《数据分析这么卷的吗?》专题
-
window.onerror()的用法与实例分析
本文向大家介绍window.onerror()的用法与实例分析,包括了window.onerror()的用法与实例分析的使用技巧和注意事项,需要的朋友参考一下 onerror语法使用 onerror 默认有三个入参: •msg: 错误信息 •url:错误所在文件 •line: 错误所在代码行,整型 window.onerror = function(msg, url, line){ // some
-
.NET中的属性用法分析
本文向大家介绍.NET中的属性用法分析,包括了.NET中的属性用法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了.NET中的属性用法。分享给大家供大家参考。具体分析如下: 1.What?什么是属性 属性是对字段的封装。当类中有了一个字段以后,为了控制这个字段对外的一些表现(例如可访问性,是只读?只写?或者对自读赋值做一些必要的验证等等)我们把这个字段私有化(private),同时留出
-
C# 反射(Reflection)的用处分析
本文向大家介绍C# 反射(Reflection)的用处分析,包括了C# 反射(Reflection)的用处分析的使用技巧和注意事项,需要的朋友参考一下 乱侃 作为一名新手,一直没有勇气去写一篇分享。原因有很多:诸如:自己水平有限、语言表达不准确、写出的东西没有一点技术点被人嘲笑。今天在公司听了内部员工的一个分享,其中最重要的一点是:提升自身水平的最佳的途径就是——交流。不管你是通过什
-
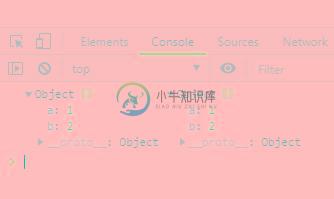 js的Object.assign用法示例分析
js的Object.assign用法示例分析本文向大家介绍js的Object.assign用法示例分析,包括了js的Object.assign用法示例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了js的Object.assign用法。分享给大家供大家参考,具体如下: 作用 Object.assign() 用于将所有可枚举的自有属性的值从一个或多个源对象复制到目标对象。它将返回目标对象。 语法 参数: target: 目标对象
-
jQuery遍历json的方法分析
本文向大家介绍jQuery遍历json的方法分析,包括了jQuery遍历json的方法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了jQuery遍历json的方法。分享给大家供大家参考,具体如下: ajax请求: 返回的内容在success的函数里面,所有的遍历操作都是在这里面操作的: for循环: for in 循环: 更多关于jQuery相关内容感兴趣的读者可查看本站专题:《jQ
-
MySQL Antelope和Barracuda的区别分析
本文向大家介绍MySQL Antelope和Barracuda的区别分析,包括了MySQL Antelope和Barracuda的区别分析的使用技巧和注意事项,需要的朋友参考一下 Antelope是innodb-base的文件格式,Barracude是innodb-plugin后引入的文件格式,同时Barracude也支持Antelope文件格式。两者区别在于: 文件格式 支持行格式 特性 Ant
-
Python yield的用法实例分析
本文向大家介绍Python yield的用法实例分析,包括了Python yield的用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python yield的用法。分享给大家供大家参考,具体如下: yield的英文单词意思是生产,刚接触Python的时候感到非常困惑,一直没弄明白yield的用法。 只是粗略的知道yield可以用来为一个函数返回值塞数据,比如下面的例子: 取出
-
使用@DateTimeFormat分析问题的DateTime
我在中使用时遇到问题。下面是我得到问题的代码片段 代码与EST时区的日期时间配合良好- 代码不工作,日期时间为IST时区- 异常-"无法将'java.lang.String'类型的值转换为所需类型'java.time.LocalDateTime';嵌套异常org.springframework.core.convert.ConversionFailedException:无法将值'2021-03-
-
分析删除时区的日期
如何从日期对象中移除时区。 请帮忙。
-
获取分析行错误的ObjectId
从上下文菜单中选择: 谢谢
-
19.1 Linux 的开机流程分析
19.1 Linux 的开机流程分析 如果想要多重开机,那要怎么安装系统?如果你的 root 密码忘记了,那要如何救援?如果你的默认登陆模式为图形界面,那要如何在开机时直接指定进入纯文本模式? 如果你因为 /etc/fstab 设置错误,导致无法顺利挂载根目录,那要如何在不重灌的情况下修订你的 /etc/fstab 让它变成正常?这些都需要了解开机流程, 那你说,这东西重不重要啊? 19.1.1
-
3.4 Reveal:分析iOS UI的利器
Reveal简介 Reveal是分析iOS应用UI的利器: Reveal能够在运行时调试和修改iOS应用程序。它能连接到应用程序,并允许开发者编辑各种用户界面参数,这反过来会立即反应在程序的UI上。就像用FireBug调试HTML页面一样,在不需要重写代码、重新构建和重新部署应用程序的情况下就能够调试和修改iOS用户界面。--InfoQ Reveal运行在Mac上,目前的最新版本是1.0.4,可以
-
什么时候调用C析构函数?
基本问题:程序何时在C中调用类的析构函数方法?有人告诉我,每当对象超出范围或受到时都会调用它 更具体的问题: 1)如果对象是通过指针创建的,并且该指针后来被删除或给定一个新的地址来指向,它所指向的对象是否调用其析构函数(假设没有其他东西指向它)? 2) 接下来是问题1,什么定义了对象何时超出范围(与对象何时离开给定的{block}无关)。换句话说,什么时候对链表中的对象调用析构函数? 3) 你想手
-
为什么Moshi把整数解析为double?
我试图使用Moshi+Kotlin解析一个设计得不是很好的API的json。出于某些原因,它将像71这样的数字解析为double。 第三方api有一个对象列表,可以类似于:{“foo”:[[1234567000,12]]}//long,int或{“foo”:[[1234567000,“string”,0,2]]}//long,string,int,int 由于第三方api,我有以下kotlin类:
-
这种时序数据vs sql server,Cassandra是个好选择吗?
考虑这种情况,我们收集金融市场数据(例如资金价格)并将其存储在sql表中。 正常情况下基金价格每天最多上涨一次,因此该表可以是: 当我们想要一些数据时,一个简单的查询就可以了: 然而,随着我们收集的数据越来越多,上述查询性能开始下降。我们尝试了重新索引和刷新统计数据。问题是,当我们检索大量数据时(例如,获取1000只基金的10年历史),可能需要相当长的时间。 我想知道在这种情况下(根本没有加入),