《数据分析暑期实习》专题
-
 快手数据研发面经(暑期实习)
快手数据研发面经(暑期实习)4.22官网投递->4.23约面->4.25一面->5.5二面-> 面试官有事5.10三面改到5.15->三面过后接着hr面->5.22offer 快手一面(大约40min,sql写了20min) 1、自我介绍 2、hive和pyspark是学校有课程还是说自学的 3、本科或研究生期间有学过编程相关的课程吗 4、研究生学的些什么课程 5、你的项目都是自己去做的吗 6、你之前有实习过吗 7、四个SQ
-
 24数学找暑期实习
24数学找暑期实习今天笔试了一下阿里云智能java开发,感要寄 数学菜鸡没有学过计网,操作系统,数据库啥的,八股刚学了两天,啥也不会,赶鸭子上架去找实习 java完全不会,hr说可以面c/c++ 单选和多选除了两个判断出队,出栈序列,一个代码补全,一个排序稳定性判断会做,别的都不会做,基本都是计网,数据库,操作系统的 编程题感觉难度有点大,退役老选手多年没打代码,没做计数,最后只做出来一个 第一个是给一个2e6的序
-
 美团 大数据开发 暑期实习 一面
美团 大数据开发 暑期实习 一面时长:1h 由于问题太多,分四类进行整理 0. 实习相关:之前有数据开发的实习经验,就问了之前工作有没有spark或者hivesql优化的经验;如何确保数据的有效性;实习公司数据存储格式(Parquet),还知道哪些数据存储格式 1. 大数据相关问题:为什么Spark比MR快;对Spark的了解;两个表join的优化方法(大小表join可以map-side join, join前过滤null值);
-
 (暑期实习)携程大数据一面、二面
(暑期实习)携程大数据一面、二面个人情况简述:本硕双非,acm银牌 测评答的个人感觉不错,笔试AK 测评隔天笔试(第一批),之后就跟大部队流程差不多约了一、二面 一面(总时长50分钟),二面(总时长40分钟) 纯业务理解,深挖实习经历和项目经历 提出的问题多为数仓设计问题和开放性问题,基本都是大量的对话和交流,因为很多想法是结合项目经验的临场idea,个人没有记录 携程给我的感觉就是,如果你做过很多项目,阅读过大量相关设计的学习
-
 美团暑期实习-大数据开发一面
美团暑期实习-大数据开发一面#暑期# #投递实习岗位前的准备# 3月23日--分享个经验,求个好运 时长一个小时二十分钟 自我介绍 因为学统计的,问了中心极限定理和大数据定律 机器学习-XGBoost算法简介 两道智力题:逻辑判断谁说谎了和分金条 问了为什么研究生跨专业保研了? Hive和MySQL区别 数据库的索引有什么用 说一下索引的类型,还有B+树索引 数据仓库和关系型数据库区别 Hadoop生态圈简介 问我SQL写的
-
 tx暑期实习一面3.25pcg大数据开发
tx暑期实习一面3.25pcg大数据开发自我介绍后根据我的项目问我了一些问题,虚拟列表,懒加载,canvas怎么压缩的(这个没答对) 项目怎么实现鉴权的,我说的jwt,巴拉巴拉 然后又问了cookie, 问了防抖节流 项目跨域是怎么解决的(项目上线后用反向代理不太好) 问了数据类型,然后就问深拷贝浅拷贝,让我实现深拷贝 问promise,让我实现all和race方法 解释下事件循环机制 nextTick 总结:还是要多写写底层源码,回答
-
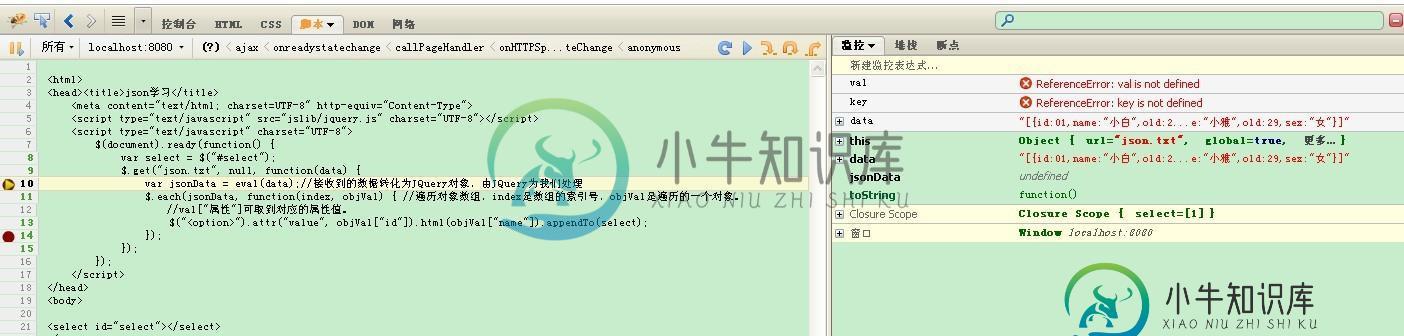 jQuery解析json数据实例分析
jQuery解析json数据实例分析本文向大家介绍jQuery解析json数据实例分析,包括了jQuery解析json数据实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了jQuery解析json数据的方法。分享给大家供大家参考,具体如下: 先来看看我们的Json数据格式: 为了消除乱码问题,我们设置一个过滤器(代码片段) 服务端我用Servlet生成json数据(代码片段)。 页面端JQuery代码: 之前为了省事,
-
 联想数分一二面面经(24暑期实习)
联想数分一二面面经(24暑期实习)背景:某顶流211,0实习,专业排名前20% 一面 1.对岗位的基本介绍 2.自我介绍 3.学过哪些数据库课程,用的是哪些工具 4.在学校项目中有哪些运用到数据分析技巧的项目 5.在项目中担任什么职位 6.对联想的pc业务有没有了解(很尴尬我真的一点都不了解) 7.找实习的初衷 8.以后求职的方向(我脑子一热说互联网公司,然后才反应过来联想不是互联网企业啊..) 9.对联想公司的印象 10.平时生
-
 oppo暑期实习
oppo暑期实习昨晚测评之后就一直在复筛选,OPPO不是半个学历厂吗,是不是我投的晚了,浙带连个面试机会都不给,我裂开
-
 暑期实习-oppo
暑期实习-oppo3.29 官网投递 机器学习算法工程师 4.10 初筛过+测评 4.17 复筛过,待面试 5.11 上午 一面 在公司,没找到会议室,迟到了10分钟,外面网还不好,中途掉线了, 耳机也出了问题,断连好几次了 总之就是迟到了,上来就是手撕,两个链表节点相加,考虑进位创建新节点就行 然后项目部分就是逐个项目解释,问一些优化手段吧 问了一些简单八股啥的,有点搞忘了,下午两个电话面和一个视频面,上午的记得
-
 一面数据-数据分析实习生面经
一面数据-数据分析实习生面经写在前面:这个岗位重视可视化的能力,在去年一战失败后也投过这个岗位的正职,面试前和面试中都在问有没有相应的可视化作品,对于实习生希望熟悉sql和tableau,一来就可以干活 1.自我介绍 2.对于以往实习经历和项目浅挖 3.次日留存sql代码考察 4.询问了不了解窗口函数 5.利用窗口函数计算不同品类前十GMV 6.tableau和power bi知识点考察 -技术问题一直准备的sql,DAX公
-
数据分析
有时候,对于我们的决定只要有一点点的数据支持就够了。一点点的变化,可能就决定了我们产品的好坏。我们可能会因此而作出一些些改变,这些改变可能会让我们打败巨头。 这一点和 Growth 的构建过程也很相像,在最开始的时候我只是想制定一个成长路线。而后,我发现这好像是一个不错的 idea,我就开始去构建这个 idea。于是它变成了 Growth,这时候我需要依靠什么去分析用户喜欢的功能呢?我没有那么多的
-
 数据分析日常实习面试分享
数据分析日常实习面试分享字节数据分析实习面试(抖音电商) 一面: 表user_log,有user_id, time,求每天用户新增数,次日留存率、30日留存率 ABTest的流程,P值,做留存率的ABTest,选择什么检验,卡方检验的应用场景 逻辑回归的损失函数 出现过拟合的原因 三天后给了感谢信 快手数据分析师(短视频用户增长部门) 一面: 两个SQL题目,都还比较简单,主要涉及到group by和日期函数的处理,还有
-
 (暑期实习)美团大数据开发实习生一面
(暑期实习)美团大数据开发实习生一面个人情况简述:本硕双非,acm银牌 随便找群友要了个内推投递 笔试4.2题,投递选择的是都喜欢,笔试完在人才池待了十几天,被数仓部门捞了 一面(总时长50分钟) 聊实习经历和简历项目,聊了约30分钟 聊天环节把整个技术栈聊的差不多了,还有离线、实时数仓的很多点,后面又问了几个问题 离线数仓分层设计、实时数仓设计,spark、flink相关生成经验,S3、OSS的使用理解,k8s的使用心得等都在聊项
-
 美团数据开发暑期实习面经(已offer)
美团数据开发暑期实习面经(已offer)时间线: 5.10一面 —— 5.14约二面 —— 5.17二面 —— 5.25直接发offer 无hr面,无oc 美团一面 1.项目 1)项目的总体架构和实现? 2)Flulme 和 Sqoop 如何保证数据不丢失? 3)数仓中的主题是什么,是根据什么来确定的? 4)数仓分层的优点和缺点 5)星座模型 6)数仓分层,每一层的作用? 7)事实表和维度表有什么关系? 8)事实表有哪些类型? 9)除了