《数据分析这么卷的吗?》专题
-
 小厂提示词数据分析
小厂提示词数据分析自我介绍 介绍面试题:数据分析相关需求,使用AI辅助,提供提示词文本 对数据分析的理解 你做过的一个数据分析项目 得到了什么结果 预设场景怎么分析,设计提示词 用的AI工具 文本场景与数据分析场景AI使用的不同 北京实习问题 反问
-
 Pdd数据分析已挂二面
Pdd数据分析已挂二面🕒岗位/面试时间 🤔面试感受 一面4月23日,是一个年轻小哥,长得很帅人也非常好,水平很高感觉提示也特别到位,全程体验良好,问了一道概率一道python 一道SQL 隔两天约了二面 吐槽一下二面改了三次时间,最后定的4月26号 二面面试官看起来非常不专心,一开始迟到了几分钟,然后刚开始他手机一直响,感觉漫不经心还在玩手机,关于问简历感觉非常不专业,因为他自己不懂还要重复性的问好几遍,他自己就是
-
分析或未分析,选择什么
问题内容: 我仅使用kibana搜索ElasticSearch,并且我有几个只能接受几个值的字段(最坏的情况,服务器名,30个不同的值)。 我确实了解分析对像这样的更大,更复杂的字段执行的操作,但是对于那些简单的小字段,我却无法理解分析/未分析字段的优点/缺点。 那么,对于“有限的一组值”字段(例如,服务器名:server [0-9] *,没有特殊字符可以打破),使用analyd和not_anal
-
这种数据格式使用什么类型的数据结构?
以下是我正在使用的数据结构示例- 所有数据都在字符串中,包括子列表都是字符串值 子列表值可能与其他子列表值重复 我需要能够获得大小并遍历子列表 本质上,每个子列表都有我需要获取的引用ID,以及与该列表关联的子列表ID 我不知道哪一个最合适。我可能会先选择我能实施的那个。 我应该使用、、还是与列表一起使用?
-
 数据分析日常实习面试分享
数据分析日常实习面试分享字节数据分析实习面试(抖音电商) 一面: 表user_log,有user_id, time,求每天用户新增数,次日留存率、30日留存率 ABTest的流程,P值,做留存率的ABTest,选择什么检验,卡方检验的应用场景 逻辑回归的损失函数 出现过拟合的原因 三天后给了感谢信 快手数据分析师(短视频用户增长部门) 一面: 两个SQL题目,都还比较简单,主要涉及到group by和日期函数的处理,还有
-
 快手数据分析校招面经分享
快手数据分析校招面经分享分享一下去年成功面试进快手的面试经验,希望对大家有帮助 1)自我介绍 2)深挖过往实习经历: 1.数据异动问题:假如一直关心的指标在某个时间点下跌很多,怎么分析呢? 2.评估方式问题:大型活动无法上ab实验,那么如何评估活动的效果呢? 3.指标选择问题:如何构建关键的指标链路,如何展示? 3)统计知识考察: 1.如何通俗地解释p值的意义? 2.解释一类错误和二类错误 3.了解染色逻辑吗? 4)偏智
-
 数据分析岗高频SQL问题分享
数据分析岗高频SQL问题分享#牛客创作赏金赛# 面过的数据分析也有几十场了,给大家汇总一下亲历的高频考点,面试前一定要反复练习哦 问题清单: 1. SQL查询过慢,如何解决? 2. union v.s. Union all 3. SQL执行顺序 4. 视图 v.s. 表 5. 第一范数,第二范式,第三范式
-
为什么Base64编码的数据压缩得这么差?
原始文件:429,7 MIB 通过 它和压缩通过: 原始压缩xz文件: 几乎没有时间=预期的大小增加 所以可以观察到的是: xz压缩的☺真好 base64-编码的数据压缩不好,它比未编码的压缩文件大2倍 base64-then-compress明显比compress-then-base64差且慢 我知道base64然后压缩文件是没有意义的,但大多数情况下,人们无法控制输入文件,而且我会认为,由于b
-
数据科学家,数据工程师,数据分析师之间的区别。
本文向大家介绍数据科学家,数据工程师,数据分析师之间的区别。,包括了数据科学家,数据工程师,数据分析师之间的区别。的使用技巧和注意事项,需要的朋友参考一下 数据科学家,数据工程师和数据分析师是信息技术公司中的各种职位档案。 数据科学家 数据科学家是一个非常特权的工作,负责监督整体功能,提供监督以及对信息,数据的未来显示的关注。 数据工程师 数据工程师专注于技术优化,以所需格式构建数据等。 数据分析
-
Serverless 数据分析,Kinesis Firehose 持久化数据到 S3
based on:serverless-kinesis-streams, but auto create Kinesis streams 在尝试了使用 Kinesis Stream 处理数据之后,我发现它并不能做什么。接着,便开始找寻其它方式,其中一个就是:Amazon Kinesis Firehose Amazon Kinesis Firehose 是将流数据加载到 AWS 的最简单方式。它可以
-
Spring对不同数据的批处理分析
我有一个场景,文件有不同的类型。文件分为页眉、正文和页脚三部分。标题可以是2类型dipend,根据标题大小,我需要使用标记器和范围来解析内容。 页脚也一样,这取决于正文大小和页脚长度,需要解析页脚内容。 我查看了PatternMatchingCompositeLineMapper和fixedlenghttokenizer,但没有找到为范围指定条件的方法,也没有找到在页脚中共享正文内容以检查长度的方
-
深入分析Mongodb数据的导入导出
本文向大家介绍深入分析Mongodb数据的导入导出,包括了深入分析Mongodb数据的导入导出的使用技巧和注意事项,需要的朋友参考一下 一、Mongodb导出工具mongoexport Mongodb中的mongoexport工具可以把一个collection导出成JSON格式或CSV格式的文件。可以通过参数指定导出的数据项,也可以根据指定的条件导出数据。 mongoexport具体用法 参数说明
-
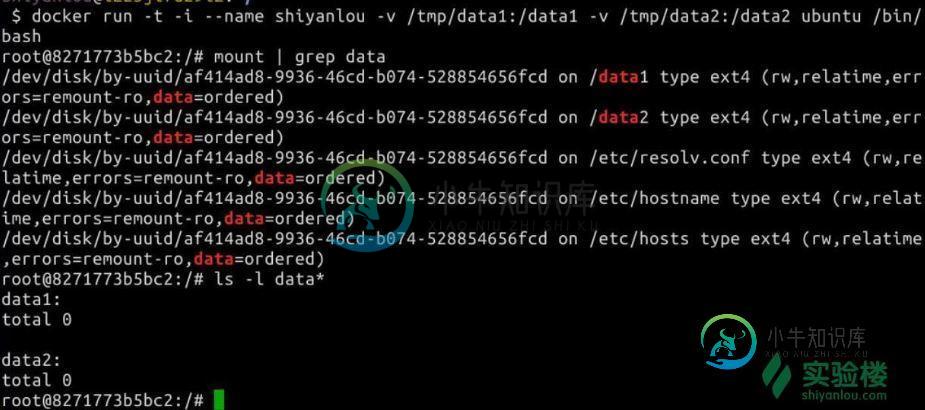 详解Docker 数据卷管理
详解Docker 数据卷管理本文向大家介绍详解Docker 数据卷管理,包括了详解Docker 数据卷管理的使用技巧和注意事项,需要的朋友参考一下 Docker中的数据可以存储在类似于虚拟机磁盘的介质中,在Docker中称为数据卷(Data Volume)。数据卷可以用来存储Docker应用的数据,也可以用来在Docker容器间进行数据共享。 数据卷呈现给Docker容器的形式就是一个目录,支持多个容器间共享,修改也不会影响
-
4.2.2 数据卷容器(--volumes-from)
数据卷容器 --volumes-from 顾名思义,就是从另一个容器当中挂载容器中已经创建好的数据卷。 如果你有一些持续更新的数据需要在容器之间共享,最好创建数据卷容器。 数据卷容器,其实就是一个正常的容器,专门用来提供数据卷供其它容器挂载的。 我们首先先创建一个数据卷容器 $ sudo docker run -d -v /dbdata --name dbdata training/postgre
-
 Python常用数据分析模块原理解析
Python常用数据分析模块原理解析本文向大家介绍Python常用数据分析模块原理解析,包括了Python常用数据分析模块原理解析的使用技巧和注意事项,需要的朋友参考一下 前言 python是一门优秀的编程语言,而是python成为数据分析软件的是因为python强大的扩展模块。也就是这些python的扩展包让python可以做数据分析,主要包括numpy,scipy,pandas,matplotlib,scikit-learn等等