《推荐算法工程师》专题
-
 快手二面 暑期 推荐算法 3.29
快手二面 暑期 推荐算法 3.291.code 反转部分链表 秒了 2.项目 召回正负样本如何定义,如何负采样,知道热度降权吗 如何序列建模,复杂度你是如何优化的,有尝试过硬算和优化的差异吗 召回用啥评价,线上用什么评价 如何排查指标线上线下不一致 3.八股 无 4.反问 组里氛围,转正策略 面试官说还有三面,感觉都回答上来了,希望进三面 我已经不想笔试、面试了,快手,快点翻臣妾的牌子呀,我直接从了
-
 快手一面 暑期 推荐算法 3.25
快手一面 暑期 推荐算法 3.251.code 最长递增子序列,dp+二分优化 2.项目 一直在问之前实习做的内容 知识图谱,双塔,正负样本,多任务模型演进 了不了解推荐系统,介绍一下链路 正样本太少,如何解决,业务角度+技术角度 还聊了不少开放性问题,比如你怎么看待召回阶段 3.八股 无 4.反问 组里做什么,base在哪 没有拷打我,让我一度怀疑有kpi的嫌疑 已经神智不清了,被拷打难受,不被拷打觉得kpi 求进二面,基本上都
-
 百度推荐算法实习一二面
百度推荐算法实习一二面一面 一小时 介绍自己的项目 项目相关问题(其中一个是问方法/论文的创新点在哪) 协方差和相关系数是什么,他们的的关系是什么 L1范数和L2范数的区别 谈谈Sigmoid ReLU函数在0点的梯度怎么处理 Transformer和Rnn的区别 谈谈Transformer多头注意力机制,多头注意力和普通注意力的区别 从普通注意力换成多头注意力会导致参数暴涨吗?如果有所增加的话,请分析主要是哪个结构导
-
 腾讯搜索推荐算法一二面
腾讯搜索推荐算法一二面一面全程一个小时20分钟 1.自我介绍 2.讲实习项目,问了下多路召回合并的问题,怎么做的小流量ab实验,每路召回占比怎么确定。 3.召回命中率怎么算的,怎么确认漏召的商品。反复盘问了很多细节上的东西 4.讲了下另一个rag项目(做的不咋样) 5.知识库的大小和结构 6.扣了很多细节,觉得我做的太简单了,问我为什么不用大模型来微调(我说没资源) 7.怎么微调的嵌入模型,负样本选择,rag里还可以怎
-
 快手推荐算法一二面汇总
快手推荐算法一二面汇总一面8-19 1.自我介绍 2.问美团的实习,问我商品量级,召回中相关性分档怎么做的,会不会出现query太不规范不能match到商品,怎么解决?我们的场景是否每个query和item都能匹配到相关性分数? 3.精排模型我们用的baseline是什么,怎么用query和行为序列做的target attention,行为序列怎么截断的,最后如何用query打压搜索结果的推荐多样性? 4.有哪些序列建
-
 京东零售-推荐算法hr面 4.2
京东零售-推荐算法hr面 4.2业务面就一轮,然后后面就是hr面了 面试流程: 自我介绍 对项目经历进行简单提问 之前在京东物流实习感受怎么样,有什么收获 未来期望的工作地点 研究生为啥选择控制科学与工程专业 考研去的清华还是保研 本科成绩怎么样 入学以来最有成就感的一件事 问问我在其他公司面试情况,offer情况 入职多久能到岗 反问: 为啥视频会议室地址写的是上海,base地上海吗,想去北京的实习(后来解释了base在北京,
-
Git 与 GitHub 工具推荐
Git 命令行增强 diff-so-fancy diff so fancy 截图 git-extras Ubuntu $ sudo apt-get install git-extras Mac OS X with Homebrew $ brew install git-extras $ git-summary project : github-roam repo age : 2 year
-
算法 - 请问AI推理加速有推荐的书吗?
请问AI推理加速有推荐的书吗?学习路线是什么?
-
好书推荐篇 - 非编程类书籍推荐
在 stackoverflow 上有人提问 程序员应该阅读的非编程类书籍有哪些? 本来只想整理编程类书籍, 不过突然眼前一亮,发现了《The Art of War - Sun Tzu》回答者的推荐说明引用 Wikipedia 上的: 亚马逊提供免费的 Kindle 版读本:孙子兵法 Much of the text is about how to fight wars without actual
-
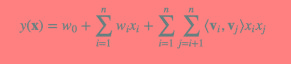 请你说一说推荐算法,fm,lr,embedding
请你说一说推荐算法,fm,lr,embedding本文向大家介绍请你说一说推荐算法,fm,lr,embedding相关面试题,主要包含被问及请你说一说推荐算法,fm,lr,embedding时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 推荐算法: 基于人口学的推荐、基于内容的推荐、基于用户的协同过滤推荐、基于项目的协同过滤推荐、基于模型的协同过滤推荐、基于关联规则的推荐 FM: LR: 逻辑回归本质上是线性回归,只是在特征到结果的映射中
-
矩阵分解协同过滤推荐算法
1.矩阵分解用于推荐算法要解决的问题 在推荐系统中,我们常常遇到的问题是这样的,我们有很多用户和物品,也有少部分用户对少部分物品的评分,我们希望预测目标用户对其他未评分物品的评分,进而将评分高的物品推荐给目标用户。比如下面的用户物品评分表: 用户物品 物品1 物品2 物品3 物品4 物品5 物品6 物品7 用户1 3 5 1 用户2 2 4 用户3 4 用户4 2 1 用户5 1 4
-
 探探-推荐算法-日常实习面经
探探-推荐算法-日常实习面经一面: 1. 对推荐算法大概有多少了解 2. kaggle比赛用了什么模型,做了什么优化 3. 你是如何把几个模型的分数做融合的 4. 如果这个权重也作为一个变量参与到训练,这种方式和你手动调参相比会有什么样的差异呢 这题我回答的是串行训练会更多耗时,但是参数精度会提高效果会更好,但是总觉得还是没答到点子上 5. 随机森林的具体运行过程 6. 如何判断过拟合和欠拟合,怎么解决 7. 如何解决梯度消
-
 B站 推荐算法一二三面面经
B站 推荐算法一二三面面经好像是首页自然推荐,流程推进很快,但是面试体验一般,前两面面试官都是在工位上比较吵 一面 聊半小时实习项目,问了比较多细节,但是没抛出啥记忆深刻的问题,全忘了 手撕:一个list里面存放每根木棍长度,问是否能够正好利用所有木棍拼成正n边形。应该是回溯+剪枝,一开始完全没思路,提示回溯之后写了个没咋剪枝的版本,优化预剪枝版本有点写不出来了。。不过第二天一早就通知过了 二面 聊了四十分钟实习项目,没答
-
 快手推荐算法暑期实习面经
快手推荐算法暑期实习面经一面时间:4月7日 11:00 ~ 12:00 没有开摄像头,先是自我介绍 然后详细的问了一下实习经历,对实习中的项目做了非常详细的询问。 期间问了一下auc和gauc的区别,为什么使用gauc而不用auc。 然后因为项目用了图文理解大模型,询问了一些对比学习的loss,介绍一些nce loss之类的,然后怎么构造正负样本。 还有就是交叉熵损失函数的使用的注意事项。 使用RELU的一些潜在问题。
-
 美团二面 推荐算法 3月25日
美团二面 推荐算法 3月25日讲一下看过的强化和推荐结合的论文 你简历提到的这些经典推荐算法的公共特性是什么? 离线的模型实际上线 给用户提供一些bad case,影响用户体验怎么办 留存率和模型实际优化的链路特别长,那该怎么办 点击率和留存率不同指标如何统一考虑? mmoe如何同时考虑这两个指标? 了解hadoop spark吗? 算法题:二分查找到AABBCDDFF奇数字符串中的单个字符C 二面感觉问的方向偏重余业务,实际