《大数据测试》专题
-
如何在Spring的每个测试之前重新创建数据库?
问题内容: 我的Spring-Boot-Mvc-Web应用程序在文件中具有以下数据库配置: 这是我所做的唯一配置。我在任何地方都没有进行任何其他配置。尽管如此,Spring和子系统会在每次Web应用程序运行时自动重新创建数据库。即在系统运行时重新创建数据库,而在应用程序结束后它包含数据。 我不了解此默认值,并期望它适合测试。 但是,当我开始运行测试时,我发现数据库仅重建一次。由于没有按预定义的顺序
-
在Spring的每次测试之前,如何重新创建数据库?
问题内容: 我的Spring-Boot-Mvc-Web应用程序在文件中具有以下数据库配置: 这是我所做的唯一配置。我在任何地方都没有进行任何其他配置。尽管如此,Spring和子系统会在每次Web应用程序运行时自动重新创建数据库。即在系统运行时重新创建数据库,而在应用程序结束后它包含数据。 我不了解此默认值,并期望它适合测试。 但是,当我开始运行测试时,我发现数据库仅重建一次。由于没有按预定义的顺序
-
在训练和测试数据中保持相同的虚拟变量
我正在用python构建一个预测模型,其中包含两个独立的训练集和测试集。培训数据包含数字类型分类变量,例如邮政编码[915212315112355,…],以及字符串分类变量,例如,城市[‘芝加哥’、‘纽约’、‘洛杉矶’、…]。 为了训练数据,我首先使用“pd”。获取_dummies'以获取这些变量的虚拟变量,然后用转换后的训练数据拟合模型。 我对测试数据进行同样的转换,并使用经过训练的模型预测结果
-
HTTP状态500-javax.servlet.服务器异常:com.mysql.jdbc.exceptions.jdbc4。未知数据库/测试
我在运行jsp文件时遇到这种错误。我已经使用MySQL连接器进行了连接。 HTTP状态500-javax。servlet。ServletException: com.mysql.jdbc.exceptions.jdbc4。未知数据库/test类型异常报告 消息javax。servlet。ServletException:com。mysql。jdbc。例外情况。jdbc4。MySQLSyntaxEr
-
如何从MongoDB中检索数据并在Rest-Assured测试中使用
以下数据正在mongodb中存储:- 现在,如果我想从mongo获取此数据,从建立与db的连接开始,到获取数据 我使用放心使用Spring启动自动化API测试,所以有相当多的mongo相关库可以利用。 那么如何开始呢?
-
如何对写入BigTable的数据流管道进行集成测试?
据Beam网站报道, 通常,对管道代码执行本地单元测试比调试管道的远程执行更快更简单。 出于这个原因,我想对写到Bigtable的Beam/DataFlow应用程序使用测试驱动开发。 但是,在Beam测试文档之后,我遇到了一个僵局--Passert并不有用,因为输出PCollection包含org.apache.hadoop.hbase.client.Put对象,这些对象不重写equals方法。
-
使用Spock和服务类在Grails中进行数据驱动测试
问题是,如果我使sqlService,Grails依赖项注入不起作用,它只创建一个空对象。如果我尝试将其设置为静态(如),情况也是如此。 我尝试将一个新的SqlService实例小型化,就像我的setupSpec块中所示: 这只是给出了一个错误 有人知道我如何在Spock测试中使用另一个服务类作为数据提供者吗?
-
Quarkus测试中如何清除可嵌入类型的数据库表
我需要清除Quarkus应用程序中数据库的表。我可以通过调用为扩展或的实体实现这一点。如何清除可嵌入类型的表?
-
似乎我的Junit测试在运行时运行,缺少数据源
我在单元测试中使用了H2数据库,使用java配置:
-
找不到用于测试数据流的Dofn的DofnTester类的方法
SDK: Google Cloud Dataflow SDK forJava2.1.0 Class: DoFnTester method: setOutputTags https://beam.apache.org/documentation/sdks/javadoc/2.1.0/org/apache/beam/sdk/transforms/DoFnTester.html Google Cloud
-
groovy grails构建测试数据(buildtestdata插件)如何创建多对多
使用Grails 2.2.4。和build-test-data:2.0.5。我在使用conf-bootstrap.groovy在DB中添加多对多实例时失败了。使用MySQL作为数据库。 以下是简化的域类: } 而且 这导致运行时在MySQL中创建... (下面是一个简单的ER图,因为我无法从MySQL工作台图中发布图像) reseller==>1到many==>reseller_address<=
-
使用spring boot liquibase对多个数据源不起作用的测试
我正在为具有多个数据源的spring boot应用程序创建unittesting。(配置很大程度上受到了这个答案的启发) 而且 应用程序运行正常。 不确定缺少了什么配置更改。
-
Python编写检测数据库SA用户的方法
本文向大家介绍Python编写检测数据库SA用户的方法,包括了Python编写检测数据库SA用户的方法的使用技巧和注意事项,需要的朋友参考一下 本文讲述一个用Python写的小程序,用于有注入点的链接,以检测当前数据库用户是否为sa,详细代码如下:
-
AUC较高,但数据不平衡时预测较差
问题内容: 我正在尝试在非常不平衡的数据集上使用LightGBM建立分类器。不平衡率,即: 我使用的参数和训练代码如下所示。 我运行简历来获得最好的模型和最好的回合。我的简历获得了0.994 AUC,并且在验证集中获得了类似的分数。 但是,当我在测试集上进行预测时,我得到的结果非常糟糕。我相信火车是完美采样的。 需要调整哪些参数?问题的原因是什么?我是否应该对数据集重新采样以减少最高等级? 问题答
-
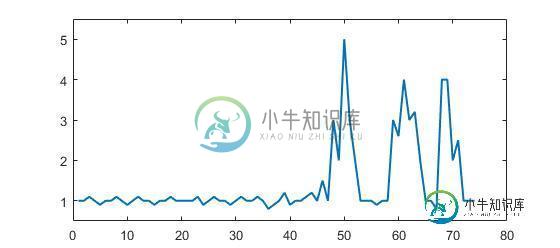 实时时序数据中的峰值信号检测
实时时序数据中的峰值信号检测更新:到目前为止,性能最好的算法就是这个。 这个问题探索了检测实时时间序列数据中突然峰值的鲁棒算法。 考虑下面的示例数据: 此数据的示例为Matlab格式(但此问题与语言无关,而与算法有关): 你可以清楚地看到有三个大峰和一些小峰。此数据集是问题所涉及的timeseries数据集类的一个特定示例。此类数据集具有两个一般特征: 存在具有一般平均值的基本噪声 存在明显偏离噪声的大“峰值”或“更高数据点