《数据分析这么卷的吗?》专题
-
angular-ui-router 将数据解析为状态
本文向大家介绍angular-ui-router 将数据解析为状态,包括了angular-ui-router 将数据解析为状态的使用技巧和注意事项,需要的朋友参考一下 示例 您可以resolve在转换到状态时将数据转换为状态,通常在状态需要使用该数据或在某些提供的输入需要进行身份验证时解析为状态时非常有用。 定义状态时,您需要提供要解析到.resolve属性中的值的映射,每个解析后的值都应具有一个
-
MySQL数据库锁机制原理解析
本文向大家介绍MySQL数据库锁机制原理解析,包括了MySQL数据库锁机制原理解析的使用技巧和注意事项,需要的朋友参考一下 在并发访问情况下,很有可能出现不可重复读等等读现象。为了更好的应对高并发,封锁、时间戳、乐观并发控制(乐观锁)、悲观并发控制(悲观锁)都是并发控制采用的主要技术方式。 锁分类 ①、按操作划分:DML锁,DDL锁 ②、按锁的粒度划分:表级锁、行级锁、页级锁 ③、按锁级别划分:共
-
Crashlytics NDK 解析 NDK 崩溃数据失败
我正在通过ndk构建一个支持本地构建的Android应用程序。此外,我使用Crashlytics NDK来获取jni和cpp崩溃的崩溃报告。有时,Crashlytics NDK无法为cpp类中的崩溃发送崩溃报告(java和jni工作得很好)。 这似乎是crashlytics ndk框架中的一个错误。 正在使用以下版本: Crashlytics Gradle配置: 有推荐吗?
-
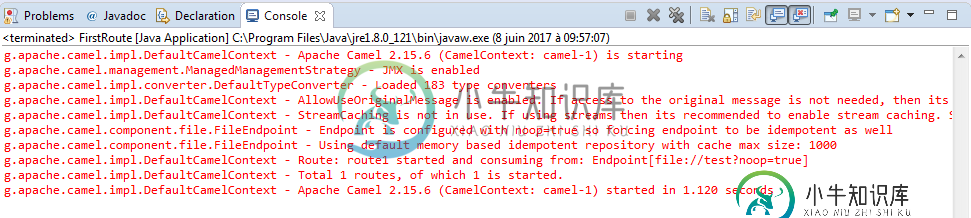 在apache Camel中解析csv数据格式
在apache Camel中解析csv数据格式我遵循了《骆驼在行动》一书中的一个例子。如何封送和反封送csv数据格式。但是,我希望用(逗号分隔的分隔符)和拆分正文来解封csv文件。然后,我将使用基于内容的根据所需任务分发消息。事实上,第一个简单的例子对我不起作用。我使用了camel2.15.6(camel-core,camel-context,camel-csv,commons-csv)和Java7。
-
 数据模型面试题与解析1
数据模型面试题与解析1面试高频题1: 题目:介绍一下k-means,你的数据如何处理,模型的输出是什么? 答案解析: 介绍kmeans: 第一步:数据归一化、离群点处理后,随机选择k个聚类质心 第二步:所有数据点关联划分到离自己最近的质心,形成k个簇; 第三步:重新计算每个簇的质心; 重复第二步、第三步,直到簇不发生变化或达到最大迭代次数; 数据如何处理: 为了防止均值和方差大的维度将对数据的聚类产生决定性影响,所以在
-
 数据处理面试题与解析1
数据处理面试题与解析1面试高频题1: 题目:处理噪声数据方法 答案解析: 1、分箱 分箱方法是一种简单常用的预处理方法,通过考察相邻数据来确定最终值。所谓“分箱”,实际上就是按照属性值划分的子区间,如果一个属性值处于某个子区间范围内,就称把该属性值放进这个子区间所代表的“箱子”内。把待处理的数据(某列属性值)按照一定的规则放进一些箱子中,考察每一个箱子中的数据,采用某种方法分别对各个箱子中的数据进行处理。在采用分箱技术
-
javascript - 如何解析stream流式json数据?
问题:假设有一个json对象如下: 现在以上对象在服务端被格式化stream流返回(一个请求,分为多个片段返回),并且每个片段的内容都是不确定的,前端接收到内容后,都需要用JSON.parse解析代码,并渲染到界面上。 假设服务端返回的每个片段可能如下: 从上面可以看出,服务端每个片段返回到可能是总的json中任意片段长度的字符串,前端需要每次都能解析出来,我的理解是每次都自动拼接对应的后续缺失的
-
JavaScript中的这种做法叫什么?
问题内容: 当您将JavaScript代码包装在这样的函数中时: 我注意到,这为许多网页上的我解决了范围界定问题。这种做法叫什么? 问题答案: 该模式称为 自我调用 ( self-invocation) ,一种 自我调用功能 。它可以创建一个闭包,但这是模式的效果(也许是预期的效果),而不是模式本身。
-
这些元属性是做什么的?
不懂的问题。我有一个chrome扩展,当它访问一个API时,它会返回一些奇怪的结果。 我认为问题出在从DOM中提取的用户ID上。 这些元素的目的究竟是什么? 为什么它们末尾的一些ID是相同的,而另一些ID却是不同的呢?
-
为什么这是假的?SomeClass.method是SomeClass.method
问题内容: 以下面的代码为例: 示例1:我猜他们是同一对象。每次引用时,Python都会复制该方法吗? 示例2:预期。 示例3:预期,因为它们是不同的对象。 示例4:为什么此输出与示例2不匹配? 问题答案: 范例1: 是一种 未绑定的方法 。这些在当今的Python中甚至都不存在,因此请认为这是无用的历史课程。 每次引用时,Python都会复制该方法吗? 是的,或多或少。这是通过描述符协议完成的。
-
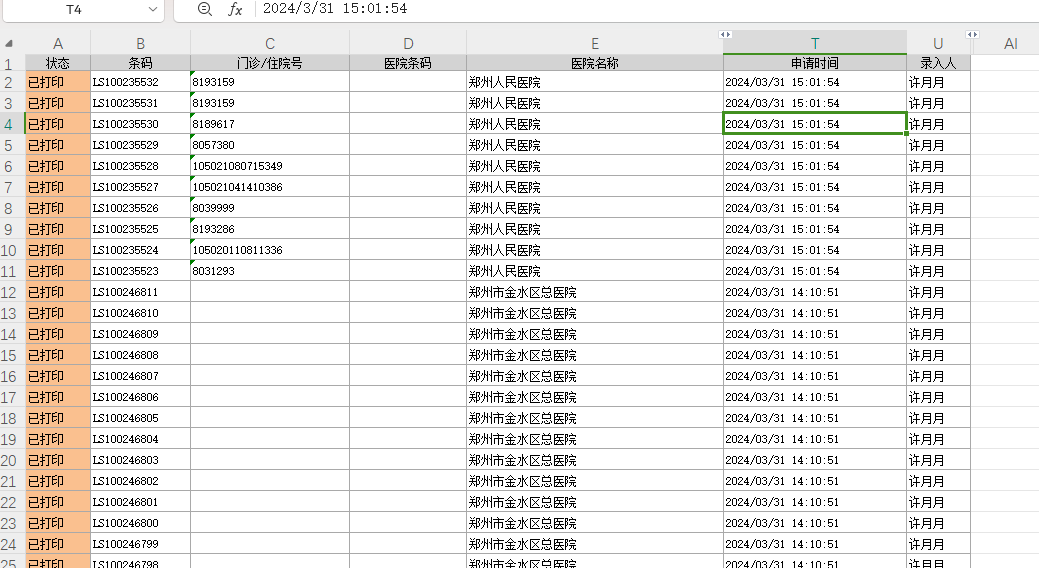 这种excel的功能怎么实现?
这种excel的功能怎么实现?第一个表是医院记录,第二个表是业务人负责的医院,怎么在第一个表增一个“业务员”列,分别从第二个表对应上是哪个业务员?这怎么实现? https://www.chunshu.net/angpu/%E4%B8%B4%E6%97%B6%E4%BA%BA%E5%... 还有一个问题:我想把下面第一个表里的统计到第二个表里,但是就是申请时间统计,比如‘2024/3/1’里就填A在第一张表里所以是2024/3/
-
c++ - C++的这些宏怎么理解?
C++的这些宏怎么理解 下面代码出自:https://github.com/sharkdp/dbg-macro的dbg.h头文件中 我尝试用渐进的方式去理解,尝试如下代码去理解前两行宏 发现代码不可编译,故尝试问之
-
python3 - 这里的job.get()是什么含义?
代码来源 https://medium.com/geekculture/python-multiprocessing-with-ou... 这里的job.get()是表达什么呢?jobs是个list,每个job也不是queue,list的元素没有get方法,如何理解呢?
-
 前端 - 这样的布局怎么写?
前端 - 这样的布局怎么写?宽度不定,间距相同,左对齐。
-
有推荐的Java性能分析教程吗?
问题内容: 是否有推荐的Java应用程序性能分析教程? 我现在在分析时使用JProfiler和Eclipse 测试与性能工具平台(TPTP)。但是,尽管配备了出色的武器,但作为Java剖析新手还是新手,我仍然缺少指出瓶颈的一般理论和技能。 问题答案: 概要分析是一门多学科的学科。 比较流行的一种是您要进行 测量 。也就是说,您尝试查看每个函数花费多长时间和/或被调用多少次。显然,如果一个函数花费很