《大数据测试》专题
-
将数据从非常大的文本文件导入JTable
我正在制作一个应用程序,它处理存储在文本文件中的大量数据。本质上,应用程序浏览一个. txt文件,一旦找到,应用程序需要把文件中的所有数据放入JTable,然后我需要对数据执行一些过滤操作,然后将其导出。. txt文件中的数据格式如下: 有数千行。每行由双类型数字组成(A、B……均为1.3、2.0等) 我通过手动添加数组中的所有列名,然后将表的模型设置为 我已经把行作为'空'在这里,因为我不知道我
-
Java Spark-Java.lang.outofMemoryError:超过GC开销限制-大型数据集
我们不确定从这里到哪里去,完全被困住了。有人能帮忙吗?我们到处找了一些例子来帮忙。
-
过滤大型数据帧的更快方法是什么?
我想对大约40万行的数据帧进行排序,其中包含4列,用if语句取出大约一半: 到目前为止,我一直在测试以下4个中的任何一个: 或与.loc相同 或者将if(非in)改变为if(in)并使用: 或者尝试将emptyline设置为具有值,然后将其附加: 因此,从我到目前为止设法测试的内容来看,它们似乎在少量行(2000)上都可以正常工作,但是一旦我开始获得更多的行,它们所需的时间就会呈指数级增长。.at
-
如何使用Realm解析大型JSON并存储数据
我真的被阻止使用Realm解析和存储数据,我有一个大的JSON,我创建了所有的类模型,就像RealM的例子一样。 这是我的错误:由:org引起。json。JSONException:io的0处的值fr。领域例外。RealmException:无法在io上映射Json。领域领域com上的createObjectFromJson(Realm.java:860)。实例截击2。ImagesActivity
-
在oracle SP中用更大的数据类型替换varchar2
我使用的是oracle verion 10。PL/SQL中存在使用varchar2变量的存储过程。代码不断追加varchar2变量。当varchar2变量大小超过32767时,它不能追加任何值。现在我想将数据类型更改为long或clob(为了容纳更多的字符),但它不起作用。如何修改这里的代码,使其具有与clob或LONG相同的附加功能? 示例附加x:=x'mydata';
-
将大量数据写入 TD 引擎时出现问题
我正在尝试将我的应用程序移植到TDEngine,该应用程序通过其无模式接口将ImpxDb数据写入TDEngine。我认为这应该很容易,但实际上并不容易。 爪哇代码如下: 我在控制台上得到了结果: 传感器,设备 Id=传感器0 电流=10.2,json$j=“{”f6“:”tt“,”f7“:”aa“,”f0“:”tt“,”f1“:”aa“,”f2“:”tt“,”f3“:”aa“,”f4“:”tt“,
-
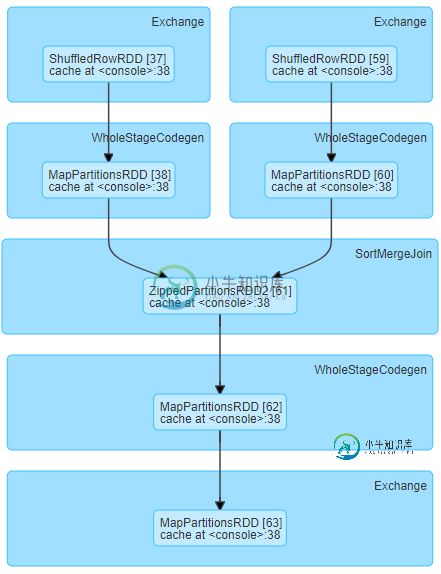 火花洗牌读取小数据需要大量时间
火花洗牌读取小数据需要大量时间我们正在运行以下阶段DAG,对于相对较小的洗牌数据大小(每个任务约19MB),我们经历了较长的洗牌读取时间 一个有趣的方面是,每个执行器/服务器中的等待任务具有等效的洗牌读取时间。这里有一个例子说明了它的含义:对于下面的服务器,一组任务等待大约7.7分钟,另一组等待大约26秒。 这是同一阶段运行的另一个例子。该图显示了3个执行器/服务器,每个执行器/服务器具有相同的洗牌读取时间的统一任务组。蓝色组
-
优化数据流池大小以提高点火性能
我正在使用ignite2.6,其中有数据流节点,从kafka消耗数据并放入Ignite缓存。服务器平均负载较高,吞吐量降低。 我已经尝试为缓存中定义的索引内联设置索引大小,这样可以提供良好的性能,但也增加了服务器内存利用率和较高的平均负载。请说明在这种情况下增加datastreamer线程池大小会产生什么影响。
-
如何确定Apache Spark数据帧中的分区大小
我一直在使用SE上发布的问题的一个极好的答案来确定分区的数量,以及跨数据帧的分区分布需要知道数据帧Spark中的分区详细信息 有人能帮我扩展答案来确定数据帧的分区大小吗? 谢谢
-
 思必驰大数据日常实习岗位面经(OC)
思必驰大数据日常实习岗位面经(OC)找了半个月的实习,面试了20多家,在同程HR面之后还被挂的惨痛经历之后,终于找到了一家不错的公司。(现在大环境下大数据实习太难找了,基本都是外包要人,BAT我都是一面挂,有些是简历挂) 下面讲讲我记得的一些问题 一面(40分钟) 自我介绍 熟悉二叉树吗,细说有多少种二叉树,哪些二叉树是用来排序的,并且将各个树的特点讲讲 了解MySQL存储引擎嘛,说说自己看法 计算机网络,TCP,UDP区别。Htt
-
 字节大数据开发-人力科技面经(已凉)
字节大数据开发-人力科技面经(已凉)字节大数据开发工程师- 人力科技面经 一面 网络模型,每一层的功能 访问一个网页的流程 tcp是如何保证可靠 线程和进程的区别 JVM的内存区域 垃圾回收算法 类加载的过程 Spark和MR的区别 Spark任务调度过程 spark中stag,job,task是如何划分的 spark宽窄依赖 为什么spark比MR快 Hadoop的框架 Hadoop提交作业的流程 Hadoop中是如何找到文件对应
-
 网易云音乐 大数据开发工程师 1面
网易云音乐 大数据开发工程师 1面30min 1. 自我介绍 2. 为什么走大数据 3. 项目介绍 4. hive和spark的区别 5. MR和spark有哪些区别,分别适用什么场景 6. 为什么不选择spark做离线 7. 开窗函数有哪些 8. 数仓怎么设计的 9. ODS层存在的意义 10. DWD和DIM怎么设计的,有什么指标 11. DWS层存放的哪些指标 12. 下一步准备学习什么?怎么学习? 反问 1. 部门做什么业
-
 深圳闻泰科技 大数据开发 技术面经
深圳闻泰科技 大数据开发 技术面经1、自我介绍 2、什么是维度建模?什么是关系建模? 3、星型模型和雪花模型有什么区别? 4、数据仓库分层的意义是什么? 5、对哪些大数据框架比较熟悉?(答了Hadoop和Kafka) 6、Hadoop的进程有哪些?作用分别是什么? 7、Kafka的特点是什么? 8、Kafka为什么可以支持海量数据吞吐? 9、问实习工作内容,以及实习收获 10、能否接受加班? 11、有什么问题要问我的?问了日常工作
-
 携程 大数据底层框架开发 面经回顾
携程 大数据底层框架开发 面经回顾去年秋招拿了携程-大数据底层框架开发岗位的offer,想着还是把面试回顾下吧,给后面的朋友一个参考。 这个岗位是做大数据组件底层二次开发的,我面试的是偏向离线方面,因此面试都是围绕hadoop、spark、hbase、hive这几个组件的底层原理去问,因为是偏向底层,所以也会注重java语言和多线程并发的知识。 HDFS的写入流程?如果一台机器宕机,HDFS怎么保证数据的一致性?如果只存活一台机器
-
 爱奇艺风控大数据Java日常实习(已OC)
爱奇艺风控大数据Java日常实习(已OC)选一个你觉得做的最好的项目,说一说 深挖项目,多问为什么这样设计,为什么这样做 选一个Java的项目,说一下 三级缓存是怎么实现的 那么一级缓存(nginx访问redis)和三级缓存redis的区别是什么,去掉了三级缓存可以么 介绍一下令牌桶算法数据结构,和漏斗桶的区别,为什么选令牌桶不用漏斗桶 如何保证mq消费者端更新数据库可以成功 如何保证消息可以不重复消费,使用redis做幂等是完全安全的么