《优化》专题
-
YAML 配置的优势在哪里 ?
本文向大家介绍YAML 配置的优势在哪里 ?相关面试题,主要包含被问及YAML 配置的优势在哪里 ?时的应答技巧和注意事项,需要的朋友参考一下 YAML 现在可以算是非常流行的一种配置文件格式了,无论是前端还是后端,都可以见到 YAML 配置。那么 YAML 配置和传统的 properties 配置相比到底有哪些优势呢? 配置有序,在一些特殊的场景下,配置有序很关键 支持数组,数组中的元素可以是基
-
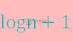 快速排序的最优情况?
快速排序的最优情况?本文向大家介绍快速排序的最优情况?相关面试题,主要包含被问及快速排序的最优情况?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 快速排序的最优情况是Partition每次划分的都很均匀,当排序的元素为n个,则递归树的深度为。在第一次做Partition的时候需对所有元素扫描一遍,获得的枢纽元将所有元素一分为二,不断的划分下去直到排序结束,而在此情况下快速排序的最优时间复杂度为。
-
说一下 JVM 调优的工具?
本文向大家介绍说一下 JVM 调优的工具?相关面试题,主要包含被问及说一下 JVM 调优的工具?时的应答技巧和注意事项,需要的朋友参考一下 JDK 自带了很多监控工具,都位于 JDK 的 bin 目录下,其中最常用的是 jconsole 和 jvisualvm 这两款视图监控工具。 jconsole:用于对 JVM 中的内存、线程和类等进行监控; jvisualvm:JDK 自带的全能分析工具,可
-
Java中的运算符优先级
问题内容: 在来自http://leepoint.net/notes- java/data/expressions/precedence.html的 一个示例中 以下表达式 被评估为 然后我从http://www.roseindia.net/java/master-java/operator- precedence.shtml 看到了另一个示例 以下表达式 被评估为 我对如何确定在涉及*和/时将首
-
ANTLR 4中的优先模糊性
我有一个巨大的ANTLR语法,我面临着一个小问题。语法有两个规则expr和set,定义如下: 这里的问题是,对于一组形式*s1*s2,应该减少如下: 然后RHS中的每一组应减少到: 但相反,它们正在减少: 因为forn的集合被解析为,而不是。 set的规则之一,将其简化为exr。语法中还有许多其他类似的规则也简化为exr。这里出现的问题是因为set和exr中的一些规则是相似的。但是因为有些规则不同
-
Java界面松耦合的优点?
有人能帮我吗,我读了一些Java紧耦合和松耦合的文章。我看了好几段YouTube视频和文章,对松散耦合有一定的怀疑,但仍然无法理解某些要点。我会解释我所理解的和让我困惑的。 在松散耦合中,我们限制类之间的直接耦合。但在紧密耦合中,我们注定要去上课。让我们举个例子。我有一个主类和另一个名为Apple的不同类。我在Main类中创建了这个类的一个实例 让我们看看松耦合 如果我将松散耦合中的方法签名从“喝
-
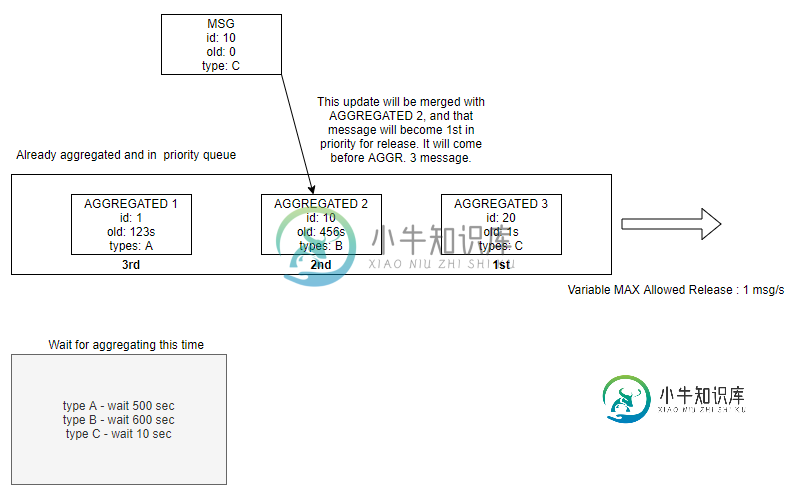 Spring集成-优先级聚合器
Spring集成-优先级聚合器我有以下应用程序要求: 从RabbitMq接收消息,然后根据一些更复杂的规则进行聚合,例如基于属性(具有预先给定的类型时间映射)和基于消息在队列中等待的现有时间(属性) 正如您在图中看到的一个用例:三条消息已经聚合并等待下一秒发布(因为当前速率为),但就在那时,以到达,并更新了,使其成为优先级最高的第一条消息。因此,在下一个选项中,我们不再发布聚合3,而是发布聚合2,因为它现在具有更高的优先级。
-
Java优先级队列比较器
假设我实现了一个HashMap,其中字符被分配了一个值的ArrayList。 我已经在HashMap中创建了这些字符的PriorityQueue,但我希望能够根据此优先级删除这些字符: {a,b,c} {a,b}删除c,因为它的ArrayList中包含一个值,该值决定必须首先删除它。 对此最好的方法是什么?
-
哪个优先:logback.xml还是logback-test.xml?
我是一个很新的登录。如果我的Spring启动项目包含这两个文件- :位于*src/main/resources/下 :位于*src/test/resources/下 哪一个装货?还是?
-
Dijkstra算法的优先级队列
我正在为Dikjstra算法做一个优先级队列。我目前在插入方法上有麻烦。我包含了整个类的代码,以防你需要更好地了解我想完成的事情。我将堆索引放在一个数组列表(heapIndex)中,堆放在另一个数组列表中。 那是我运行程序后的输出(值,优先级,堆索引)。*(-1)表示heapIndex中的空单元格。
-
Git 与 TFS 的优势 [已关闭]
< b >想改进这个问题?通过编辑此帖子更新问题,使其只关注一个问题。 我注意到一个流行词“我们应该将Git用于TFS”。我的理解是,Git 只是 DVCS。 TFS 支持从分支、标记、合并、签入、签出、上架等所有内容。 有人可以帮助我了解团队应该在什么情况下使用Git或TFS吗? 除了本地存储库和分布式之外,它还能为团队提供什么好处? 它对分支和合并有更好的支持吗?据我所知,开发人员可以在他/她
-
广度优先搜索:有向图
我正在尝试在有向图上实现BFS。我完全确定我的算法是正确的,但是,下面的代码段返回错误: 图表。CPP文件: 以及在以下方面的实际BFS实施: 因此,除了源节点之外,队列中的其他节点都给出了错误的邻接列表。虽然队列顺序运行良好,但队列中的节点给出了错误的邻接。 我不确定为什么会发生这种情况,虽然我怀疑这是由于按值复制节点而不是引用。 这是我在很长一段时间后的CPP计划,所以如果我错过了什么,请启发
-
非递归深度优先搜索:
在这篇文章中,biziclop为非递归深度优先搜索算法插入了伪代码。 如果我们想使用递归DFS算法来检查节点的适当性,我们可以利用两个变体:pre-order(当一个节点在其子节点之前检查时)和post-order(当子节点在节点之前检查时),加上仅针对二叉树的第三个变体(顺序:左子树,然后节点,然后右子树)。 如果可能的话,我对这三个变体都很感兴趣,所以我试图修改biziclop的伪代码,以便获
-
Java中的高优先级线程
我目前正在研究分布式应用程序的性能。我的目标是网络组件。目前,每个连接都有一个专用线程,在阻塞模式下处理套接字。我的目标是减少线程数量(不降低性能),如果可能的话,提高性能。 我重新设计了网络组件以使用异步通信,并尝试使用1到2个线程来处理整个网络。我做了一个简单的测试,我从一个节点在一个循环中写入,然后在另一个节点上读取,这是为了测试最大nw线程能力,我发现我的繁忙循环实现消耗了100%的cpu
-
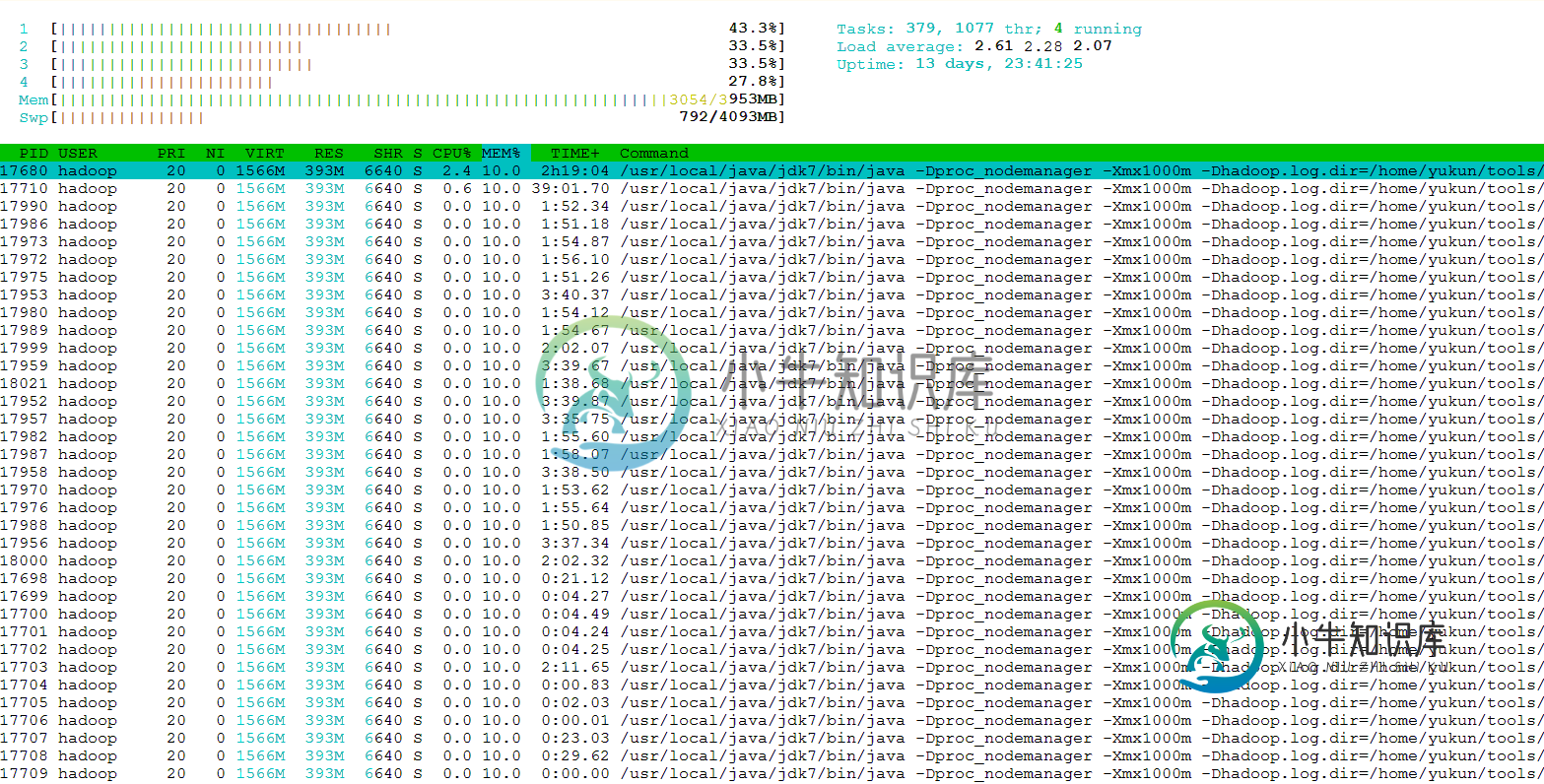 hadoop纱单节点性能调优
hadoop纱单节点性能调优我在我的Ubuntu VM上有hadoop 2.5.2单模式安装,它是:4核,每个核3GHz;4G内存。这个VM不是用于生产的,只用于演示和学习。 然后,我使用python编写了一个vey简单的map-reduce应用程序,并使用该应用程序处理49个XML。所有这些xml文件都很小,每个文件都有数百行。所以,我期待一个快速的过程。但是,big22令我惊讶的是,它花了20多分钟才完成这项工作(该工作