《百词斩》专题
-
10.5 管理分单词库
●词库管理:对于同音字(锦绣大地、锦锈大地)、形近字(杏石口村、杏右口村)、缩写地址(牛栏山第一中学、牛栏山一中)、别名 等经常误写的地址,在系统中将经常出现错误的地址与正确的区域对应起来(也称为关键词绑定),下次再出现,能够直接分 到匹配站点,提高分单准确率。 例如:地址“牛栏山一中”在自动分拣的时候解析错误,我们在地图上找到“牛栏山第一中学”并确认“牛栏山一中”就是“牛栏山 第一中学”,因此,
-
lrc歌词同步显示
实现一个简单的基于LRC的歌词同步显示功能,支持[time][time]XXXX格式的LRC文件。 [Code4App.com]
-
你来说一下百度百科 和 知乎 的区别
本文向大家介绍你来说一下百度百科 和 知乎 的区别相关面试题,主要包含被问及你来说一下百度百科 和 知乎 的区别时的应答技巧和注意事项,需要的朋友参考一下 1 产品定位维度 百度百科是提供资讯的工具型产品。百度百科是百度为丰富其知识搜索体系所搭建的产品线之一,本质上是为百度搜索体系服务的,所以百度百科不能算是一个纯粹的流量知识平台。而知乎是一个由用户生产内容的社区产品。 2 信息源维度 百度百
-
Hadoop单词计数:接收以字母“ c”开头的单词总数
问题内容: 这是Hadoop字数统计Java映射并减少源代码: 在map函数中,我已经到了可以输出所有以字母“ c”开头的单词以及该单词出现的总次数的位置,但是我想做的就是输出总数以字母“ c”开头的单词,但我在获取总数上有些停留。任何帮助将不胜感激,谢谢。 例 我得到的输出: 可以2 罐3 猫5 我想要得到的是: 合计10 问题答案: 克里斯·格肯 的答案是正确的。 如果您要输出单词作为关键字,
-
将酷狗krc歌词解析并转换为lrc歌词php源码
本文向大家介绍将酷狗krc歌词解析并转换为lrc歌词php源码,包括了将酷狗krc歌词解析并转换为lrc歌词php源码的使用技巧和注意事项,需要的朋友参考一下 最近在进行一次对酷狗音乐歌词采集时发现酷狗音乐的歌词直接浏览都是“乱码”,自己平时所见的歌词都是lrc格式的文本,这种酷狗专用的krc格式的显然是经过特别处理过的,平时用酷狗听音乐也没仔细看他的歌词有什么不同,只是与天天静听等不同的是可以逐
-
使用php preg_match(正则表达式)将camelCase单词拆分为单词
问题内容: 我将如何拆分单词: 放入数组,这样我就可以得到: 与? 我很累,但这只是整个词 问题答案: 您还可以用作: 说明:
-
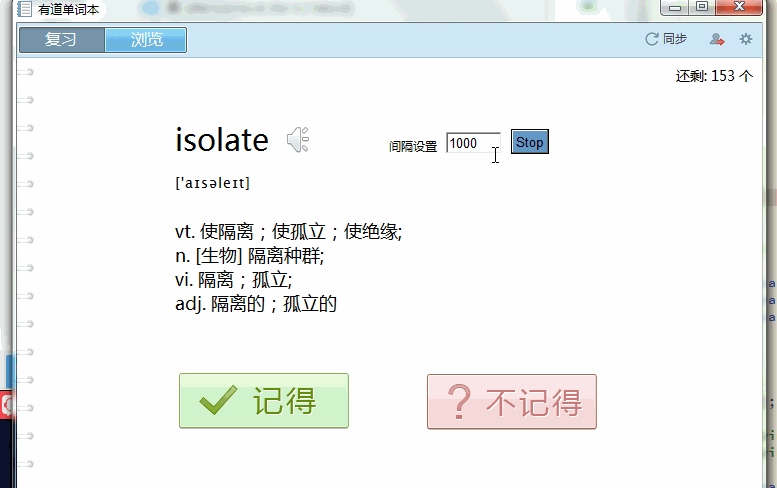 JS实现自动阅读单词(有道单词本添加功能)
JS实现自动阅读单词(有道单词本添加功能)本文向大家介绍JS实现自动阅读单词(有道单词本添加功能),包括了JS实现自动阅读单词(有道单词本添加功能)的使用技巧和注意事项,需要的朋友参考一下 个人比较习惯使用有道,使用了一段时间,背单词的时候很不方便 而有道单词客户Duan没有自动阅读的功能, 本文用强大的js实现了简单的自动下一个单词的功能, 方法: 第一步打开有道路径下的"\Dict\6.3.69.8341\resultui\js\wo
-
Python-在文本文件中查找单词列表的单词频率
问题内容: 我试图加快我的项目以计算单词频率的速度。我有360多个文本文件,我需要获取单词的总数以及另一个单词列表中每个单词出现的次数。我知道如何使用单个文本文件执行此操作。 要获得“通货膨胀”,“工作”,“产出”个体的频率过于繁琐。我可以将这些单词放入列表中并同时查找列表中所有单词的出现频率吗?基本上,这与Python。 示例:代替此: 我想这样做(我知道这不是真实的代码,这是我在寻求帮助的内容
-
如何注释除列表中的动词以外的每个动词
我试过这个: 但没有用。我如何找到一个动词,检查它是否已经有一个Inner_Pred注释,如果没有,将这个动词注释为outer_pred?在inner_pred.lst中,我有基本形式的动词列表。 提前谢了。如果你能告诉我在哪里我可以自己看这些信息,那就太好了。我只找到了GATE Jape手册,但它很短,没有提供很多答案。
-
如何将一个动词转换成它的(派生)名词形式?
我正在从事一个与NLP相关的项目,在这个项目中,我想从一个句子中识别主要动词(我可以使用依赖项解析器),然后将动词转换为其名词形式(或者我们可以说从动词派生的名词),例如或,只要可能。有没有类似于wordnet或verbnet的资源提供这种功能?
-
 前端 - 词云图中如何自定义词语的字体大小?
前端 - 词云图中如何自定义词语的字体大小?如何自定义词云中的文字大小,我希望权重较大的文字能显示的更大些,比如下面这个例子中我想让最大的文字大小达到40px,我该怎么做呢?
-
如果单元格有2个单词,则只提取第一个单词,如果单元格有3个单词,则提取2个第一个单词-PANDAS/REGEX
在我的数据框架中,有一列名为“teams”。它包括城市和球队名称。我想把这个城市拉进另一个纵队。这是数据帧:数据帧示例 我可以使用正则表达式轻松提取列: 然而,在“名称”栏中,对于纽约尼克斯队,它只给了我“New”的值,我想得到“New York”: 结果 那么,我该怎么做呢?如果单元格有2个单词,我该如何从开头只提取一个单词?如果单元格有3个单词,我该如何使用正则表达式从中提取2个单词?
-
Elasticsearch分析百分比
问题内容: 我正在使用Elasticsearch 1.7.3累积用于分析报告的数据。 我有一个包含文档的索引,其中每个文档都有一个名为“ duration”的数字字段(请求花费了几毫秒)和一个名为“ component”的字符串字段。可能有许多具有相同组件名称的文档。 例如。 我想生成一份报告,说明每个组件: 此组件的所有“持续时间”字段的总和。 此总和在 所有 文档的总期限中所占的百分比。在我的
-
MySQL计算百分比
问题内容: 我有4个项目MySQL数据库:(数值),和。 在我的报告中,我需要通过“调查”中的数字来计算已参加调查的“雇员”的百分比。 这是我现在的声明: 表格如下: 我想按参加调查的人数来计算谁所占的百分比。即,如以上数据所示,分别为0%和95%。 问题答案: 尝试这个 在这里演示
-
MySQL计算百分比
我有一个包含4个项的MySQL数据库:(数值)、、和。 在我的中,我需要根据“surveys”中的数字来计算接受调查的“employees”的百分比。 这就是我现在的说法: 下面是表格的原样: 我想根据中的数字计算参加调查的的百分比。即,如上面的数据所示,将为0%,将为95%。