《百词斩》专题
-
JPA标准谓词条件
问题内容: 我有以下用于构建条件构建器的标准代码段。 我想知道有什么方法可以使它更好,因为我将更多地使用条件和相同条件来获取记录数。 任何见解都是高度赞赏的 问题答案: 首先,您必须考虑以分层方式重组应用程序。您至少需要3层,DAO,Service和WebService。 有关数据库和JPA的所有内容都必须在您的DAO层中。并且所有与json相关的事物都必须在您的WebService层中。您的服务
-
Java 8 Lambda谓词链接?
问题内容: 我无法编译它,甚至可以链接谓词lambda吗? 或唯一的方法是显式创建一个谓词,然后像这样组合: 还是有更多的“功能优雅”的方式来实现同一目标? 问题答案: 您 可以 使用: 但这不是很优雅。如果要直接指定条件,则只需使用一个λ:
-
通过谓词限制流
问题内容: 是否存在Java 8流操作来限制(可能是无限的)Stream直到第一个元素与谓词不匹配? 在Java 9中,我们可以takeWhile像下面的示例那样使用它来打印所有小于10的数字。 由于Java 8中没有这样的操作,以一般方式实现它的最佳方法是什么? 问题答案: 这样的操作在Java 8中应该是可能的,但不一定能有效地完成-例如,您不必并行化这样的操作,因为您必须按顺序查看元素。 该
-
在Swift中使用谓词
问题内容: 我正在为我的第一个应用程序浏览本教程(学习Swift):http : //www.appcoda.com/search-bar-tutorial- ios7/ 我被困在这部分(Objective-C代码): 谁能建议如何在Swift中为NSPredicate创建等效项? 问题答案: 这实际上只是语法切换。好,所以我们有这个方法调用: 在Swift中,构造函数跳过“ blahWith…”
-
ANTLR 隐式词法规则
本文向大家介绍ANTLR 隐式词法规则,包括了ANTLR 隐式词法规则的使用技巧和注意事项,需要的朋友参考一下 示例 当'{'在解析器规则中使用like标记时,将为它们创建隐式词法分析器规则,除非存在显式规则。 换句话说,如果您有词法分析器规则: 然后,这两个解析器规则都是等效的: 但是,如果OPEN_BRACE是词法规则没有定义,一个隐含的匿名规则将被创建。在这种情况下,隐含的规则将被定义为,如
-
Elasticsearch词组前缀结果
问题内容: 我有两个ES查询: 问题是第二个查询返回的文档少于第一个查询,尽管我希望第二个查询返回第一个查询的所有记录以及其他内容。我想念什么? 谢谢 问题答案: 这可能是由于将其设置为默认值10 试试这个 该线程将帮助您了解术语的扩展方式。使1000并查看结果。 基本上,您有很多以bo开头的单词,例如 bond,boss, 而且由于 “ x” 按字母顺序排在最后,因此您无法获得期望的结果。 我希
-
println词典具有“可选”
问题内容: 考虑以下代码段: 控制台输出: 可选([1、4、9、16、25] [75、43、103、87、12] 为什么字典中有“ Optional”? 问题答案: 为了安全起见,Swift字典正在返回可选内容。如果您尝试访问一个不存在的密钥,那将使您无用。 您还可以使用下标语法从字典中检索特定键的值。因为可以请求不存在任何值的键,所以字典的下标返回字典值类型的可选值。如果字典包含所请求键的值,则
-
Java 用谓词限制流
问题内容: 是否存在Java 8流操作来限制(可能是无限的)直到第一个元素与谓词不匹配? 在Java 9中,我们可以使用下面的示例来打印所有小于10的数字。 由于Java 8中没有这样的操作,以一般方式实现它的最佳方法是什么? 问题答案: 操作并已添加到JDK9。你的示例代码 在JDK 9下编译和运行时,其行为将完全符合你的预期。 JDK 9已发布。可在此处下载:http : //jdk.java
-
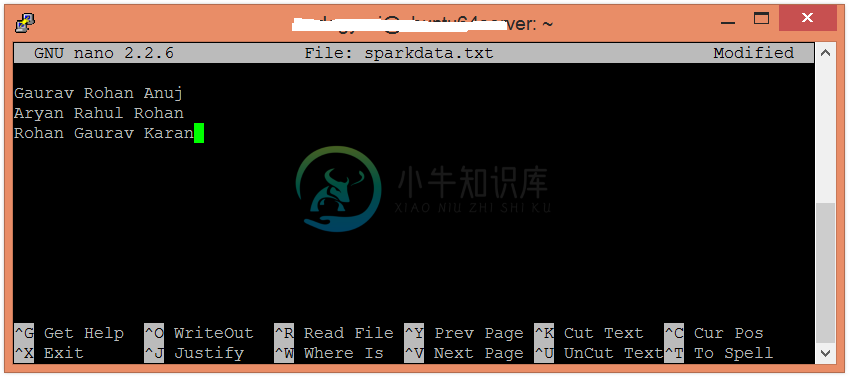 Spark单词统计示例
Spark单词统计示例主要内容:执行Spark字数计算示例的步骤在Spark字数统计示例中,将找出指定文件中存在的每个单词的出现频率。在这里,我们使用Scala语言来执行Spark操作。 执行Spark字数计算示例的步骤 在此示例中,查找并显示每个单词的出现次数。在本地计算机中创建一个文本文件并在其中写入一些文本。 检查文件中写入的文本。 在HDFS中创建一个目录,保存文本文件。 将HDD上的sparkdata.txt 文件上传到特定目录中。 现在,按照以下命
-
linux命令的词源学
问题内容: 按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实,参考或专业知识的支持,但是这个问题可能会引起辩论,争论,民意调查或扩展讨论。如果您认为此问题可以解决并且可以重新提出,请访问帮助中心以获取指导。 7年前关闭。 只是为了好玩…我倾向于通过全天寻找偶然的难题来保持警觉。我喜欢linux的一件事是,它体现出了无止尽的聪明,从优雅到一开始一直到手册页中的注释。 您能否阐明指示
-
elasticsearch禁用词频计分
问题内容: 我想在elasticsearch中更改评分系统,以摆脱对一个术语的多次出现计数的麻烦。例如,我想要: “德克萨斯州德克萨斯州” 和 “得克萨斯州” 得分相同。我发现elasticsearch表示该映射将禁用词频统计,但是我的搜索结果却不一样: } 任何帮助将不胜感激,我无法找到很多有关此的信息。 编辑: 我正在添加搜索代码,并在使用解释时返回了什么。 我的搜索代码: 当我搜索解释时,我
-
随机词生成器-Python
问题内容: 所以我基本上是在一个项目中,计算机从单词列表中提取一个单词,然后为用户弄乱它。只有一个问题:我不想一直在列表中写很多单词,所以我想知道是否有一种方法可以导入很多随机单词,所以即使我也不知道它是什么,并且那我也可以玩游戏吗?这是整个程序的编码,我只输入了6个字: 问题答案: 如果您重复执行此操作,我将在本地下载它并从本地文件中提取。* nix用户可以使用。 例: 从远程字典中提取 如果您
-
数学逻辑连接词
本文向大家介绍数学逻辑连接词,包括了数学逻辑连接词的使用技巧和注意事项,需要的朋友参考一下 逻辑连接词是一种符号,用于连接两个或多个命题或谓词逻辑,使得结果逻辑仅取决于输入逻辑和所用连接词的含义。 通常有五个连接词是- 或(∨) AND(∧) 否定/非(¬) 暗示/如果-则(→) 当且仅当(⇔)。 OR(∨) -如果命题变量A或B中至少任何一个为真,则两个命题A和B(写为A any B)的OR运算
-
Spring SimpleJdbcCall和Oracle同义词
从升级Spring框架之后 无法确定正确的调用签名-“我的存储过程名称”没有过程/函数/签名 例外情况。然后我进行了调试,发现如果存储过程位于同义词后面,则无法找到它。对于旧的Spring版本,这不是问题。那么他们改变了什么?我现在能做什么?我阅读了有关从数据源检索原始Oracle连接并激活同义词标志的内容:https://docs.oracle.com/cd/E11882_01/appdev.1
-
NLTK中的实词计数
NLTK书中有几个单词计数的例子,但实际上它们不是单词计数,而是标记计数。例如,第1章“计算词汇”中说,下面给出了一个单词计数: 然而,它没有-它给出了一个单词和标点符号计数。你怎样才能得到一个真正的字数(忽略标点符号)? 同样,如何获得一个单词中的平均字符数?显而易见的答案是: 但是,这将关闭,因为: len(文本的字符串)是一个字符计数,包括空格 我是不是遗漏了什么?这一定是一个非常常见的NL