《顺丰机器学习》专题
-
 顺丰:iOS开发,一面面经
顺丰:iOS开发,一面面经时长:30分钟 1. 自我介绍(约5分钟) 2. iOS基础 2.1 在启动一个App时,类的加载过程是什么样的? 2.2 在OC或者Swift中,调用一个类的方法时,具体的流程是什么样的?(OC走runtime机制,Swift则是四种不同的派发机制:直接派发、虚函数表派发、见证表派发、runtime动态派发) 2.3 一个App是如何被渲染的?(Vsync信号) 2.4 刚刚提到了离屏渲染,在什
-
 9月22 顺丰前端二面
9月22 顺丰前端二面具体就是问项目 项目中的难点 怎么解决的,知道是什么原因吗 useEffect useLayoutEffect useState同步异步,为什么 手撕一道leetcode 简单题 估计是来当分母的,凉凉 补个一面 闭包, 手撕代码 ,具体忘了 盒模型 垂直居中 给你代码问输出
-
 顺丰物流运营岗 面经
顺丰物流运营岗 面经刚刚面完,一开始以为是群面,结果进去面试官说要单面,问的比较常规,但是我感觉答得不好,大概率g了: 1.介绍自己 2.介绍自己的实习经历 3.说一下在实习经历中面临最大的困难以及如何解决 4.说一下物流运营岗位的职责(这个我说的不好) 5.说一下为什么选择顺丰而不是京东(面试官说我这个回答不够深入,说我的回答任何一个消费者也能说出来) 6.说一下顺丰和京东的区别 7.反问 💼公司岗位
-
 顺丰科技前端二面(30min)
顺丰科技前端二面(30min)抽象,太抽象了。 1. 自我介绍 2. 怎么学习的前端 3. 谈谈对CSS的理解,在学CSS过程有没有遇到过有意思的事情() 4. vue2和vue3学起来感觉有什么差别 5. setup函数的原理是什么? 6. 在印象中项目里最深刻的优化经历 7. 谈谈你对flex的认识 8. flex常用的属性 9. 谈谈你对three.js的认识
-
 顺丰前端线上二面(9.14)
顺丰前端线上二面(9.14)1. 学习前端的历程 2. 对闭包和执行上下文的理解 3. 闭包的应用场景 4. 断点续传和大文件上传 5. 如果上传大文件中用户刷新页面如何处理 6. webworker处理完之后如何和主线程通信 7. 自定义Hooks的封装理念 全程20分钟😂😂 #顺丰# #前端# #顺丰面试#
-
 顺丰 大数据开发 一面
顺丰 大数据开发 一面9.11 一面(30min) 纯八股: 介绍下hadoop(hdfs、mapreduce、yarn) 介绍下hbase 介绍下flink flink checkpoint、connect和union的区别、flink如何处理数据倾斜 介绍下kafka kafka如果有台机器挂掉会发生什么 链表反转 面试官全程表情和语气冷淡,体验不是很好..当然答得感觉也很一般
-
 顺丰供应链运营 面经
顺丰供应链运营 面经#运营人求职交流聚集地# 顺丰的面试流程不多,前前后后就一场线下群面+一场线上2v1面试(hr+业务)因为之前有了解过顺丰供应链做的很好,所以也还蛮期待能够了解顺丰供应链和物流体系,顺丰自己也有在做跨境电商物流和供应链,所以投递了顺丰供应链解决方案储备的岗位,应该是管培生项目 一面是线下群面,这是我秋招唯一参加的群面,全程约1小时,我们组有14个人,题目是继续开发冰墩墩吉祥物的ip价值(好像是不太
-
 顺丰科技——2024暑期实习面试
顺丰科技——2024暑期实习面试岗位:机器学习算法工程师 一面: 1.自我介绍 2.线程和进程的区别,什么时候用多进程,什么时候用多线程(这个属于给自挖坑了) 3.实习项目问题,项目目标是怎么定的,用的什么算法,算法原理是什么(这个算法偏控制论) 4.比赛问题:xgboost原理,特征怎么构造的,怎么选择的 5.有没有了解transform方面的(可惜我对nlp接触的太少) 6.课题问题:这个偏简单数据分析,都没啥建模,没说很多
-
 24顺丰暑期产品实习面经
24顺丰暑期产品实习面经6.1一面(22分钟) 自我介绍 介绍项目(背景以及整体情况) 产品1-100的过程中,1的阶段遇到了哪些问题 追问:具体解释用户容错率低的原因 追问:你是怎么去解决这些问题的 有考虑站票用户的点餐吗 自己接触的项目有不同场景的吗 对顺丰的哪块比较感兴趣 自己未来的职业规划 反问环节
-
第七章 机器学习 - 7.2 支持向量机
第一层、了解SVM 支持向量机,因其英文名为support vector machine,故一般简称SVM,通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。 1.1、线性分类 理解SVM,咱们必须先弄清楚一个概念:线性分类器。 1.1.1、分类标准 考虑一个二类的分类问题,数据点用x来表示,类别用y来
-
 顺丰产品一面,希望可以顺利通过!
顺丰产品一面,希望可以顺利通过!顺丰一面: 自我介绍 遇到什么困难的问题,怎么解决的? 互联网几大盈利模式 B站对你来说有什么痛点 顺丰你觉得有什么需要改进的? 你有什么要问的吗?
-
关于机器学习中的强化学习,什么是Q学习?
本文向大家介绍关于机器学习中的强化学习,什么是Q学习?,包括了关于机器学习中的强化学习,什么是Q学习?的使用技巧和注意事项,需要的朋友参考一下 Q学习是一种强化学习算法,其中包含一个“代理”,它采取达到最佳解决方案所需的行动。 强化学习是“半监督”机器学习算法的一部分。将输入数据集提供给强化学习算法时,它会从此类数据集学习,否则会从其经验和环境中学习。 当“强化代理人”执行某项操作时,将根据其是否
-
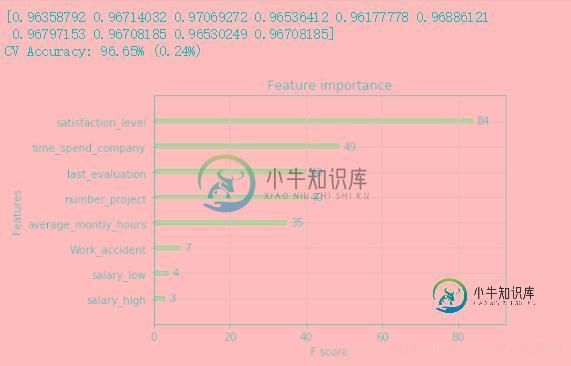 python机器学习库xgboost的使用
python机器学习库xgboost的使用本文向大家介绍python机器学习库xgboost的使用,包括了python机器学习库xgboost的使用的使用技巧和注意事项,需要的朋友参考一下 1.数据读取 利用原生xgboost库读取libsvm数据 使用sklearn读取libsvm数据 使用pandas读取完数据后在转化为标准形式 2.模型训练过程 1.未调参基线模型 使用xgboost原生库进行训练 使用XGBClassifier进行
-
 机器学习图像特征提取
机器学习图像特征提取在机器学习中,灰度图像的特征提取是一个难题。 我有一个灰色的图像,是用这个从彩色图像转换而来的。 我实际上需要从这张灰色图片中提取特征,因为下一部分将训练一个具有该特征的模型,以预测图像的彩色形式。 我们不能使用任何深度学习库 有一些方法,如快速筛选球。。。但我真的不知道如何才能为我的目标提取特征。 以上代码的输出就是真的。 有什么解决方案或想法吗?我该怎么办?
-
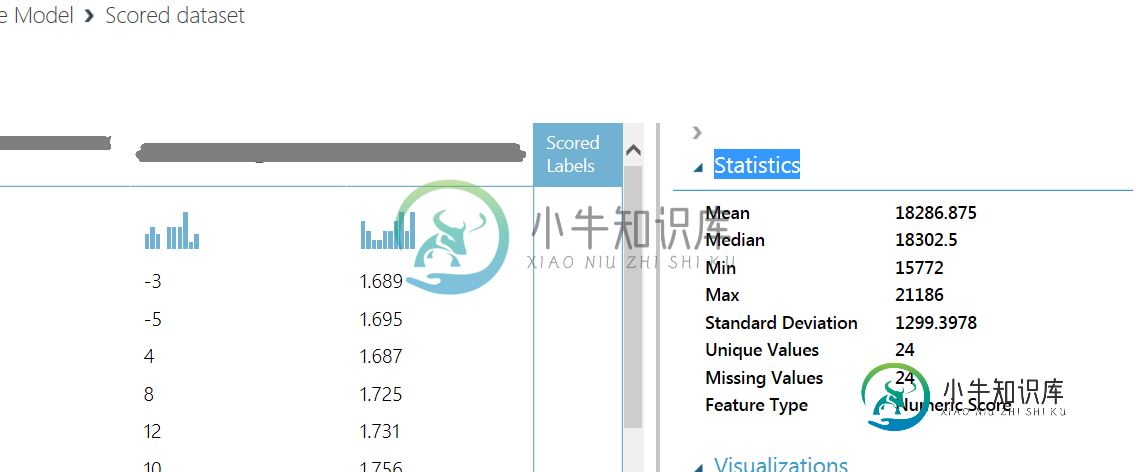 Azure机器学习-空分数结果
Azure机器学习-空分数结果我训练了一个模型,在测试集上的测试结果是可以的。现在,我已经将模型保存为“训练模型”,并将一个新的实验转化为一个新的数据集,以便在我没有实际值的情况下进行预测。 通常,训练过的模型给我一个每个实例的评分标签结果。但是现在,打分的标签结果是空的。另外,当我将得分结果转换为CSV时,得分标签列是空的。 更奇怪的是,当我查看score Visualize选项卡的统计数据时,我确实看到了得分值的统计数据。