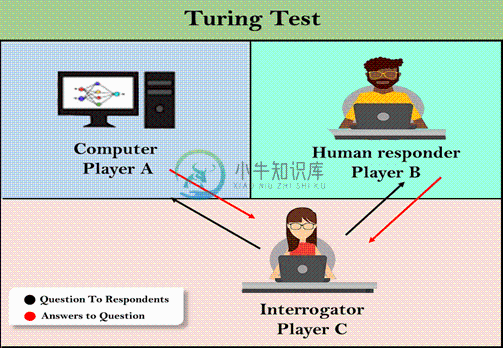 人工智能图灵测试
人工智能图灵测试主要内容:聊天机器人尝试图灵测试,中国室的争论1950年,艾伦·图灵(Alan Turing)介绍了一项测试,以检查机器是否能像人类一样思考,这项测试称为图灵测试。在这个测试中,图灵提出如果计算机可以在特定条件下模仿人类的反应,那么可以说计算机是智能的。 图灵在其1950年的论文“计算机器和智能”中介绍了图灵测试,该论文提出了“机器能想到吗?”的问题。 图灵测试基于派对游戏“模仿游戏”,并进行了一些修改。这个游戏涉及三个玩家,其中一个玩家是计
-
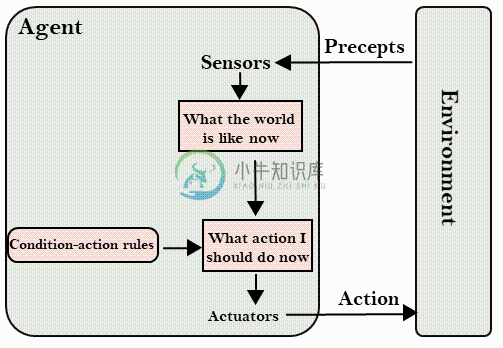 人工智能代理类型
人工智能代理类型主要内容:1. 简单的反射代理,2. 基于模型的反射代理,3. 基于目标的代理,4. 基于效用的代理,5. 学习代理代理可以根据其感知智能和能力的程度分为五类。所有这些代理都可以改善其性能并在一段时间内产生更好的行动。这些如下: 简单的反射代理 基于模型的反射代理 基于目标的代理商 基于效用的代理 学习代理 1. 简单的反射代理 简单反射代理是最简单的代理。这些代理人根据当前的感知来做出决定,并忽略其余的感知历史。 这些代理只能在完全可观察的环境中取得成功。 简单反射代理在决策和行动过程中不考虑
-
 人工智能与大数据
人工智能与大数据主要内容:1.关系,2.区别1.关系 现在,没有什么流行词比大数据和人工智能更常见了。无数的分析家向我们保证,将从根本上重塑我们的日常生活。事实上,对于围绕人工智能和大数据的所有讨论,很少有人提到这两种新兴技术的融合,尤其是在解释人工智能为什么迫切需要大数据以取得成功的时候。 这是人工智能和大数据操作之间的秘密联系,以及这两种新兴趋势将如何主导21世纪。 没有大数据就不能拥有智能机器 在开始描述人工智能和大数据如何一起工作之
-
智能人事
一站式的智能人事平台,从繁琐的人事工作中解放出来 完善和编辑员工档案 1、提醒员工完善资料 ●【路径】手机端钉钉-工作-智能人事-员工基本信息不完善-发DING提醒员工完善信息。 员工基本信息不完整 发DING提醒员工完善信息 2、修改员工信息,自动生成员工成长异动记录 ●【路径】手机端钉钉-智能人事-点击在职人员-筛选部门员工-点击一名员工-进入个人主页-操作-编辑员工个人档案。 员工个人档案
-
 智识神工的人工智能研究工程师面试
智识神工的人工智能研究工程师面试智识神工 第一面 主要是对项目的询问,解释项目的各种地方。 第二面 自我介绍 Double DQN与传统DQN的区别什么? 最大的区别在于Q现实的计算方法,DQN中TargetQ的计算方法是 YtDQN=Rt+1+γaQ(St+1,a;θt−)=Rt+1+γQ(St+1,aQ(St+1,a;θt),θt)Y_t^{DQN} =R_{t+1}+\gamma \max_aQ(S_{t+1},a;\th
-
人工智能AI代理环境
主要内容:环境特征环境是围绕代理的一切,但它不是代理本身的一部分。环境可以描述为存在代理的情况。操作为代理提供感知和行动的环境。 环境特征 根据Russell和Norvig的说法,从代理的角度来看,环境可以具有以下几种功能: 完全可观察与部分可观察 静态与动态 离散与连续 确定性与随机性 单一代理与多代理 情节与顺序 已知与未知 无障碍与无法访问 1. 完全可观察与部分可观察 如果代理传感器可以在每个时间点感知或访
-
 格力提前批-人工智能
格力提前批-人工智能格力的面试体验有点差,本来8月2日下午的面试,到第二天一直没人联系我,最后还是在招聘网站上找到了个电话询问。 面试内容是自我介绍+介绍项目 介绍一下SVM 有没有自己写过算法(面试官介绍主要工作是调参以及算法实现) 大概率凉,面试官认为我的背景主要是 用算法和现有工具分析数据 #格力#
-
 格力 第四批 人工智能
格力 第四批 人工智能8.4 一面15min,围绕项目内容说了许多,面试官问有没有接触过芯片相关,回答有了解但不多,但是感觉跟他们真正想要推进的项目能力对应度不太够。 晚上收到对面试进行测评,不知道是不是没戏了
-
 格力提前批 人工智能
格力提前批 人工智能第一次面试,应该凉了,本来自我介绍还好好准备了,但说起来还是有些啰嗦,建议还是精简一些。 问题也是跟项目有关的,YOLOv5和v2,v3的区别。 单片机如何判断cpu大端小端模式。
-
人工智能 - LlamaIndex如何使用?
LLamaIndex如何使用 llamaIndex是目前与LangChain类似的大模型拓展工具,可以用来交互LLM并做向量数据搜索等等,其应该如何使用?
-
 小红书|人工智能算法岗小红书笔试0423
小红书|人工智能算法岗小红书笔试0423刚做完,没啥准备,陪考了。。重新复盘了一下考试,分为两部分,给大家当当经验 一、选择题50分,大概考了如下知识点 一些概率论的基础, 贝叶斯, 高中数学的小球抽样题, 二叉树, 快速排序归并排序等一些排序算法, SVM、线性回归、逻辑回归、朴素贝叶斯算法 PV操作 大量机器学习训练基础知识 出入栈顺序 图像处理基础操作如特征提取、几何变换等等 KMP算法 二、编程题50分,10分+15分+25分
-
人工智能教育工具箱拓展包
主要模块 传感器: 热运动传感器 测距传感器 灯光传感器 超声波传感器 声音传感器 温度传感器 双路颜色传感器 运动传感器 MQ2气体传感器 温湿度传感器 磁敏传感器 火焰传感器 土壤湿度传感器 视觉模块 交互: 角度传感器 滑动电位器 按钮 多路触摸 摇杆 输出: 扬声器 电机驱动 舵机驱动 8×16 蓝色LED点阵 彩灯驱动 其他: 红外收发 电源模块 延长模块 RGB灯 蓝牙
-
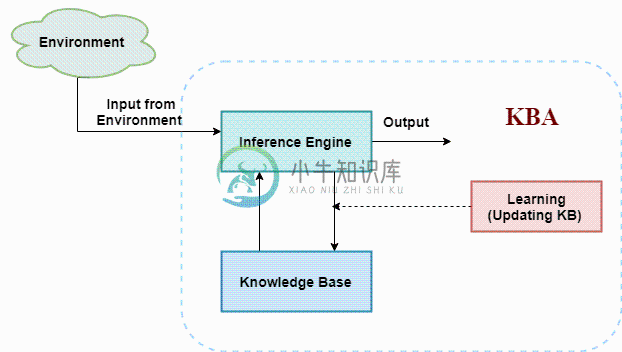 人工智能知识基础代理
人工智能知识基础代理主要内容:推理系统,由KBA执行的操作,基于知识的通用代理:,各级知识型代理商:,设计基于知识的代理的方法在人工智能中的知识基础代理: 智能代理需要有关现实世界的知识,才能做出有效行动的决策和推理。 基于知识的代理人是那些能够维持内部知识状态,理解知识,在观察后更新知识并采取行动的代理。这些代理可以用一些正式的代表来代表世界,并且能够智能地行动。 基于知识的代理由两个主要部分组成: 知识库和 推理系统。 基于知识的代理必须能够执行以下操作: 代理应该能够代表状态,行动等。 代理应该能够纳入新的感