《大数据研发实习》专题
-
 广发银行研发中心9.15后端开发笔试
广发银行研发中心9.15后端开发笔试30选择题+两道填空题(十个空)+两道编程题 选择题覆盖了Linux、数据库系统(比较多)、高级语言程序设计(写程序运行结果),好像还有前端和计算机网络 填空题其实挺简单的,认真上过课应该会写,我是真的不会数据结构,真的不会。一个是跟判断出入栈的,一个是判断n*n的方格里n个皇后有几种存在方法的。 编程题,看着挺简单,但是我空白了,半年没碰编程了,不知道谁给的勇气碰后端开放岗位。 第一题是输入一个
-
python实时绘制串口数据有很大的滞后性
我正在尝试从串行端口读取数据,并使用matplot在图形中绘制数据。下面是我的代码:我看到由于绘图,有巨大的延迟(队列中的数据高达10000字节),因此我看不到实时绘图。如果我做错了什么,你能帮我一下吗。
-
 大数据面试题—包含真实面经(压力拉满)
大数据面试题—包含真实面经(压力拉满)从事数据开发,手写面试题5W字,涉及hadoop、zookeeper、kafka、spark、flink、clickhouse等常见的大数据中间件,文档可以后台踢我 1、Hadoop特点 hadoop是一个分布式计算平台,能够允许使用编程模型在集群上对大型数据集进行分布式处理 hadoop的三大组件:HDFS(分布式文件存储平台)、MR(计算引擎)、YARN(资源调度平台) 特点: 高扩容:had
-
 大数据面试题—包含真实面经(压力拉满)
大数据面试题—包含真实面经(压力拉满)从事数据开发,手写面试题5W字,涉及hadoop、zookeeper、kafka、spark、flink、clickhouse等常见的大数据中间件,文档可以后台踢我 1、Hadoop特点hadoop是一个分布式计算平台,能够允许使用编程模型在集群上对大型数据集进行分布式处理hadoop的三大组件:HDFS(分布式文件存储平台)、MR(计算引擎)、YARN(资源调度平台)特点:高扩容:hadoop在
-
 百度 Java日常实习 质量效能研发组 一二三面(已OC)
百度 Java日常实习 质量效能研发组 一二三面(已OC)百度面试流程是真的快..这个部门面试总体比较简单。 一面3.14 下午4点(45min) 先写两道算法题 爬楼梯 leetcode11 盛水最多的容器 leetcode70 很简单,直接秒了。然后每道题都问了一下时间复杂度。 自我介绍 项目 技术的选型,为什么 为什么选netty,跟其他通信框架相比有什么优势 websocket 有没有遇到过丢数据的问题(我说的粘包拆包) 维持长连接,心跳的频次
-
 麦当劳-南京研发中心前端实习面经(一面二面OC)
麦当劳-南京研发中心前端实习面经(一面二面OC)应该是最后一篇日常实习面经总结啦!之后如果有面经的话就都是暑期或秋招啦! 仔细一整理才发现自己从11月份到现在居然面了这么多公司 面试时间:11月 面试方式:飞书 一面(30min) css3有哪些新特性 重绘,回流,合成的区别 一些常规JS八股(笔记上没详细记录,忘记了,但肯定没有难的) 之前的项目如何进行性能优化的?首屏优化方案? 了解的webpack配置和这些配置项的作用? webpack优
-
 网易 日常实习 游戏AI研发平台 一二面+HR面(已挂)
网易 日常实习 游戏AI研发平台 一二面+HR面(已挂)搭建AI机器人,AI反外挂的平台,部门用的是Java。 一面 7.14(45min) 自我介绍 实习项目 Kafka集群架构是怎么保证高可用的 粘包拆包 Netty怎么解决的粘包拆包(编解码器) 注册是怎么实现的 Redis lua脚本实现库存预验,讲一下逻辑 这个功能完全可以用代码实现,你为什么采用这个方式实现?目的? Spring和SpringBoot区别 IOC AOP Spring Bea
-
为什么H2数据库文件大小的增长超过了数据大小
我有一个h2数据库文件,文件大小已经增长到5GB。我删除了一些数据以缩小文件的大小。但即使从数据库中删除了一半记录,文件大小仍然保持不变。 我已经尝试了以下所有选项来减少数据库大小,但没有一个对我有用。 我的连接字符串如下所示: 注: 我们正在结清我们已经开始的交易 文件中没有5GB的数据 有人能给我建议一些解决方法或修复方法来减少我的数据库大小吗
-
Spring数据排序操作超出最大大小
我是相当新的Spring和MongoDB,并有一个问题,从我的MongoDB拉数据。我试图获得相当大的数据量,并收到以下异常: 执行器错误:操作失败:排序操作使用超过最大33554432字节的RAM。添加索引,或指定一个较小的限制。;嵌套异常是com.mongodb.MongoExc0019: Execator错误:操作失败:排序操作使用超过内存的最大33554432字节。添加索引,或指定较小的限
-
Neo4j查找数据库的最大字节大小
我找到了关于如何计算neo4j数据库大小的以下信息:https://neo4j.com/developer/guide-sizing-and-hardware-calculator/#_disk_storage
-
加载大于 h2o 中内存大小的数据
我正在尝试在h2o中加载大于内存大小的数据。 H2o博客提到: 下面是连接到h2o 3.6.0.8的代码: 给 我试着把一个169 MB的csv加载到h2o中。 这抛出了一个错误, 这表示内存溢出错误。 问:如果H2opromise加载大于其内存容量的数据集(如上面的博客引述所说的交换到磁盘机制),这是加载数据的正确方法吗?
-
Angularjs-表单发布数据未发布?
问题内容: 我必须承认我有点困惑…我以前从未做过,而且我显然缺少一些东西 当我通过http.post将数据传递到我的php文件时,我似乎无法收集数据… 有人可以告诉我为什么这行不通吗? FormData会显示在控制台日志中,并且可以确定正在写入文件。但是,看起来好像没有数据传递。 这是在我的php文件中。试图将提交表单中的数据写入文件中(只是测试)。 问题答案: 经过大量研究后,我发现这有点像ph
-
大数据数仓高级面试题 3
主要内容:1.建模锯齿,2.数据粒度的锯齿操作,3.下游表依赖上游表问题,4.数仓数据域划分方式,5.数仓一致性是如何保证的,6.数仓优化,7.数据全生命周期,8.数仓建模问题,9.数仓建模过程1.建模锯齿 建模锯齿是指在建模过程中的一种常见的效应,其中模型的输出可能会产生锯齿状的波动。这种效应通常是由于模型的不稳定性或过度拟合导致的。 在建模过程中,锯齿可能会使模型的表现变差,并且在预测新数据时也可能出现不一致的结果。因此,在建模时需要注意避免出现锯齿状的波动。 一种常用的方法是使用正则化来限
-
大数据数仓高级面试题 1
主要内容:1.数仓高内聚低耦合,2.多重粒度,3.如何提高查询效率,4.数仓数据域划分几种方式,5.粒度操作,6.SQL实现,7.数仓中ODS层命中多少为合理,8.数仓价值链的体现和实现,9.建立数仓的步骤,10.指标生命周期的评估,11.数据治理,12.数仓的目的1.数仓高内聚低耦合 一般复杂的公共逻辑可以采用抽象类和抽象方法的方式下沉到共有模块中,然后由相关子类去实现抽象方法,来实现不同的功能。这样可以将复杂的逻辑拆分成各个子类,使得类之间的耦合度降低,提高代码的可维护性。 2.多重粒度 在
-
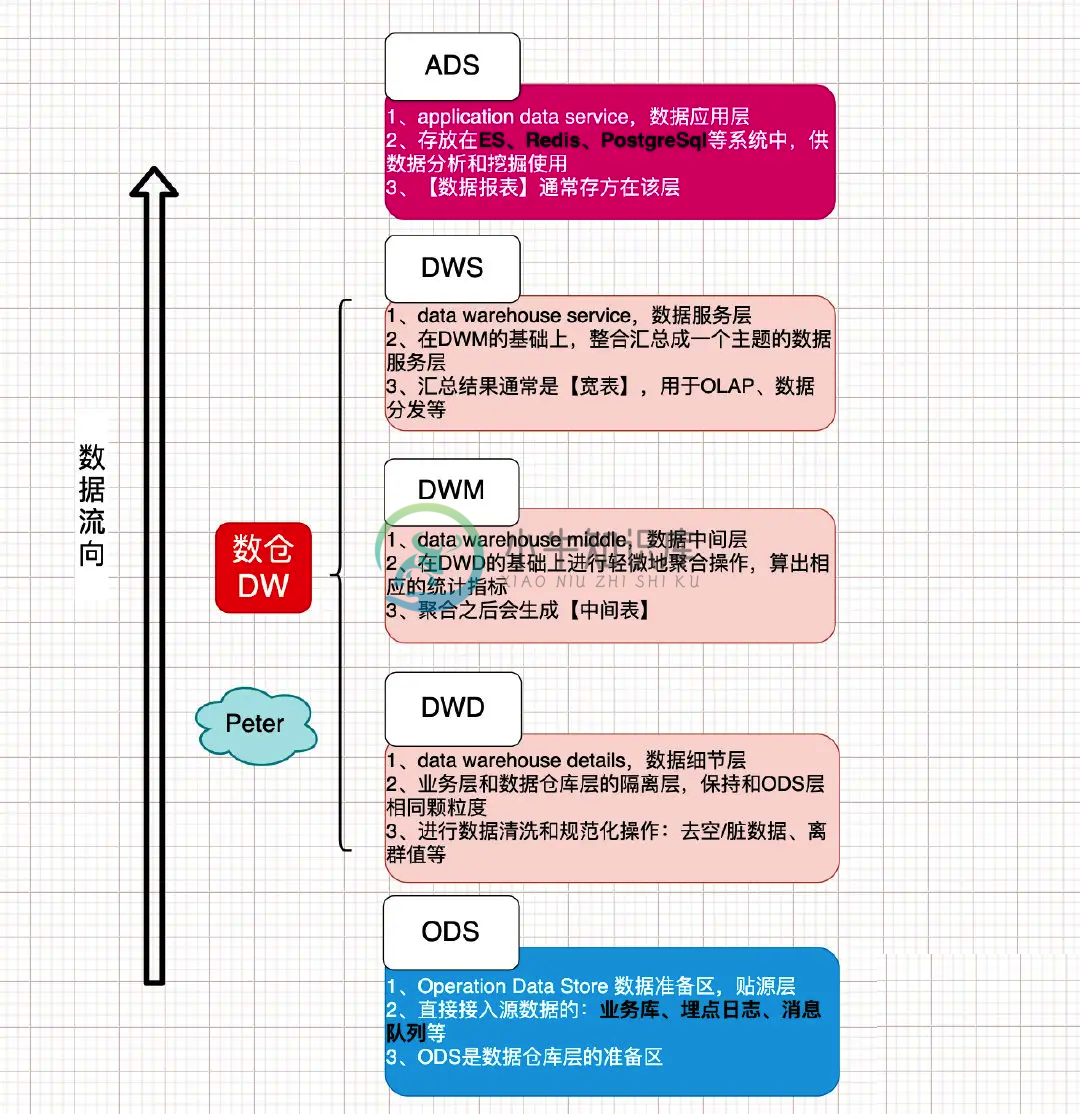 大数据数仓高级面试题 4
大数据数仓高级面试题 4主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括