
GraphX的图运算操作 - 聚合操作
GraphX中提供的聚合操作有aggregateMessages、collectNeighborIds和collectNeighbors三个,其中aggregateMessages在GraphImpl中实现,collectNeighborIds和collectNeighbors在GraphOps中实现。下面分别介绍这几个方法。
1 aggregateMessages
1.1 aggregateMessages接口
aggregateMessages是GraphX最重要的API,用于替换mapReduceTriplets。目前mapReduceTriplets最终也是通过aggregateMessages来实现的。它主要功能是向邻边发消息,合并邻边收到的消息,返回messageRDD。aggregateMessages的接口如下:
def aggregateMessages[A: ClassTag](sendMsg: EdgeContext[VD, ED, A] => Unit,mergeMsg: (A, A) => A,tripletFields: TripletFields = TripletFields.All): VertexRDD[A] = {aggregateMessagesWithActiveSet(sendMsg, mergeMsg, tripletFields, None)}
该接口有三个参数,分别为发消息函数,合并消息函数以及发消息的方向。
sendMsg: 发消息函数
private def sendMsg(ctx: EdgeContext[KCoreVertex, Int, Map[Int, Int]]): Unit = {ctx.sendToDst(Map(ctx.srcAttr.preKCore -> -1, ctx.srcAttr.curKCore -> 1))ctx.sendToSrc(Map(ctx.dstAttr.preKCore -> -1, ctx.dstAttr.curKCore -> 1))}
mergeMsg:合并消息函数
该函数用于在Map阶段每个edge分区中每个点收到的消息合并,并且它还用于reduce阶段,合并不同分区的消息。合并vertexId相同的消息。
tripletFields:定义发消息的方向
1.2 aggregateMessages处理流程
aggregateMessages方法分为Map和Reduce两个阶段,下面我们分别就这两个阶段说明。
1.2.1 Map阶段
从入口函数进入aggregateMessagesWithActiveSet函数,该函数首先使用VertexRDD[VD]更新replicatedVertexView, 只更新其中vertexRDD中attr对象。如构建图中介绍的,replicatedVertexView是点和边的视图,点的属性有变化,要更新边中包含的点的attr。
replicatedVertexView.upgrade(vertices, tripletFields.useSrc, tripletFields.useDst)val view = activeSetOpt match {case Some((activeSet, _)) =>//返回只包含活跃顶点的replicatedVertexViewreplicatedVertexView.withActiveSet(activeSet)case None =>replicatedVertexView}
程序然后会对replicatedVertexView的edgeRDD做mapPartitions操作,所有的操作都在每个边分区的迭代中完成,如下面的代码:
val preAgg = view.edges.partitionsRDD.mapPartitions(_.flatMap {case (pid, edgePartition) =>// 选择 scan 方法val activeFraction = edgePartition.numActives.getOrElse(0) / edgePartition.indexSize.toFloatactiveDirectionOpt match {case Some(EdgeDirection.Both) =>if (activeFraction < 0.8) {edgePartition.aggregateMessagesIndexScan(sendMsg, mergeMsg, tripletFields,EdgeActiveness.Both)} else {edgePartition.aggregateMessagesEdgeScan(sendMsg, mergeMsg, tripletFields,EdgeActiveness.Both)}case Some(EdgeDirection.Either) =>edgePartition.aggregateMessagesEdgeScan(sendMsg, mergeMsg, tripletFields,EdgeActiveness.Either)case Some(EdgeDirection.Out) =>if (activeFraction < 0.8) {edgePartition.aggregateMessagesIndexScan(sendMsg, mergeMsg, tripletFields,EdgeActiveness.SrcOnly)} else {edgePartition.aggregateMessagesEdgeScan(sendMsg, mergeMsg, tripletFields,EdgeActiveness.SrcOnly)}case Some(EdgeDirection.In) =>edgePartition.aggregateMessagesEdgeScan(sendMsg, mergeMsg, tripletFields,EdgeActiveness.DstOnly)case _ => // NoneedgePartition.aggregateMessagesEdgeScan(sendMsg, mergeMsg, tripletFields,EdgeActiveness.Neither)}})
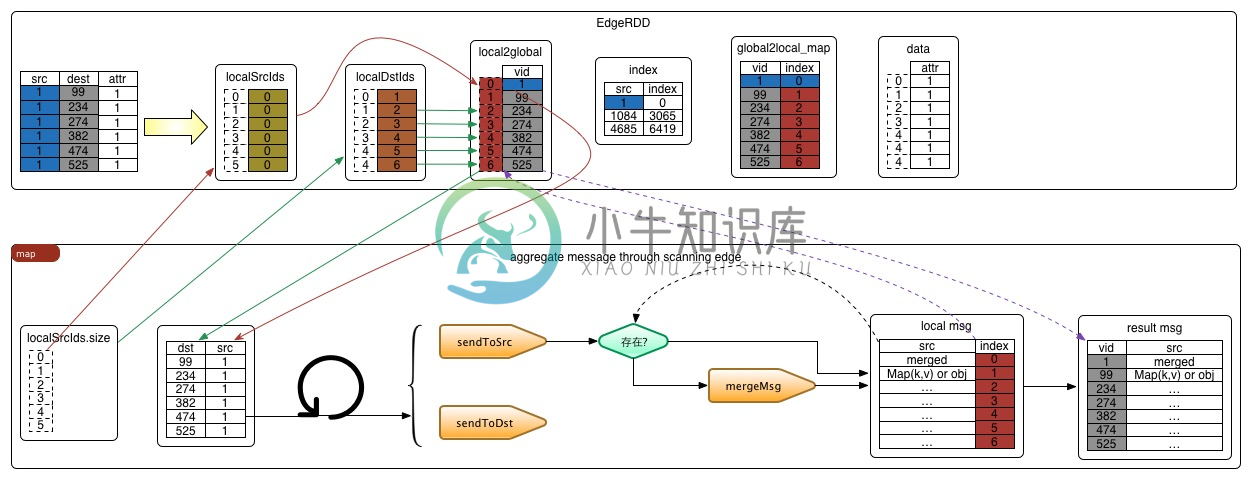
在分区内,根据activeFraction的大小选择是进入aggregateMessagesEdgeScan还是aggregateMessagesIndexScan处理。aggregateMessagesEdgeScan会顺序地扫描所有的边,
而aggregateMessagesIndexScan会先过滤源顶点索引,然后在扫描。我们重点去分析aggregateMessagesEdgeScan。
def aggregateMessagesEdgeScan[A: ClassTag](sendMsg: EdgeContext[VD, ED, A] => Unit,mergeMsg: (A, A) => A,tripletFields: TripletFields,activeness: EdgeActiveness): Iterator[(VertexId, A)] = {var ctx = new AggregatingEdgeContext[VD, ED, A](mergeMsg, aggregates, bitset)var i = 0while (i < size) {val localSrcId = localSrcIds(i)val srcId = local2global(localSrcId)val localDstId = localDstIds(i)val dstId = local2global(localDstId)val srcAttr = if (tripletFields.useSrc) vertexAttrs(localSrcId) else null.asInstanceOf[VD]val dstAttr = if (tripletFields.useDst) vertexAttrs(localDstId) else null.asInstanceOf[VD]ctx.set(srcId, dstId, localSrcId, localDstId, srcAttr, dstAttr, data(i))sendMsg(ctx)i += 1}
该方法由两步组成,分别是获得顶点相关信息,以及发送消息。
- 获取顶点相关信息
在前文介绍edge partition时,我们知道它包含localSrcIds,localDstIds, data, index, global2local, local2global, vertexAttrs这几个重要的数据结构。其中localSrcIds,localDstIds分别表示源顶点、目的顶点在当前分区中的索引。
所以我们可以遍历localSrcIds,根据其下标去localSrcIds中拿到srcId在全局local2global中的索引,最后拿到srcId。通过vertexAttrs拿到顶点属性。通过data拿到边属性。
- 发送消息
发消息前会根据接口中定义的tripletFields,拿到发消息的方向。发消息的过程就是遍历到一条边,向localSrcIds/localDstIds中添加数据,如果localSrcIds/localDstIds中已经存在该数据,则执行合并函数mergeMsg。
override def sendToSrc(msg: A) {send(_localSrcId, msg)}override def sendToDst(msg: A) {send(_localDstId, msg)}@inline private def send(localId: Int, msg: A) {if (bitset.get(localId)) {aggregates(localId) = mergeMsg(aggregates(localId), msg)} else {aggregates(localId) = msgbitset.set(localId)}}
每个点之间在发消息的时候是独立的,即:点单纯根据方向,向以相邻点的以localId为下标的数组中插数据,互相独立,可以并行运行。Map阶段最后返回消息RDD messages: RDD[(VertexId, VD2)]
Map阶段的执行流程如下例所示:
1.2.2 Reduce阶段
Reduce阶段的实现就是调用下面的代码
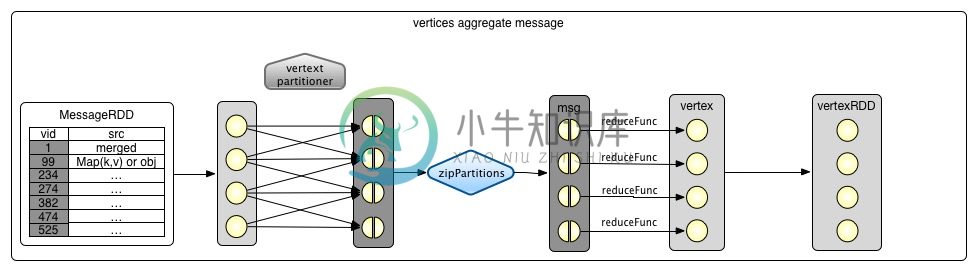
vertices.aggregateUsingIndex(preAgg, mergeMsg)override def aggregateUsingIndex[VD2: ClassTag](messages: RDD[(VertexId, VD2)], reduceFunc: (VD2, VD2) => VD2): VertexRDD[VD2] = {val shuffled = messages.partitionBy(this.partitioner.get)val parts = partitionsRDD.zipPartitions(shuffled, true) { (thisIter, msgIter) =>thisIter.map(_.aggregateUsingIndex(msgIter, reduceFunc))}this.withPartitionsRDD[VD2](parts)}
上面的代码通过两步实现。
1 对
messages重新分区,分区器使用VertexRDD的partitioner。然后使用zipPartitions合并两个分区。2 对等合并
attr, 聚合函数使用传入的mergeMsg函数
def aggregateUsingIndex[VD2: ClassTag](iter: Iterator[Product2[VertexId, VD2]],reduceFunc: (VD2, VD2) => VD2): Self[VD2] = {val newMask = new BitSet(self.capacity)val newValues = new Array[VD2](self.capacity)iter.foreach { product =>val vid = product._1val vdata = product._2val pos = self.index.getPos(vid)if (pos >= 0) {if (newMask.get(pos)) {newValues(pos) = reduceFunc(newValues(pos), vdata)} else { // otherwise just store the new valuenewMask.set(pos)newValues(pos) = vdata}}}this.withValues(newValues).withMask(newMask)}
根据传参,我们知道上面的代码迭代的是messagePartition,并不是每个节点都会收到消息,所以messagePartition集合最小,迭代速度会快。
这段代码表示,我们根据vetexId从index中取到其下标pos,再根据下标,从values中取到attr,存在attr就用mergeMsg合并attr,不存在就直接赋值。
Reduce阶段的过程如下图所示:
1.3 举例
下面的例子计算比用户年龄大的追随者(即followers)的平均年龄。
// Import random graph generation libraryimport org.apache.spark.graphx.util.GraphGenerators// Create a graph with "age" as the vertex property. Here we use a random graph for simplicity.val graph: Graph[Double, Int] =GraphGenerators.logNormalGraph(sc, numVertices = 100).mapVertices( (id, _) => id.toDouble )// Compute the number of older followers and their total ageval olderFollowers: VertexRDD[(Int, Double)] = graph.aggregateMessages[(Int, Double)](triplet => { // Map Functionif (triplet.srcAttr > triplet.dstAttr) {// Send message to destination vertex containing counter and agetriplet.sendToDst(1, triplet.srcAttr)}},// Add counter and age(a, b) => (a._1 + b._1, a._2 + b._2) // Reduce Function)// Divide total age by number of older followers to get average age of older followersval avgAgeOfOlderFollowers: VertexRDD[Double] =olderFollowers.mapValues( (id, value) => value match { case (count, totalAge) => totalAge / count } )// Display the resultsavgAgeOfOlderFollowers.collect.foreach(println(_))
2 collectNeighbors
该方法的作用是收集每个顶点的邻居顶点的顶点id和顶点属性。
def collectNeighbors(edgeDirection: EdgeDirection): VertexRDD[Array[(VertexId, VD)]] = {val nbrs = edgeDirection match {case EdgeDirection.Either =>graph.aggregateMessages[Array[(VertexId, VD)]](ctx => {ctx.sendToSrc(Array((ctx.dstId, ctx.dstAttr)))ctx.sendToDst(Array((ctx.srcId, ctx.srcAttr)))},(a, b) => a ++ b, TripletFields.All)case EdgeDirection.In =>graph.aggregateMessages[Array[(VertexId, VD)]](ctx => ctx.sendToDst(Array((ctx.srcId, ctx.srcAttr))),(a, b) => a ++ b, TripletFields.Src)case EdgeDirection.Out =>graph.aggregateMessages[Array[(VertexId, VD)]](ctx => ctx.sendToSrc(Array((ctx.dstId, ctx.dstAttr))),(a, b) => a ++ b, TripletFields.Dst)case EdgeDirection.Both =>throw new SparkException("collectEdges does not support EdgeDirection.Both. Use" +"EdgeDirection.Either instead.")}graph.vertices.leftJoin(nbrs) { (vid, vdata, nbrsOpt) =>nbrsOpt.getOrElse(Array.empty[(VertexId, VD)])}}
从上面的代码中,第一步是根据EdgeDirection来确定调用哪个aggregateMessages实现聚合操作。我们用满足条件EdgeDirection.Either的情况来说明。可以看到aggregateMessages的方式消息的函数为:
ctx => {ctx.sendToSrc(Array((ctx.dstId, ctx.dstAttr)))ctx.sendToDst(Array((ctx.srcId, ctx.srcAttr)))},
这个函数在处理每条边时都会同时向源顶点和目的顶点发送消息,消息内容分别为(目的顶点id,目的顶点属性)、(源顶点id,源顶点属性)。为什么会这样处理呢?
我们知道,每条边都由两个顶点组成,对于这个边,我需要向源顶点发送目的顶点的信息来记录它们之间的邻居关系,同理向目的顶点发送源顶点的信息来记录它们之间的邻居关系。
Merge函数是一个集合合并操作,它合并同同一个顶点对应的所有目的顶点的信息。如下所示:
(a, b) => a ++ b
通过aggregateMessages获得包含邻居关系信息的VertexRDD后,把它和现有的vertices作join操作,得到每个顶点的邻居消息。
3 collectNeighborIds
该方法的作用是收集每个顶点的邻居顶点的顶点id。它的实现和collectNeighbors非常相同。
def collectNeighborIds(edgeDirection: EdgeDirection): VertexRDD[Array[VertexId]] = {val nbrs =if (edgeDirection == EdgeDirection.Either) {graph.aggregateMessages[Array[VertexId]](ctx => { ctx.sendToSrc(Array(ctx.dstId)); ctx.sendToDst(Array(ctx.srcId)) },_ ++ _, TripletFields.None)} else if (edgeDirection == EdgeDirection.Out) {graph.aggregateMessages[Array[VertexId]](ctx => ctx.sendToSrc(Array(ctx.dstId)),_ ++ _, TripletFields.None)} else if (edgeDirection == EdgeDirection.In) {graph.aggregateMessages[Array[VertexId]](ctx => ctx.sendToDst(Array(ctx.srcId)),_ ++ _, TripletFields.None)} else {throw new SparkException("It doesn't make sense to collect neighbor ids without a " +"direction. (EdgeDirection.Both is not supported; use EdgeDirection.Either instead.)")}graph.vertices.leftZipJoin(nbrs) { (vid, vdata, nbrsOpt) =>nbrsOpt.getOrElse(Array.empty[VertexId])}}
和collectNeighbors的实现不同的是,aggregateMessages函数中的sendMsg函数只发送顶点Id到源顶点和目的顶点。其它的实现基本一致。
ctx => { ctx.sendToSrc(Array(ctx.dstId)); ctx.sendToDst(Array(ctx.srcId)) }
4 参考文献
【2】spark源码