《大数据研发实习》专题
-
 联通数科数据开发
联通数科数据开发联通数科-数据开发 三四个面试官挨个提问 1.自我介绍 2.针对简历问了项目和实习 3.一个简单的sql题 口述 表中有id不重复和邮箱重复 找出重复邮箱… 愣了一下 因为题目说的很简短没有其他要求 然后就回答 对邮箱groupby count一下 面试官说没问题 4.询问使用过的数据库 (不大记得原话是啥,细问了一下是说olap存储引擎吗? 面试官说是 像ck、hbase、doris)回答:使用
-
1.5.3.2.17 实时数据
随着实时数据量的迅速增长,人们对数据能够即时显示在手机、计算机上的需求越来越强烈。客户端与服务器之间对实时数据传输一般采用 WebSocket 协议、TCP 协议、HTTP 协议以及 Kafka 专用通讯协议等,可传输的数据格式包括 CSV、JSON 、GeoJSON等。 本节以查询一个线数据为例,每两秒将一个点通过 dataFlowService 传输给服务器,用来模拟实时数据。 //实例化 D
-
从多维数组中放大数据
问题内容: 我是PHP的新手,我需要针对以下问题的快速解决方案,但似乎无法提出一个解决方案: 我有一个像这样的多维数组 我想使用来以某种方式返回包含逗号的字符串分隔字符串,像这样。 通过上述功能有可能达到这种效果吗?如果没有,请提出替代解决方案。 问题答案: 非常简单: 以及php v5.5.0中的新功能:
-
 SqlServer 数据库 三大 范式
SqlServer 数据库 三大 范式本文向大家介绍SqlServer 数据库 三大 范式,包括了SqlServer 数据库 三大 范式的使用技巧和注意事项,需要的朋友参考一下 1 概述 一般地,在进行数据库设计时,应遵循三大原则,也就是我们通常说的三大范式,即第一范式要求确保表中每列的原子性,也就是不可拆分;第二范式要求确保表中每列与主键相关,而不能只与主键的某部分相关(主要针对联合主键),主键列与非主键列遵循完全函数依赖关系,
-
neo4j中的大数据导入
我正在导入大约1200万个节点和1300万个关系的数据。 是否可以在短时间内直接从sql导入这些数据,因为neo4j以其快速处理大数据而闻名?有什么建议或帮助吗? 以下是CSV使用的加载(数字上的索引(num)):
-
Postgres数据库大小命令
查找所有数据库大小的命令是什么? 我可以使用以下命令找到特定数据库的大小:
-
 蔚来大数据笔试 7.17
蔚来大数据笔试 7.17第一题合并两个二叉树lc617 第二题爬楼梯,多少种爬法,10000级楼梯 第三题滑动窗口的最大值lc239 #蔚来提前批笔试#
-
 京东方大数据面试
京东方大数据面试7.22一面 spark的底层原理 spark yarn client和yarn cluster的区别 dataframe如何创建 数仓项目中用了几个节点,各个组件如何部署的 HA介绍一下 数仓分层介绍 hadoop的一些命令 hadoop如何更改文件所有者 kafka的监控 linux命令,vim编译器的命令 集群间节点是如何通信的 core-site文件一般配置什么内容 ranger权限管理的
-
 万兴科技 23大数据
万兴科技 23大数据9.17 HR面 素质面 15分钟 基本上跟二面差不多,说要横向比较一周后给结果。 ----- 9.14 二面 素质面 40分钟 1.为什么工作后去考研 2.你觉得数据开发的这份工作价值在哪里 3.你对万兴科技了解多少 4.你未来三年的职业规划是什么样的 5.你的项目的背景、价值、开发过程、开发人数、你扮演什么角色,你的价值体现在哪里 基本上没有技术问题,都是素质考察。 ----- 9.9 一面
-
 大华数据挖掘面经
大华数据挖掘面经硕士研究cv 可能和数据挖掘不是那么匹配~ 大华一面(1h): 1、增量学习的科研项目(问了具体的细节 以及为什么) 2、语义分割的发展 3、UNet中的跳跃连接的作用 4、残差网络的shortcut连接的作用,数学方面证明残差网络可以避免梯度消失,并且问了一个关于残差网络的改进问题(面试官看最新的论文看到的,我没有理解他所说的问题) 5、宫颈肿瘤分割和pcr预测的项目(细节也问的很详细) 6、预
-
 数据挖掘十大算法
数据挖掘十大算法数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
-
第15章 大数据与MapReduce
大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力。 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则随意浏览后就离开。 对于你来说,可能很想识别那些有购物意愿的用户。 那么问题就来了,数据集可能会非常大,在单机上训练要运行好几天。 接下来:我们讲讲 MapRedece 如何来解决这样的问题 MapRedece Hadoop 概述 Ha
-
 10.14-东方电子-大数据
10.14-东方电子-大数据面试时间:30min 自我介绍 HR常规询问,成绩排名、英语六级、籍贯、家庭、独生子女,高考分数。 研究生日常,工作学校都是怎么安排的?实习日常,加班情况? 实习项目介绍,背景,技术栈? Lamda架构介绍?为什么这么设计?流批一体概念? 技术选型考虑的问题? 选择OLAP数据库的依据?Clickhouse介绍? 研究方向介绍,论文情况,模型和创新点?工程落地? 对公司的意向度? 反问:部门业务?
-
 美团大数据一面凉
美团大数据一面凉自我介绍 手撕,股票最大利润 sql 成绩排名三 数仓分层 数据倾斜 遇到的问题 为什么要分层 分析了哪些指标 介绍一下spark 介绍一下hadoop 介绍一下hbase 反问 不知道哪的问题,又凉了面了这么多0offer
-
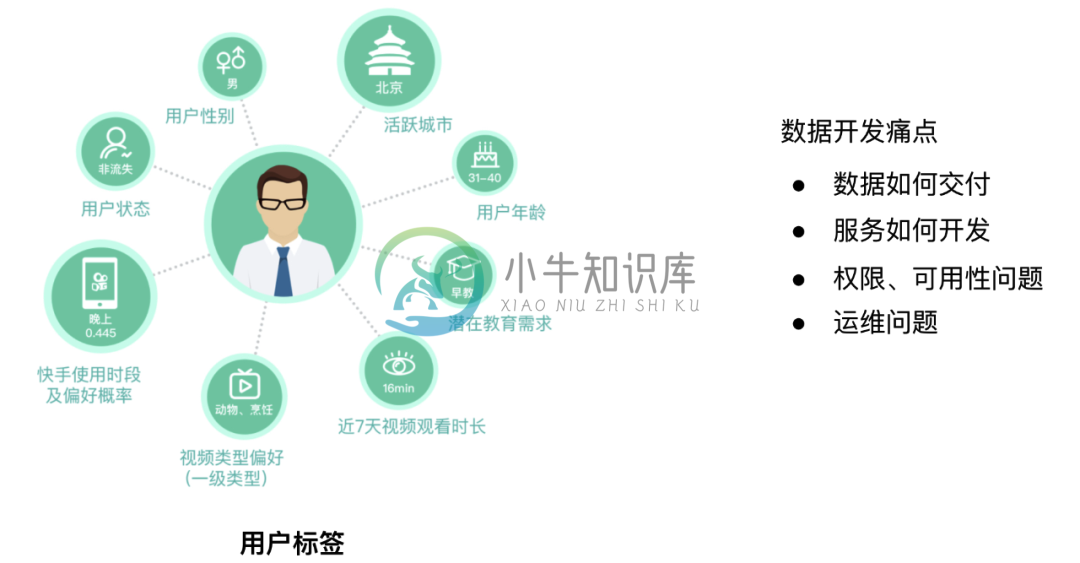 大厂数据中台建设
大厂数据中台建设主要内容:1.现有数据存在的问题,2.系统架构1.现有数据存在的问题 1.1 开发数据服务门槛高 数据开发工程师除了开发完数据表外,通常还需要思考如下问题: 数据如何交付:业务通常期望使用数据接口方式来使用数据,而非数据表,这会更加灵活、解耦、高效。数据开发工程师因此需要建立对应的数据服务 服务如何开发:数据服务有多种形式,通常要求开发工程师有微服务知识、服务发现注册、高并发等 权限、可用性问题:开发完数据服务后,需要考虑权限问题,确保数据资