《大数据研发实习》专题
-
实时数据的Cassandra数据建模
我目前有一个应用程序,它将事件驱动的实时流数据持久化到一个列系列,该系列建模为: 每个帐户ID每X秒发送一次数据,因此我们每次收到事件时都会覆盖现有行。此数据包含当前实时信息,我们只关心最近的事件(不使用旧数据,这就是我们插入已经存在的键的原因)。从应用程序用户端-我们通过account_id语句查询选择。 我想知道是否有更好的方法来模拟这种行为,并查看了Cassandra的最佳实践和类似的问题(
-
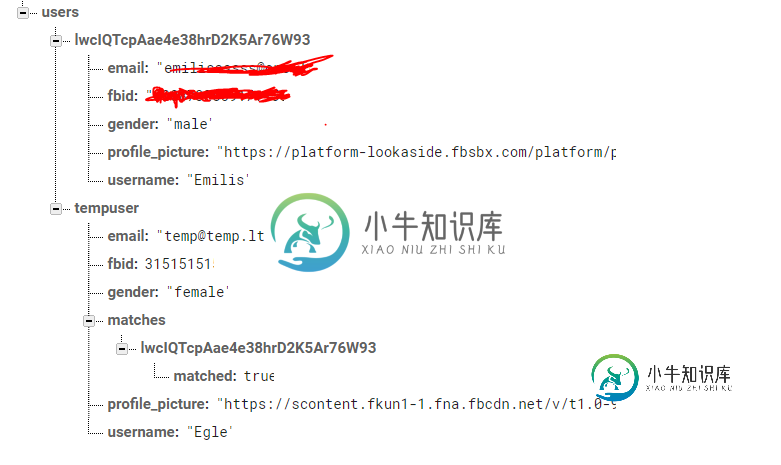 Firebase实时数据库过滤数据
Firebase实时数据库过滤数据所以我正在制作约会应用程序,现在我需要为用户创建一个匹配的人员列表。 因此,我需要一个firebase查询来查看性别,并检查是否已经匹配,如果匹配,则不应将其包括在列表中。 我试着按性别过滤数据。如何编辑此查询以检查它们是否已匹配?匹配项显示在用户/{userID}/Matches/{matchedUserID}中 这是我尝试的:
-
python获取一组数据里最大值max函数用法实例
本文向大家介绍python获取一组数据里最大值max函数用法实例,包括了python获取一组数据里最大值max函数用法实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python获取一组数据里最大值max函数用法。分享给大家供大家参考。具体如下: 希望本文所述对大家的Python程序设计有所帮助。
-
 腾讯云智研发-后台开发面筋
腾讯云智研发-后台开发面筋云智研发 base武汉12.26 - 45min 1、自我介绍 2、项目中难点,实习项目 3、redis缓存设计,缓存击穿如何解决?布隆过滤器原理,如何实现? 4、如何保证redis和mysql的一致性? 5、es为什么这么快 6、es和mysql的一致性如何解决?数据还没同步到es时,此时发了请求,如何解决? 7、了解过Java中的锁吗?讲下synchronized锁原理 8、synchroni
-
 云智研发-暑期后台开发一面
云智研发-暑期后台开发一面感觉问的都挺常见的,深度也不是很深,手撕也是高频的middle,侥幸过了一面,但总的来说还是太菜了,八股缺不少,JAVA的都没问(问了估计更寄),打算不投了再背背八股,学学redis吧。 时间线(TL): 6.20投递 6.25一面(通过)15min实习项目,35min八股,30min手撕 6.26二面(6.28显示暂不匹配,挂) 一面: 0.自我介绍 1.拷问实习项目15min 介绍项目?你说
-
 快手-用户研究实习(电商)
快手-用户研究实习(电商)👥 面试题目:一面 1.自我介绍 2.投递了哪些岗位?为什么想做用户研究? 3.你认为访谈有哪些注意事项?最近一次调研中印象深刻的事情? 4.你是如何进行数据清洗的?(简历项目相关) 5.你运用过的数据分析方法? 6.如果要分析不同性别的满意度是否存在显著性差异,应该运用什么方法(检验)? 👥 面试题目:二面 1.自我介绍 2.对于用户研究的了解? 3.如果要分析不同性别/不同比例的人群的满意
-
Deeplearning4J-如何为大数据迭代多个数据集?
我正在学习用于构建神经网络的Deeplearning4j(Ver.1.0.0-M1.1)。 我使用Deeplearning4j的IrisClassifier作为一个例子,它工作得很好: 对于我的项目,我输入了大约30000条记录(在iris示例-150中)。每个记录是一个矢量大小~7000(在iris示例-4中)。 显然,我不能在一个数据集中处理整个数据--这将为JVM产生OOM。 如何处理多个数
-
创建具有大量数据的android app数据库
问题内容: 我的应用程序的数据库需要填充大量数据,因此在期间,不仅有一些创建表sql指令,而且还有很多插入。我选择的解决方案是将所有这些指令存储在res / raw中的sql文件中,该文件已加载。 它运作良好,但我面对编码问题,sql文件中有一些突出的字符,在我的应用程序中看起来很糟。这是我的代码来做到这一点: 我发现避免这种情况的解决方案是从一个巨大的而不是文件中加载sql指令,并且所有突出的字
-
在Spark中处理大量数据框/数据集/RDD
好吧,我对使用Scala/Spark还比较陌生,我想知道是否有一种设计模式可以在流媒体应用程序中使用大量数据帧(几个100k)? 在我的示例中,我有一个SparkStreaming应用程序,其消息负载类似于: 因此,当用户id为123的消息传入时,我需要使用特定于相关用户的SparkSQL拉入一些外部数据,并将其本地缓存,然后执行一些额外的计算,然后将新数据持久保存到数据库中。然后对流外传入的每条
-
mysql 如何迁移数据流较大的数据库?
数据库日积月累几个G后,从服务器A导入到服务器B 导入数据库总是失败。内存不足或者直接崩了。 请问有什么方案可以稳定的分段导入吗?
-
第十三章:案例研究:数据结构选择
目前为止,你已经学完了 Python 的核心数据结构,同时你也接触了利用到这些数据结构的一些算法。如果你希望学习更多算法知识, 那么现在是阅读第二十一章的好时机。 但是不必急着马上读,什么时候感兴趣了再去读即可。 本章是一个案例研究,同时给出了一些习题, 目的是启发你思考如何选择数据结构,并练习数据结构使用。 词频分析 和之前一样,在查看答案之前,你至少应该试着解答一下这些习题。 习题13-1 编
-
 一面凉经-腾讯技术研究-数据科学
一面凉经-腾讯技术研究-数据科学#我的实习求职记录# 5.8通知,5.9面试,5.10挂 面试官操一口标准广普,上来就是已经看过简历不用你自我介绍了,直接开始问项目,提出了很多很多他对特征工程和模型选择的意见,我解释了自己当时的考虑并表示虚心接受。然后请我介绍了几种模型的原理和AB test,我噼里叭啦解释了一通他就嗯了一下。接着开始各种场景题,想知道某个道具加入能不能提升游戏收入,开发了一款新游想知道它的品质,等等。最后出了道
-
 汉得信息 Java研发 一面
汉得信息 Java研发 一面#面经# #秋招# #上海汉得信息技术股份有限公司# 时间:9.29下午4点 1、自我介绍 2、Mysql 索引是用什么存储的 3、用B+书存储的优势 4、Mysql的事务隔离级别 5、说说数据库的锁 6、InnoDB支持什么锁 7、Spring框架有哪些模块 8、说说对IOC、AOP的理解 9、Spring中Bean的生命周期 10、Spring事务用过吗,原理是什么 11、MyBatis分页原
-
 农行研发中心面试 凉
农行研发中心面试 凉#中国农业银行# 自我介绍中提到了项目 然后三位面试官狂问项目还是vue前端 最后一位面试官问我项目中有没有通过线程池 我刚说了一句我虽然没用过但我了解过 然后就到时间了 让我退出面试了
-
 阿里golang研发二面面经
阿里golang研发二面面经整场面试持续了约1h 自我介绍结束以后简要问了一下之前的实习、项目、离职原因。 基础知识考查: 1. 浏览器寻址url过程? 2. arp表的作用?arp的分组格式?对于主机不存在的apr请求会发生什么? 3. DNS的作用?DNS的解析流程? 4. 下一跳路由转发数据包的过程? 5. go GMP模型是什么?线程与协程的区别?协程调度过程?P、M的数量问题? 6. 协程切换的时机? 7. ch