《数据分析这么卷的吗?》专题
-
ajax实现数据分页查询
本文向大家介绍ajax实现数据分页查询,包括了ajax实现数据分页查询的使用技巧和注意事项,需要的朋友参考一下 用ajax实现对数据库的查询以及对查询数据进行分页,供大家参考,具体内容如下 主页面代码 js代码 处理页面1 处理页面2 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
将一列数据分成三列
我在excel中有一个列,其中包含名字、姓氏和职位名称的混合。唯一可以观察到的模式是——在每一组3行中,每第1行是名字,第2行是姓氏,第3行是工作标题。我想创建3个不同的列,并隔离此数据示例数据: 我想要:约翰,布什,经理,作为一行,分别放在名字,姓氏和职务下面的三个不同的栏中。像- 我们如何才能完成这项任务?
-
javascript数据类型示例分享
本文向大家介绍javascript数据类型示例分享,包括了javascript数据类型示例分享的使用技巧和注意事项,需要的朋友参考一下 前面我们介绍了javascript的数据类型,今天我们通过一些例子再来温故一下,希望大家能够达到知新的地步。 END 童鞋们是否对javascript的数据类型有了新的认识了呢,希望大家能够喜欢。
-
Spring数据可分页和LIMIT/OFFSET
我正在考虑将我们传统的jpa/道解决方案迁移到Spring Data。 但是,我们的前端之一是SmartGWT,它们的数据库组件仅使用限制/偏移逐步加载数据,这使得难以使用Pagable。 这会导致问题,因为无法确定限制/偏移量最终是否可以转换为页码。(这可能因用户滚动方式、屏幕大小等而异)。 我查看了切片等,但无法找到在任何地方使用限制/偏移值的方法。 想知道有没有人有什么建议?最理想的情况是,
-
数据分支和应用转换
我刚刚开始使用数据流,对于如何实现分支,我没有什么问题。
-
火花数据帧范围分区
[新加入Spark]语言-Scala 根据文档,RangePartitioner对元素进行排序并将其划分为块,然后将块分发到不同的机器。下面的例子说明了它是如何工作的。 假设我们有一个数据框,有两列,一列(比如“a”)的连续值从1到1000。还有另一个数据帧具有相同的模式,但对应的列只有4个值30、250、500、900。(可以是任意值,从1到1000中随机选择) 如果我使用RangePartit
-
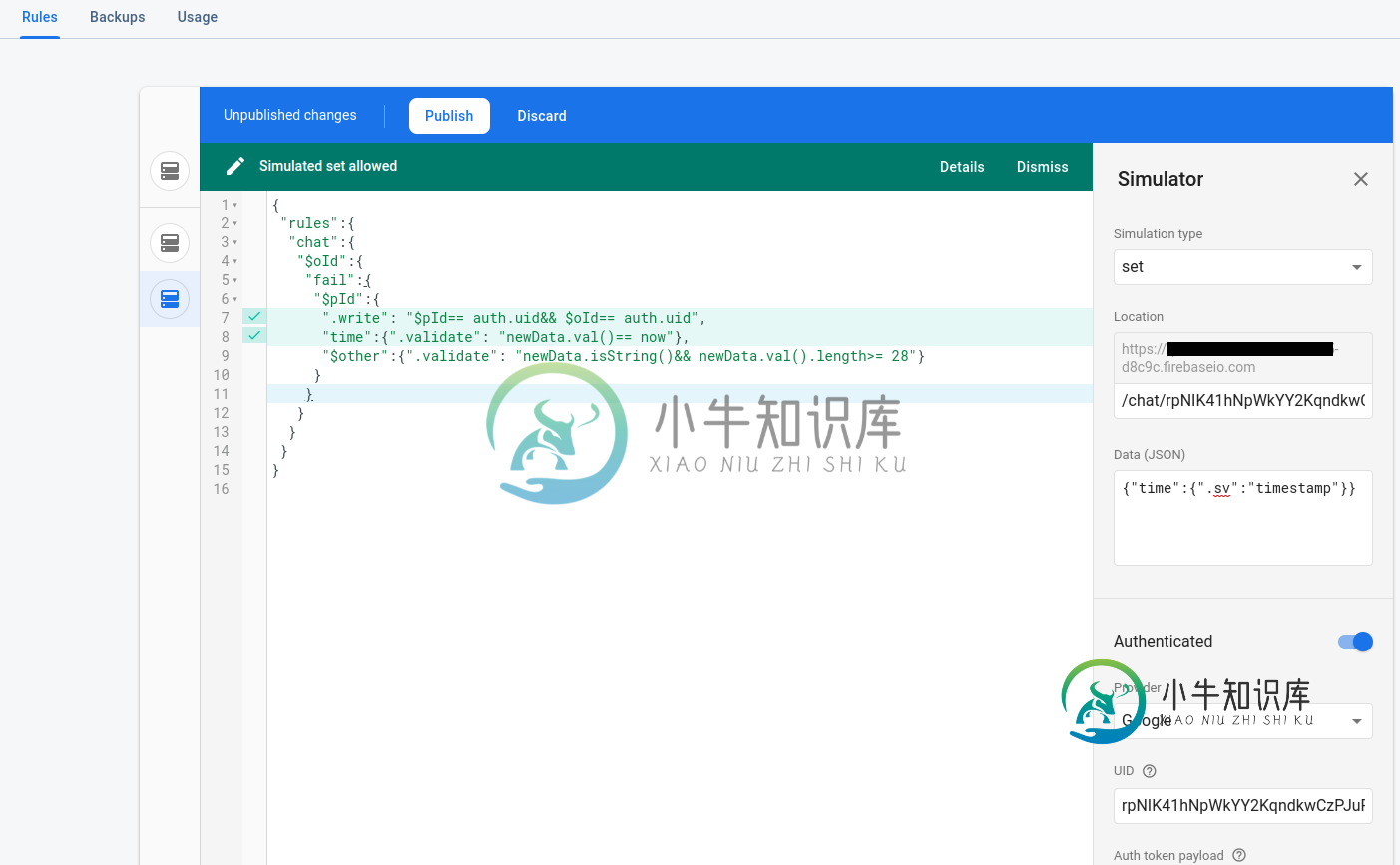 Firebase实时数据分片规则
Firebase实时数据分片规则更新2019-11-03:添加了错误的实时最小复制。在Chrome中加载链接后,点击ctrl shift i并选择控制台以查看输出。我已经尽力确保这正是我最初的项目代码所做的;我们看看情况是否如此,嗯?碎片的规则文件与下面的原始帖子相同。该源代码可在GitHub上获得。 原文: 这些规则在模拟器中工作,但在我真正的网络应用程序中不工作。模拟器路径和有效负载与下面数据库日志输出中显示的相同。 (将两
-
数据结构与算法 - 分治
分治和回溯其实本质上就是递归,只不过它是递归的其中一个细分类。可以认为 分治和回溯 最后就是 一种特殊的递归 或者是较为复杂的递归即可。 分治算法,即分而治之(divide and conquer,D&C),把 一个复杂问题 分成 两个或更多 的相同或相似 子问题,直到最后子问题可以简单地直接求解,最后将子问题的解合并为原问题的解。 分治法的核心思想就是,将原问题分解成小问题来求解,只要遵循三个步
-
图像分类数据集(Fashion-MNIST)
在介绍softmax回归的实现前我们先引入一个多类图像分类数据集。它将在后面的章节中被多次使用,以方便我们观察比较算法之间在模型精度和计算效率上的区别。图像分类数据集中最常用的是手写数字识别数据集MNIST [1]。但大部分模型在MNIST上的分类精度都超过了95%。为了更直观地观察算法之间的差异,我们将使用一个图像内容更加复杂的数据集Fashion-MNIST [2]。 获取数据集 首先导入本节
-
绘制分类数据(Plotting Categorical Data)
在前面的章节中,我们学习了散点图,hexbin图和kde图,用于分析研究中的连续变量。 当研究中的变量是分类时,这些图不适合。 当研究中的一个或两个变量是分类时,我们使用像striplot(),swarmplot()等那样的图。 Seaborn提供了这样做的界面。 分类散点图 在本节中,我们将了解分类散点图。 stripplot() 当研究中的一个变量是分类时,使用stripplot()。 它表示
-
 华为OD机试数据分类
华为OD机试数据分类数据分类 对一个数据a进行分类,分类方法为:此数据a(四个字节大小)的四个字节相加对一个给定的值b取模,如果得到的结果小于一个给定的值c,则数据a为有效类型,其类型为取模的值;如果得到的结果大于或者等于c,则数据a为无效类型。 比如一个数据a=0x01010101,b=3,按照分类方法计算(0x01+0x01+0x01+0x01)%3=1,所以如果c=2,则此a为有效类型,其类型为1,如果c=1,
-
如何将H2添加到Wildfly,这样我就可以看到数据库中的数据了?
然后我尝试了这种方法:1)为H2控制台部署一个预构建的WAR文件:https://www.cs.hs-rm.de/~knauf/javaee6/kuchen/h2console.war) 2)打开URL http://localhost:8080/h2console/h2 3)用户名/密码=“sa”登录 看看greeter应用程序添加的数据。运行以下SQL命令: 我试过了,但得到的信息 找不到表“
-
数据不平衡怎么办?
本文向大家介绍数据不平衡怎么办?相关面试题,主要包含被问及数据不平衡怎么办?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 使用正确的评估标准,当数据不平衡时可以采用精度,调用度,F1得分,MCC,AUC等评估指标。 重新采样数据集,如欠采样和过采样。欠采样通过减少冗余类的大小来平衡数据集。当数据量不足时采用过采样,尝试通过增加稀有样本的数量来平衡数据集,通过使用重复,自举,SMOTE等方
-
什么是数据库会话?
问题内容: 我了解对数据库事务处理概念的一般理解。我们访问事务内的数据库以确保ACID属性。 在Hibernate中,有一个称为会话的概念。会话的用途是什么?什么时候应该在两个会话中而不是在同一会话中进行数据库访问? 为了进一步说明,我已经看到了hibernate代码, 从会话工厂获取会话 打开会议 开始交易 提交交易 关闭会议 我需要知道的是在这里召开会议的重要性是什么?为什么没有像交易工厂这样
-
 数据可视化是什么
数据可视化是什么主要内容:数据可视化,数据可视化应用场景如果将文本数据与图表数据相比较,人类的思维模式更适合于理解后者,原因在于图表数据更加直观且形象化,它对于人类视觉的冲击更强,这种使用图表来表示数据的方法被叫做数据可视化。 图1:数据可视化 当使用图表来表示数据时,我们可以更有效地分析数据,并根据分析做出相应的决策。在学习 Matplotlib 之前,了解什么是数据可视化是非常有必要的。 数据可视化 图表为更好地探索、分析数据提供了一种直观的方