《水木未来》专题
-
CSS下拉菜单项水平移动
我在stackoverflow上搜索此问题,但找不到任何内容。 我一直在用CSS制作一个下拉菜单。将鼠标悬停在下拉菜单上时,下拉项将水平显示,而不是垂直显示。 HTML CSS 如何垂直获取下拉列表项?
-
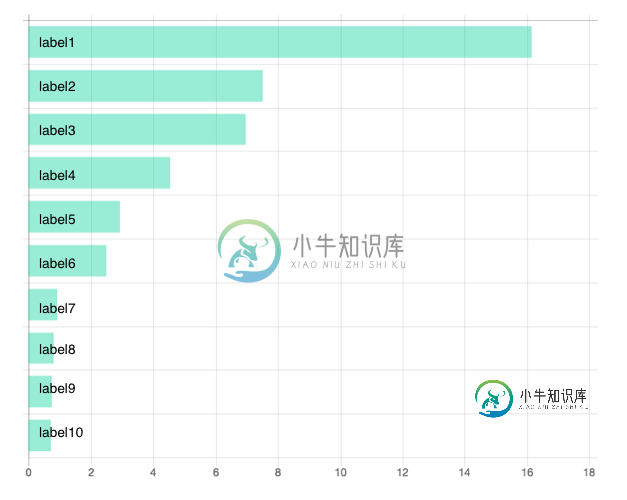 Chart.js-在水平栏内书写标签?
Chart.js-在水平栏内书写标签?在图表中。js,有没有办法在图表中的水平条内写入标签?例如: 在图表中是否有类似的情况。js? 谢谢
-
Flink:带有后期元素的水印
我在Flink中做实时流,其中Kafka是消息队列。我正在应用120秒的EventTimeSlidingWindow。和1秒的幻灯片。我还在事件时间的每秒插入水印。 我担心的是,如果元素在水印之后延迟出现,会发生什么?现在,我的情况是,Flink简单地丢弃了相应水印之后的消息。filnk是否提供了任何机制来处理此类延迟消息,例如维护单独的窗口?我也看过了文档,但我没有弄清楚。
-
Kafka连接水槽“直通”连接器
kafka jdbc接收器连接器是否支持将其使用的内容写入不同的主题。我正在寻找一种传递机制,如下图所示。如果没有,我可以链接一个接收器和源(从接收器写的地方读取),但我认为这不会有那么好的性能。也许我可以修改现有的接收器连接器来实现这一点?
-
Azure中的Applicatoin_Start、Init和水平缩放
在Azure中关于水平缩放的术语有点不清楚。 我们有一个“缓存刷新”特性,涉及到设置一个侦听器来订阅消息队列中的“主题”,这样它就会在接收到消息时刷新静态缓存。我们以前认为必须在HttpApplication.init事件中设置侦听器,每个实例都会调用该事件,但在意识到AppDomain中的所有HttpApplication实例都共享同一组静态变量之后,这就不再有意义了。 我的新理解是,即使在没有
-
keyBy和following运算符的Flink水印
Flink源函数引入水印,这些水印向下传递给下游操作符,根据这些操作符可以执行不同的基于时间的操作。对于使用多个流的操作员,将传入水印的最小值视为此时操作员的水印。 将源流拆分为多个逻辑流,然后将这些逻辑流传递给下游操作员(例如处理函数)。 Eg. 假设Process函数有4个子任务(例如),并且有100个关键组(假设),每个子任务处理25个关键组,即,等等。 如果从下午5点开始DriverStr
-
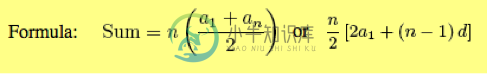 雨水收集的时间复杂性
雨水收集的时间复杂性从方法1开始,我一直在研究Leetcode问题的不同算法。如果阵列值是墙的高度,则需要计算总水域面积(列宽=1)。 第一种方法是找出每根立柱左右两侧最大墙高的最小高度,如果立柱高度小于最小值,则向给定立柱顶部加水。取最小值,因为这是收集的水能够达到的最高值。要计算每侧的最大值,需要对左侧和右侧进行n-1次遍历。 我用Python编写代码,但下面是根据Leetcode上给出的解决方案用C编写的代码。
-
水豚不与工厂女孩合作
我正在使用factory girl和capybara的minitest进行集成测试。当我不使用factory girl创建用户对象时,Capybara工作正常,如下所示: 但是一旦我尝试用工厂女孩创建一个用户,奇怪的事情就开始发生,比如访问方法和click_button方法停止工作。例如,这个测试似乎没有任何问题: 这是我的factories.rb: 下面是我得到的实际错误: 但是,如果我删除了u
-
无法单击水豚中的元素
问题:无法点击名为BT_SEARCH的元素 > click_button'Hae'返回:无法找到按钮"Hae"... click_link'Hae'返回:无法找到链接"Hae"... 查找(:xpath,“//输入[@name='BT\u SEARCH']”)。单击似乎找不到元素。 我无法修改源,也没有可用的id或类标签。此外,该页面使用ASP,我认为这是导致问题的原因。
-
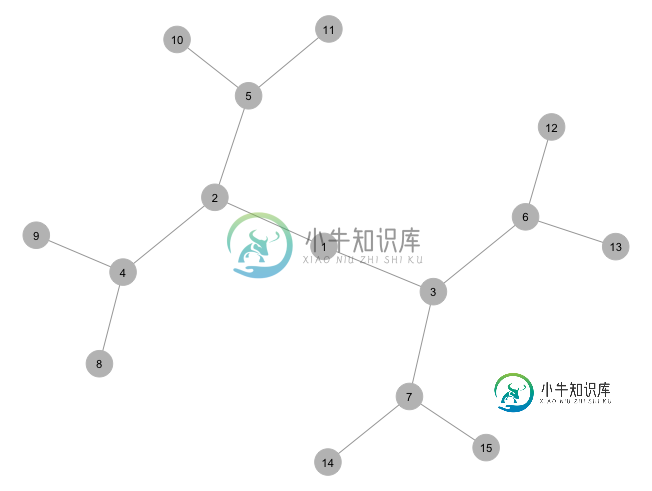 带igraph或ggnet2的水平树形图
带igraph或ggnet2的水平树形图我正在尝试使用 和 从维基百科中重现如下所示的概率树图。以下是我的开始, 它随机放置节点,以数字方式标记它们,并且边缘没有标签: 相反,我需要重新组织并标记边和节点,就像这样,只是将节点标签放在圆圈内:
-
iText向所选页面添加水印
我需要为每个有特定文本的页面添加水印,例如“删除过程”。 基于Bruno Lowagie的建议将水印直接添加到流中 迄今为止,PdfWatermark类具有: 如果我在自定义detectPages方法中将数字3添加到arrPages ArrayList中,则效果很好-它在第3页上显示所需的水印。 我遇到的问题是如何在文档中搜索文本字符串,我只能从PdfWriter writer或com访问文本字符
-
iText java-垂直和水平拆分表
我是一名iText java开发人员。我一直在处理大型表,现在我陷入了垂直拆分表的困境。 在iText In Action的第119页,尊敬的布鲁诺·洛瓦吉(我非常尊重这个家伙)解释了如何拆分一个大表,使列出现在两个不同的页面中。 我遵循了他的示例,当文档只有几行时,它工作得很好。 在我的例子中,我有100行,要求文档需要在几页中拆分100行,同时垂直拆分列。我按如下方式运行我的代码,但只显示前3
-
合法移动抽水马龙脚趾
所以我试图用Java编写一个tic tac toe游戏。大部分都完成了,但是,如果有人选择了一个已经被占用的空间,我不能归还无效的移动。 下面是我想弄清楚的代码。我认为既然空间是由数字0表示的(我的教授告诉我们的),有 在if语句中将阻止播放器重复该空格。
-
如何确定水槽拓扑方法?
我正在设置flume,但是不确定我们的用例应该使用什么样的拓扑。 我们基本上有两个web服务器,它们能够以每秒2000个条目的速度生成日志。每个条目的大小约为137字节。 目前我们已经使用rsyslog(写入tcp端口),php脚本将这些日志写入其中。我们在每个Web服务器上运行一个本地水槽代理,这些本地代理侦听tcp端口并将数据直接放入hdfs。 所以localhost:tcpport是“水槽源
-
执行水槽后Apache Flume卡住了
我需要帮助。 我已经下载了Apache Flume并安装在Hadoop之外,只是想尝试通过控制台进行netcat日志记录。我使用1.6.0版本。 这是我的confhttps://gist.github.com/ans-4175/297e2b4fc0a67d826b4b 这是我是如何开始的 但是仅在打印这些输出后就卡住了 对于简单的启动和安装有什么建议吗? 谢谢