《数据分析这么卷的吗?》专题
-
数据分片
数据分片是 Apache ShardingSphere 的基础能力,本节以数据分片的使用举例。 除数据分片之外,读写分离、数据加密、影子库压测等功能的使用方法完全一致,只要配置相应的规则即可。多规则可以叠加配置。 详情请参见配置手册。
-
数据分片
使用实战 前置工作 启动MySQL服务 创建MySQL数据库(参考ShardingProxy数据源配置规则) 为ShardingProxy创建一个拥有创建权限的角色或者用户 启动Zookeeper服务 (为了持久化配置) 启动ShardingProxy 添加 mode 和 authentication 配置参数到 server.yaml (请参考相关example案例) 启动 ShardingPr
-
数据分片
定义 Sharding Table Rule SHOW SHARDING TABLE tableRule | RULES [FROM schemaName] SHOW SHARDING ALGORITHMS [FROM schemaName] tableRule: RULE tableName 支持查询所有数据分片规则和指定表查询 支持查询所有分片算法 Sharding Bindin
-
数据分片
定义 Sharding Table Rule CREATE SHARDING TABLE RULE shardingTableRuleDefinition [, shardingTableRuleDefinition] ... ALTER SHARDING TABLE RULE shardingTableRuleDefinition [, shardingTableRuleDefinition]
-
数据分片
背景 传统的将数据集中存储至单一数据节点的解决方案,在性能、可用性和运维成本这三方面已经难于满足互联网的海量数据场景。 从性能方面来说,由于关系型数据库大多采用 B+ 树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降;同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。 从可用性的方面来讲,服务化的无状态型,能够达到较小成本的随
-
程序参数 - 参数分析
匹配可以用来解析简单的参数: use std::env; fn increase(number: i32) { println!("{}", number + 1); } fn decrease(number: i32) { println!("{}", number - 1); } fn help() { println!("usage: match_args <stri
-
什么是词法分析?请描述下js词法分析的过程?
本文向大家介绍什么是词法分析?请描述下js词法分析的过程?相关面试题,主要包含被问及什么是词法分析?请描述下js词法分析的过程?时的应答技巧和注意事项,需要的朋友参考一下 词法分析指的是js引擎在执行前的编译过程之一。 词法分析和分词其实都是对js代码分割的一个过程。 词法分析大概分为三步骤,分析参数,分析变量声明,分析函数声明。 首先如果存在函数,分析函数的参数分别是什么。 其次 分析每一个变量
-
RequestHandler 的分析
前面一小节谈到了Application 类,这里再来看看 RequestHandler 类。 从上一节的流程可以看出,RequestHandler 类把 _execute 方法暴露给了 application 对象,在这个方法里完成了请求的具体分发和处理。因此,我主要看这一方法(当然还包括__init__),其它方法在开发应用时自然会用到,还是比较实用的,比如header,cookie,get/p
-
为什么解析依赖项“类路径”这么慢?
为什么当我将apache commons编解码器和apache commons io依赖项添加到我的项目中时,所有的gradle任务都变得非常慢(超过5分钟)?明确地说,执行构建任务仍然有效,只是需要很长时间。慢时,分级输出为 如果我不包括最后两个类路径依赖项(编解码器和io),buildscript会快得多。我正在通过Gradlew使用Gradle1.10。
-
Python数据分析之如何利用pandas查询数据示例代码
本文向大家介绍Python数据分析之如何利用pandas查询数据示例代码,包括了Python数据分析之如何利用pandas查询数据示例代码的使用技巧和注意事项,需要的朋友参考一下 前言 在数据分析领域,最热门的莫过于Python和R语言,本文将详细给大家介绍关于Python利用pandas查询数据的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧。 示例代码 这里的查询数据
-
Dockerfile中卷的用途是什么
我试图更深入地了解Docker的卷,我很难弄清楚以下方面的差异/用例: docker volume create(docker卷创建)命令 docker run-v/path:/host\u路径 Dockerfile文件中的卷条目 我特别不理解如果将卷条目与v标志结合在一起会发生什么。
-
将spark数据拆分为分区并将这些分区并行写入磁盘
问题概要:假设我有300 GB的数据正在AWS中的EMR集群上用火花处理。这些数据有三个属性,用于在Hive中使用的文件系统上进行分区:日期、小时和(比方说)另一个。我想以最小化写入文件数量的方式将此数据写入fs。 我现在正在做的是获取日期、小时、另一个时间的不同组合,以及有多少行构成组合的计数。我将它们收集到驱动程序上的列表中,并遍历列表,为每个组合构建一个新的DataFrame,使用行数重新分
-
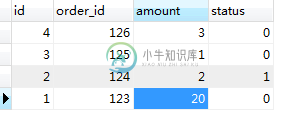 分析Mysql事务和数据的一致性处理问题
分析Mysql事务和数据的一致性处理问题本文向大家介绍分析Mysql事务和数据的一致性处理问题,包括了分析Mysql事务和数据的一致性处理问题的使用技巧和注意事项,需要的朋友参考一下 这篇文章通过安全性,用法,并发处理等方便详细分析了Mysql事务和数据的一致性处理问题,以下就是全部内容: 在工作中,我们经常会遇到这样的问题,需要更新库存,当我们查询到可用的库存准备修改时,这时,其他的用户可能已经对这个库存数据进行修改了,导致,我们查询
-
 vue组件之间数据传递的方法实例分析
vue组件之间数据传递的方法实例分析本文向大家介绍vue组件之间数据传递的方法实例分析,包括了vue组件之间数据传递的方法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了vue组件之间数据传递的方法。分享给大家供大家参考,具体如下: 1、props:父组件 -->传值到子组件 app.vue是父组件 ,其它组件是子组件,把父组件值传递给子组件需要使用 =>props 在父组件(App.vue)定义一个属性(变量)se
-
通过源码分析Vue的双向数据绑定详解
本文向大家介绍通过源码分析Vue的双向数据绑定详解,包括了通过源码分析Vue的双向数据绑定详解的使用技巧和注意事项,需要的朋友参考一下 前言 虽然工作中一直使用Vue作为基础库,但是对于其实现机理仅限于道听途说,这样对长期的技术发展很不利。所以最近攻读了其源码的一部分,先把双向数据绑定这一块的内容给整理一下,也算是一种学习的反刍。 本篇文章的Vue源码版本为v2.2.0开发版。 Vue源码的整体架