《大数据求职》专题
-
将大文件中的数据分块进行多处理?
问题内容: 我正在尝试使用多重处理来并行化应用程序,该处理程序会处理一个非常大的csv文件(64MB至500MB),逐行执行一些工作,然后输出一个固定大小的小文件。 目前,我正在执行,不幸的是,它已完全加载到内存中(我认为),然后我将该列表分成了n个部分,n是我要运行的进程数。然后,我在分类列表上执行。 与单线程,仅打开文件并迭代的方法相比,这似乎具有非常非常糟糕的运行时。有人可以提出更好的解决方
-
MySQL数据库表分区注意事项大全【推荐】
本文向大家介绍MySQL数据库表分区注意事项大全【推荐】,包括了MySQL数据库表分区注意事项大全【推荐】的使用技巧和注意事项,需要的朋友参考一下 表分区与数据库分区是不一样的那么碰到表分区使用时我们要注意一些什么事情呢,今天我们来看一篇关于MySQL数据库表分区注意事项的细节。 1、分区列索引约束 若表有primary key或unique key,则分区表的分区列必须包含在primary ke
-
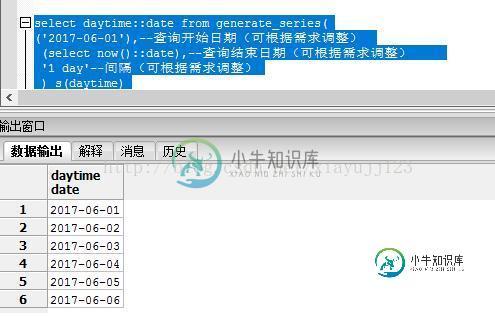 postgresql 实现取出分组中最大的几条数据
postgresql 实现取出分组中最大的几条数据本文向大家介绍postgresql 实现取出分组中最大的几条数据,包括了postgresql 实现取出分组中最大的几条数据的使用技巧和注意事项,需要的朋友参考一下 看代码吧~ 其中 执行结果: 添加行序号:ROW_NUMBER () OVER (ORDER BY A.bsm ASC) AS 序号 分组添加序号:ROW_NUMBER () OVER (PARTITION BY xzqdm ORDER
-
传递大量数据的查询的最佳MySQL设置?
问题内容: 我从事科学家工作,并使用MySQL作为数值模拟结果的存储库。通常,我有一组通过实验获得的数据和一个对照组。这两个数据集存储在一个表中。一个指示符字段告诉我记录是来自实验还是来自控件集。该表通常具有约1亿条记录。5000万次实验和5000万个控件。 在对数据进行后处理时,我的典型任务是首先发出以下两个查询: 和 我在RC,df上有一个多列索引。这些查询会花费大量时间,而查询会花费大部分时
-
MySQL快速从大型数据库中删除重复项
问题内容: 我有大的(>百万行)MySQL数据库被重复弄乱了。我认为这可能是充满它们的整个数据库的1/4到1/2。我需要快速摆脱它们(我是指查询执行时间)。外观如下: id(索引)| text1 | text2 | text3 text1&text2组合应该是唯一的,如果有重复项,则仅应保留一个text3 NOT NULL组合。例: …成为: 新的id可以是任何东西,它们不依赖于旧表的id。 我已
-
在MySql INSERT命令中写入大量数据哪个好?
我有大约400K的数据,也许更多(以sql格式),并将它插入到mysql数据库。哪一个性能更好,在sql文件中写sql命令插入数据: > 对每个数据重复此命令,直到400k 在表(col1、col2、coln)中插入值(val1、val2、valn)、(val1、val2、valn)、(val1、val2、valn)、.....[直到100个数据] 在表(col1,col2,coln)中插入值(v
-
图表-具有不同大小数据集的折线图
我正在开发一个应用程序,它将生成一些图表,我正在使用chartjs来绘制它们。 我面临的问题是:图表将用动态数据生成。应用程序最多可以生成9个数据集,很少会有相同的大小。当数据集大小不匹配时,如何使图表提前或填充值? 我在stackoverflow甚至在chartjs github页面上看到了一些例子,但它们对我不起作用。 这是我目前所拥有的一个示例:https://jsfidle.net/cam
-
从Python中的数据帧的行中获取最大值
问题内容: 这是我的数据框df 我正在尝试从数据帧的每一行中获取最大值,我期望这样的输出 这就是我尝试过的 我没有得到正确的输出,任何帮助将不胜感激。谢谢 问题答案: 使用有: 如果需要新列:
-
mysql大批量插入数据的4种方法示例
本文向大家介绍mysql大批量插入数据的4种方法示例,包括了mysql大批量插入数据的4种方法示例的使用技巧和注意事项,需要的朋友参考一下 前言 本文主要给大家介绍了关于mysql大批量插入数据的4种方法,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 方法一:循环插入 这个也是最普通的方式,如果数据量不是很大,可以使用,但是每次都要消耗连接数据库的资源。 大致思维如下 (我这里写
-
 浅谈用Python实现一个大数据搜索引擎
浅谈用Python实现一个大数据搜索引擎本文向大家介绍浅谈用Python实现一个大数据搜索引擎,包括了浅谈用Python实现一个大数据搜索引擎的使用技巧和注意事项,需要的朋友参考一下 搜索是大数据领域里常见的需求。Splunk和ELK分别是该领域在非开源和开源领域里的领导者。本文利用很少的Python代码实现了一个基本的数据搜索功能,试图让大家理解大数据搜索的基本原理。 布隆过滤器 (Bloom Filter) 第一步我们先要实现一个布
-
 php+ajax导入大数据时产生的问题处理
php+ajax导入大数据时产生的问题处理本文向大家介绍php+ajax导入大数据时产生的问题处理,包括了php+ajax导入大数据时产生的问题处理的使用技巧和注意事项,需要的朋友参考一下 遇到的问题就从先到后的一一说吧。 问题1 按照我最初的想法,先上传文件再读取文件。这里问题就来了,当文件较大的时候上传较慢,导致客户看到的操作一直处于等待状态,不人性化。 处理办法:我是这样做的,大神有更好的办法,求介绍。我先把文件上传上去,然后把文件
-
 更强大的vue ssr实现预取数据的方式
更强大的vue ssr实现预取数据的方式本文向大家介绍更强大的vue ssr实现预取数据的方式,包括了更强大的vue ssr实现预取数据的方式的使用技巧和注意事项,需要的朋友参考一下 我在前几天的一篇文章中吹了两个牛皮,截图为证: 现在可以松口气的说,这两个牛皮都实现了,不过 vue-suspense 改名了,叫做 vue-async-manager 了,他能帮你管理 Vue 应用中的异步组件的加载和 API 的调用,提供了与 Reac
-
基于列的最大值删除熊猫数据帧行
我有这样一个数据帧: 我如何摆脱第四行,因为它有sq_resid的最大值?注意:最大值将从一个数据集更改到另一个数据集,所以仅仅删除第4行是不够的。 我已经尝试了一些方法,比如我可以删除像下面这样留下数据帧的最大值,但是无法删除整行。
-
Hadoop对数据流不太大的系统有开销吗?
我计划编写一个批处理分布式计算系统,它将使用大约10-20台计算机。系统某些部分的数据流约为50GB,其他部分的数据流约为1GB。 我正在考虑使用Hadoop。可扩展性并不重要,但我真的很喜欢Hadoop framewok提供的容错和推测运行功能。MPI或gearman等框架似乎不提供这样的机制,我将不得不自己实现它们。 然而,我有一些疑问,因为它似乎是针对更大的数据量和可能更多的计算机进行优化的
-
将大写应用于Python中Pandas数据框中的列
本文向大家介绍将大写应用于Python中Pandas数据框中的列,包括了将大写应用于Python中Pandas数据框中的列的使用技巧和注意事项,需要的朋友参考一下 在本教程中,我们将看到如何在DataFrame中使名称列变为大写。让我们看看实现目标的不同方法。 示例 我们可以使用upper()方法将其大写,从而为DataFrame分配一列。 让我们看一下代码。 输出结果 如果运行上面的程序,您将得