《数据分析这么卷的吗?》专题
-
 招联>数据分析岗位<实习1面
招联>数据分析岗位<实习1面1自我介绍 2介绍一下自己的成绩情况,荣誉情况,项目情况 (这里提了一嘴我是班长,然后班里组织了什么活动和什么荣誉还有职责) 3数据预处理 4数模竞赛的细问(选用了什么模型,流程,得到什么结果,为什么) 5数仓的维表事实表(给我问懵了,我寻思数仓课本上没有啊。。。。) 6数仓的底层实现,答出来了底层架构Kafka,底层语言,然后分层ods啥的我提了一嘴说不上来了 7kmean的评价指标我直接答的用
-
 面经|兴盛优选数据分析二面
面经|兴盛优选数据分析二面一面面的稀碎,一面面完一周之后hr联系说重新做了人才盘点,希望继续推进后续面试。这次是hr面,问题比较常规。 1.自我介绍 2.离职原因 3.收到offer情况 期间有收到但拒绝掉了,最近也在推动其他 4.看机会比较看重的三个方面 岗位匹配度+发展+薪资 5.工作和上学时间重叠,是管培生吗?签合同时间 校招提前入职实习,签合同是在毕业之后 6.实习和毕业后做的工作差别大吗? 会有差别,组织架构调整
-
Kubernetes卷中的AccessModes是什么
我试图理解Kubernetes的访问模式。 根据Kubernetes文档,访问模式为: 卷插件支持 有人能解释一下这里发生了什么吗?如果可能的话,请给我提供例子/博客,看看之间的区别?大多数的博客,只是简单地介绍了PV、PVC和访问方式。
-
具有命名卷或匿名卷的“数据容器”-概念问题?(讨论)
问题内容: a)匿名卷 使用数据容器时,您可以使用像这样的匿名卷 b)名称卷 或者您可以使用这样的命名卷 我通常会选择b),并且想讨论/解释这两个概念上的问题/缺点。那么优点和缺点是什么。 我们可以将其进行比较的方面可能是: 可移植性 数据容器的可升级性(为什么我们要升级容器?) 启动/停止(继续)兼容性? 多栈问题? 效率(卷的重用) 这个问题在这个问题上引起了讨论https://stackov
-
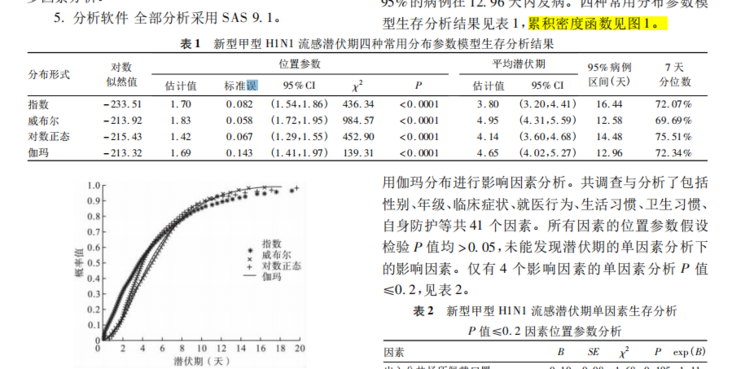 程序员 - SAS生存分析LIFEREG做区间删失数据的参数分布后,怎么求出结局变量的百分位数啊?
程序员 - SAS生存分析LIFEREG做区间删失数据的参数分布后,怎么求出结局变量的百分位数啊?SAS生存分析LIFEREG做区间删失数据(如潜伏期)的参数分布后,对于得到的各类参数分布模型,怎么估计潜伏期的百分位数呢? 比如这篇文献,右边的潜伏期百分位数数据怎么得到呀??? 还有参数分布的累积密度分布函数?/? 求大佬带带
-
什么是算法的摊销分析?
问题内容: 与渐进分析有何不同?您何时使用它,为什么? 我读过一些写得不错的文章,例如: http://www.ugrad.cs.ubc.ca/~cs320/2010W2/handouts/aa-nutshell.pdf http://www.cs.princeton.edu/~fiebrink/423/AmortizedAnalysisExplained_Fiebrink.pdf 但我仍然没有完
-
用带卷的普罗米修斯存储数据
我应该在values.yaml之外添加一些东西吗?
-
8 种常用的 NoSQL 数据库系统对比分析
本文向大家介绍8 种常用的 NoSQL 数据库系统对比分析,包括了8 种常用的 NoSQL 数据库系统对比分析的使用技巧和注意事项,需要的朋友参考一下 Kristóf Kovács 是一位软件架构师和咨询顾问,他最近发布了一片对比各种类型NoSQL数据库的文章。 虽然SQL数据库是非常有用的工具,但经历了15年的一支独秀之后垄断即将被打破。这只是时间问题:被迫使用关系数据库,但最终发现不能适应需求
-
Windows平台Python连接sqlite3数据库的方法分析
本文向大家介绍Windows平台Python连接sqlite3数据库的方法分析,包括了Windows平台Python连接sqlite3数据库的方法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Windows平台Python连接sqlite3数据库的方法。分享给大家供大家参考,具体如下: 之前没有接触过sqlite数据库,只是听到同事聊起这个。 有一次,手机端同事让我帮着写个sql,后
-
选择python进行数据分析的理由和优势
本文向大家介绍选择python进行数据分析的理由和优势,包括了选择python进行数据分析的理由和优势的使用技巧和注意事项,需要的朋友参考一下 1、python大量的库为数据分析提供了完整的工具集 2、比起MATLAB、R语言等其他主要用于数据分析语言,python语言功能更加健全 3、python库一直在增加,算法的实现采取的方法更加创新 4、python能很方便的对接其他语言,比如c、java
-
你是如何给自媒体号做数据分析的?
本文向大家介绍你是如何给自媒体号做数据分析的?相关面试题,主要包含被问及你是如何给自媒体号做数据分析的?时的应答技巧和注意事项,需要的朋友参考一下 数据指标根据平台不同略有差异,这里以微信为例。 数据维度分为三个方面:用户属性,图文数据,其他(菜单栏数据,消息分析,接口网页),分析思维分三步走,收集汇总,整理分析,制定策略。 用户属性:收集清晰的用户数据,完整用户画像以及用户行为。公号里的用户分析
-
分析数据组织时出错。json。JSONException:java类型的值
我正在创建一个应用程序,其中用户输入数据进行搜索,然后应用程序将其发送到服务器,然后服务器将搜索结果发送回客户端。 我得到了错误,我不能理解它的意思。我从服务器得到确切的结果。 这是我的网络代码从那里的应用程序和这里是链接到完整的代码 这是我的服务器端代码 我还更改了echo json_编码($json_输出);打印(json_编码($json_输出));但产出仍然没有变化 这是我从logcat得
-
SSDT数据库项目代码分析与SonarQube的集成
问题:如何让SonarQube从代码分析结果生成报告?
-
 拼多多数据分析师面试--无语的HR面
拼多多数据分析师面试--无语的HR面首先,说下背景 我是22年毕业,所以是社招面的拼多多 并不是我主动投递,是拼多多的人主动在boss直聘联系我,邀请我进行的面试 在这之前,boss上拼多多已经有多个岗位联系过我 但因为考虑到他们一天工作12小时,一周6天,没有双休,我都没有回应 直到这个岗位,因为看起来确实和我很匹配,我也很感兴趣,才答应的面试 技术面虽然有点波折,但最后也都通过了 没想到最后遇到了 hr,算是我平生仅见的人物了,
-
 大数据分析师应该具备的知识架构
大数据分析师应该具备的知识架构算法选取在算法选取方面,个人感觉也是要结合业务来实施。首先,要弄清楚业务那边主要关注的是什么指标。而与这一个指标相关的参数有那些,这些参数都是如何来影响这些指标的。至于算法的准确度,这一点,可以通过对数据颗粒度的细化来不断提高。不同的代码对系统的资源调度是不同的,而若你对算法的了解程度最大限度决定了你最终产品的反应快慢! 但据《财经》记者调查,这些有政府和国资背景的大数据交易所大部分生意寥寥,纯市