《大数据研发实习》专题
-
8.8 实例研究:Array 类
在 C 和 C++ 中,数组是一种指针,因而数组存在许多导致错误的陷阱。例如,由于 C 和 C++ 不检测下标是否超出数组的边界而使程序导致越界错误;大小为n的数组的下标必须是 0、1、2…、 n-1,下标是不允许改变的;不能一次入输人或输出整个数组,而只能单独读取或者输出每个数组元素;不能用相等运算符或者关系运算符比较两个数组(因为数组名仅仅是指向内存中数组起始位置的指针)。 当把一个数组传递给
-
插入sql数据库时处理大量数据
问题内容: 在我的代码中,用户可以上传一个excel文档,希望其中包含电话联系人列表。作为开发人员,我应阅读excel文件,将其转换为dataTable并将其插入数据库。问题是某些客户拥有大量的联系人,例如说5000个和更多的联系人,而当我尝试将这种数据量插入数据库时,它崩溃了,并给了我一个超时异常。避免这种异常的最佳方法是什么?它们的任何代码都可以减少insert语句的时间,从而使用户不必等
-
将大量数据加载到Oracle SQL数据库
问题内容: 我想知道是否有人对我即将从事的工作有任何经验。我有几个csv文件,它们的大小都在一个GB左右,我需要将它们加载到oracle数据库中。虽然加载后我的大部分工作都是只读的,但我仍需要不时加载更新。基本上,我只需要一个很好的工具即可一次将多行数据加载到数据库中。 到目前为止,这是我发现的内容: 我可以使用SQL Loader来完成很多工作 我可以使用批量插入命令 某种批量插入。 以某种方式
-
 滴滴 后端研发-自动驾驶工具链研发 一二面凉经
滴滴 后端研发-自动驾驶工具链研发 一二面凉经一下午两面结束,收到不通过邮件。 一面 自我介绍 项目介绍 项目问的很细 两题算法: 翻转二叉树 二叉树的最大路径和 二面 自我介绍 对我用rust很感兴趣 rust疯狂问,没准备,卒 最后出了一道 括号匹配 无反问 十分钟后通知很遗憾,未通过二面。 #滴滴#
-
8. 大数据与机器学习 - Tensorflow
Kubeflow 是 Google 发布的用于在 Kubernetes 集群中部署和管理 tensorflow 任务的框架。主要功能包括 用于管理 Jupyter 的 JupyterHub 服务 用于管理训练任务的 Tensorflow Training Controller 用于模型服务的 TF Serving 容器 部署 部署之前需要确保 一套部署好的 Kubernetes 集群或者 Mini
-
8. 大数据与机器学习 - Spark
Kubernetes 从 v1.8 开始支持原生的Apache Spark应用(需要Spark支持Kubernetes,比如v2.2.0-kubernetes-0.4.0),可以通过 spark-submit 命令直接提交Kubernetes任务。比如计算圆周率 bin/spark-submit --deploy-mode cluster --class org.apache.spark.
-
Nginx 根据URL带的参数转发的实现
本文向大家介绍Nginx 根据URL带的参数转发的实现,包括了Nginx 根据URL带的参数转发的实现的使用技巧和注意事项,需要的朋友参考一下 使用场景: 需要根据截取URL动态配置跳转路径,常见于访问内网不固定ip地址的文件图片, 请求地址:http://11.19.1.212:82/bimg4/32.52.62.42:222/DownLoadFile?filename=LOC:12/data/
-
web开发中添加数据源实现思路
本文向大家介绍web开发中添加数据源实现思路,包括了web开发中添加数据源实现思路的使用技巧和注意事项,需要的朋友参考一下 在web开发中,可以利用hibernate配置数据源,但在实际的应用中,可能要连接多个数据源, 1.配置dataSource 2.配置sessionFactory 3.添加jdbc支持 感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
-
了解TCP数据包大小限制和UDP数据包大小限制
我正在使用在我的客户端应用程序中执行以及 最大数据包大小限制也存在于中,即?但是我可以使用中的发送大于最大数据包大小的数据块 这是怎么运作的?这是因为是基于流的,负责在较低层创建数据包吗?有什么方法可以增加UDP中的最大数据包大小吗? 当我在客户端读取时,我从服务器端发送的UDP数据包的一些字节是否可能丢失?如果是,那么有没有办法只检测UDP客户端的损失?
-
Axios未发布数据
我正在尝试使用axios发送数据,但它发送的响应超出预期。当我使用postman发出相同请求时,它会成功地向我的手机发送通知,以下是postman的响应: 但是使用axios,通知不会发送到我的手机,以下是axios的响应: 这是我的axios代码:
-
 蚂蚁,数据开发
蚂蚁,数据开发10.11 蚂蚁一面(共 20min) 电话面,随便聊了聊,说我要做笔试才有进一步进展,但我没时间做这个笔试 自我介绍 对部门业务的了解 对数据仓库的了解 询问项目具体内容 说我聊的还行,催笔试,笔试后才有相应反馈,笔试安排在10.11晚,有事没空做,再看吧 反问 部门重点在数据仓库构建还是在数据处理 #蚂蚁金服##秋招##数据#
-
WinPcap: 发送数据包
尽管从 WinPcap 的名字上看,这个库的目标应该是数据捕捉(Packet Capture),然而,它也提供了针对很多其它有用的特性。在其中,我们可以找到一组很完整的用于发送数据包的函数。 请注意:原始的libpcap库是不支持发送数据包的,因此,这里展示的函数都属于是WinPcap的扩展,并且它们不能运行于Unix平台下。 使用 pcap_sendpacket() 发送单个数据包 下面的代码展
-
 快手数据开发
快手数据开发一面 8.14 自我介绍 实习内容,没有深挖 Hive 的存储格式 orc parquet 有没有了解过Cube, grouping sets 有没有了解过 group by ,sort by,cluster by ,distribute by 的区别 Mr的工作流程 Yarn的调度框架 Hive内部表外部表区别 Lag lead first_value last_value含义 Row_numb
-
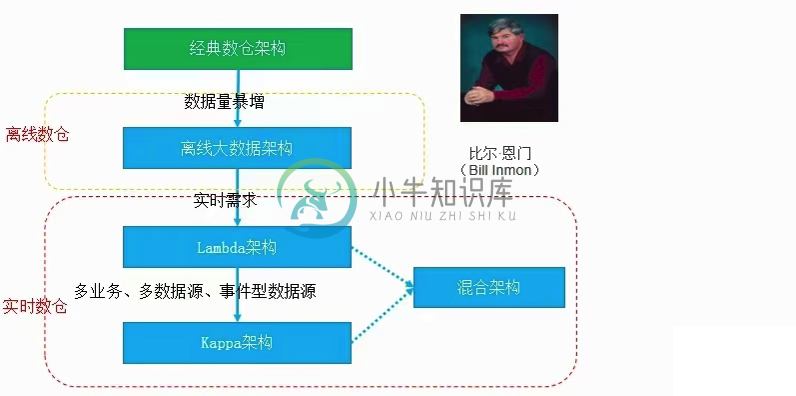 数据仓库发展
数据仓库发展主要内容:1.离线数仓,2.Lambda架构,3.Kappa架构,4.Smack架构,5.湖仓一体传统数仓 离线数仓 实时数仓 Lambda架构 Kappa架构 Smack架构 数据湖架构 仓湖一体架构 1.离线数仓 2.Lambda架构 Lambda架构是大数据平台里最成熟、最稳定的架构,它的核心思想是:将批处理作业和实时流处理作业分离,各自独立运行,资源互相隔离。 (1)Batch Laye:主要负责所有的批处理操作,支撑该层的技术以Hive、Spark-SQL或MapReduce这类批处
-
 美团 数据开发
美团 数据开发一面 实习深挖 聊数据治理(链路、模型、作业) spark作业调优具体案例 数据质量评价体系,如何保证数据质量 全链路数据建模怎么做 指标设计方法 数据结构有哪些,分别有什么作用 计网各层都有什么协议,分别有什么作用 mr和spark区别 shuffle原理 MySQL索引有哪些 MySQL索引数据结构 数据倾斜解决办法 算法 前k个大数 SQL 1.薪资TOP3 2.各个部门入职最早的员工 #美