《曹操出行》专题
-
操作系统 - 操作系统基础
操作系统提供的服务 操作系统的五大功能,分别为:作业管理、文件管理、存储管理、输入输出设备管理、进程及处理机管理 中断 所谓的中断就是在计算机执行程序的过程中,由于出现了某些特殊事情,使得CPU暂停对程序的执行,转而去执行处理这一事件的程序。等这些特殊事情处理完之后再回去执行之前的程序。中断一般分为三类: 内部异常中断:由计算机硬件异常或故障引起的中断; 软中断:由程序中执行了引起中断的指令而造成
-
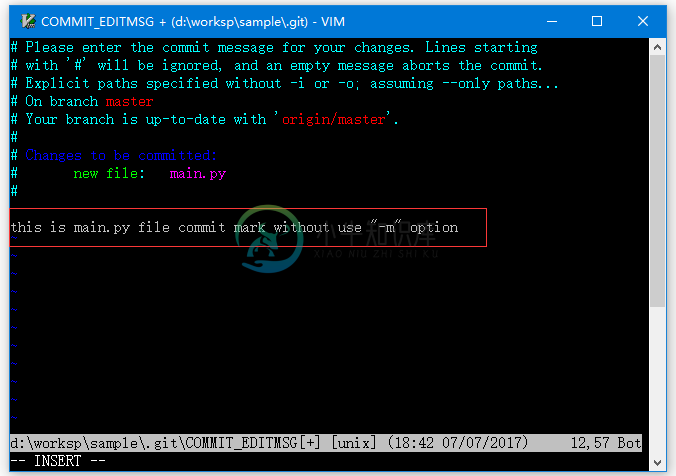 Git执行变更操作
Git执行变更操作在本文章教程中,我们将演示如何添加文件到 Git 存储库,并对存储库中的文件作修改和提交。 注意:在开始学习本教程之前,先克隆一个存储库,有关如何克隆存储库,请参考: http://www.yiibai.com/git/git_clone_operation.html 现在,在克隆存储库之后,我们开始学习 Git 基本的文件修改和版本管理操作。假设要使用 sample 这个存储库来协同管理一个Py
-
第四章 – 操作行为
目录 第一章 - 介绍 第二章 – MQTT控制报文格式 第三章 – MQTT控制报文 第四章 – 操作行为 第五章 – 安全 第六章 – 使用WebSocket 第七章 – 一致性目标 附录B - 强制性规范声明 4.1 状态存储 Storing state 为了提供服务质量保证,客户端和服务端有必要存储会话状态。在整个会话期间,客户端和服务端都必须存储会话状态 [MQTT-4.1.0-1]。会
-
GraphX的图运算操作 - 缓存操作
在Spark中,RDD默认是不缓存的。为了避免重复计算,当需要多次利用它们时,我们必须显示地缓存它们。GraphX中的图也有相同的方式。当利用到图多次时,确保首先访问Graph.cache()方法。 在迭代计算中,为了获得最佳的性能,不缓存可能是必须的。默认情况下,缓存的RDD和图会一直保留在内存中直到因为内存压力迫使它们以LRU的顺序删除。对于迭代计算,先前的迭代的中间结果将填充到缓存 中。虽然
-
GraphX的图运算操作 - 聚合操作
GraphX中提供的聚合操作有aggregateMessages、collectNeighborIds和collectNeighbors三个,其中aggregateMessages在GraphImpl中实现,collectNeighborIds和collectNeighbors在 GraphOps中实现。下面分别介绍这几个方法。 1 aggregateMessages 1.1 aggregateM
-
GraphX的图运算操作 - 关联操作
在许多情况下,有必要将外部数据加入到图中。例如,我们可能有额外的用户属性需要合并到已有的图中或者我们可能想从一个图中取出顶点特征加入到另外一个图中。这些任务可以用join操作完成。 主要的join操作如下所示。 class Graph[VD, ED] { def joinVertices[U](table: RDD[(VertexId, U)])(map: (VertexId, VD, U)
-
GraphX的图运算操作 - 结构操作
当前的GraphX仅仅支持一组简单的常用结构性操作。下面是基本的结构性操作列表。 class Graph[VD, ED] { def reverse: Graph[VD, ED] def subgraph(epred: EdgeTriplet[VD,ED] => Boolean, vpred: (VertexId, VD) => Boolean): Graph
-
GraphX的图运算操作 - 转换操作
GraphX中的转换操作主要有mapVertices,mapEdges和mapTriplets三个,它们在Graph文件中定义,在GraphImpl文件中实现。下面分别介绍这三个方法。 1 mapVertices mapVertices用来更新顶点属性。从图的构建那章我们知道,顶点属性保存在边分区中,所以我们需要改变的是边分区中的属性。 override def mapVertices[VD2:
-
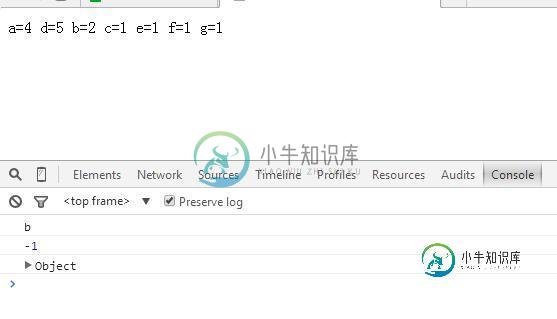 JS字符串统计操作示例【遍历,截取,输出,计算】
JS字符串统计操作示例【遍历,截取,输出,计算】本文向大家介绍JS字符串统计操作示例【遍历,截取,输出,计算】,包括了JS字符串统计操作示例【遍历,截取,输出,计算】的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS字符串统计操作。分享给大家供大家参考,具体如下: 记录字符串中每一项,并且记录个数。 运行效果图如下: PS:这里再为大家推荐2款非常方便的统计工具: 在线字数统计工具: http://tools.jb51.net/cod
-
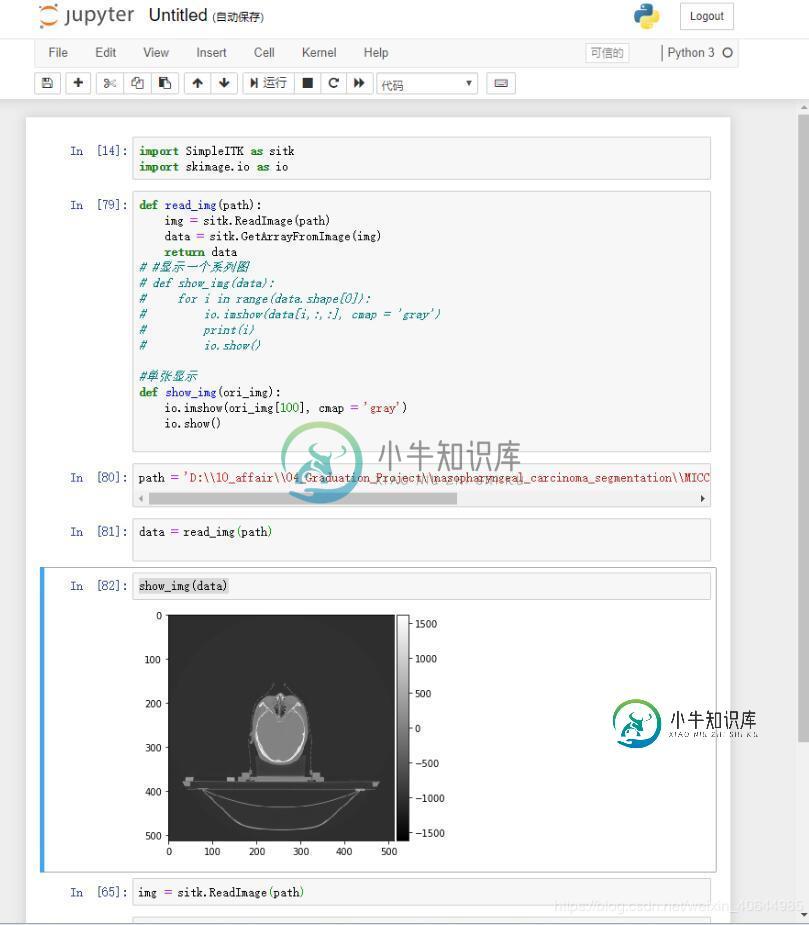 读取nii或nii.gz文件中的信息即输出图像操作
读取nii或nii.gz文件中的信息即输出图像操作本文向大家介绍读取nii或nii.gz文件中的信息即输出图像操作,包括了读取nii或nii.gz文件中的信息即输出图像操作的使用技巧和注意事项,需要的朋友参考一下 读取nii或者nii.gz文件中的信息,并且输出图像。 补充知识:SimpleITK读取医学图像 .nii 数据(2D显示) 【环境】win10 + python3.6 + SimpleITK nii文件是NIFTI格式的文件,出现的原
-
加载操作中出现BigQuery错误:无法连接BigQuery服务器
我似乎无法将任何数据从Socrata上传到BigQuery。我得到“加载操作中出现BigQuery错误:无法连接BigQuery服务器。”最初,我得到的错误限制为0个错误。现在,我已将CSV文件限制为一个数据行,因此出现了连接错误。下面是我的日志输出、代码和CSV。 我的日志输出: 我的代码: 我的csv文件:
-
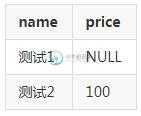 postgresql 实现查询出的数据为空,则设为0的操作
postgresql 实现查询出的数据为空,则设为0的操作本文向大家介绍postgresql 实现查询出的数据为空,则设为0的操作,包括了postgresql 实现查询出的数据为空,则设为0的操作的使用技巧和注意事项,需要的朋友参考一下 我就废话不多说了~ 补充:postgresql查询某列的最大值时,对查询结果为空做默认为0的处理 实例如下: 查询某个考生在某个指定试卷的最高分,如果没有,则返回0 以上为个人经验,希望能给大家一个参考,也希望大家多多支
-
任何 C 98 标准容器操作都可以抛出 std::bad_alloc吗?
我试图找出以下代码中是否需要try-catch: 浏览C 1998标准,我能找到的唯一线索是第23.1节“集装箱要求”第8点,其中包含以下句子: 此参数的副本用于在每个容器对象的生存期内由这些构造函数和所有成员函数执行的任何内存分配。 我对此的解释是,容器中的任何成员函数都可以调用分配器,因此任何成员函数都可以抛出std::bad_alloc。是我过于偏执还是真的是这样?
-
更新操作在MYBATIS中无法正常工作,并出现错误
Hi Iam试图在MyBATIS中执行更新操作,但Iam得到SQL语法错误异常,我不明白我做错了什么地方有人建议我
-
比较符号和溢出标志如何确定操作数关系?
基于比较有符号整数的跳转使用零、符号和溢出标志来确定操作数之间的关系。在具有两个有符号操作数的CMP之后,有三种可能的情况: -目标=来源 -目的地 我很难理解场景2和场景3。我已经研究了可能的组合,并看到它们确实有效——但我仍然不明白它们为什么有效。 有人能解释为什么比较符号和溢出标志反映符号整数关系吗? 编辑: 似乎对我的要求有一些理解。基于签名比较的跳转使用零、符号和进位标志——这些包括、等