《大数据求职》专题
-
在oracle SP中用更大的数据类型替换varchar2
我使用的是oracle verion 10。PL/SQL中存在使用varchar2变量的存储过程。代码不断追加varchar2变量。当varchar2变量大小超过32767时,它不能追加任何值。现在我想将数据类型更改为long或clob(为了容纳更多的字符),但它不起作用。如何修改这里的代码,使其具有与clob或LONG相同的附加功能? 示例附加x:=x'mydata';
-
将大量数据写入 TD 引擎时出现问题
我正在尝试将我的应用程序移植到TDEngine,该应用程序通过其无模式接口将ImpxDb数据写入TDEngine。我认为这应该很容易,但实际上并不容易。 爪哇代码如下: 我在控制台上得到了结果: 传感器,设备 Id=传感器0 电流=10.2,json$j=“{”f6“:”tt“,”f7“:”aa“,”f0“:”tt“,”f1“:”aa“,”f2“:”tt“,”f3“:”aa“,”f4“:”tt“,
-
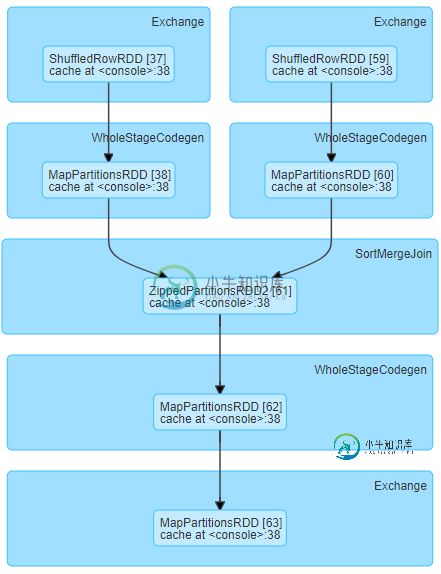 火花洗牌读取小数据需要大量时间
火花洗牌读取小数据需要大量时间我们正在运行以下阶段DAG,对于相对较小的洗牌数据大小(每个任务约19MB),我们经历了较长的洗牌读取时间 一个有趣的方面是,每个执行器/服务器中的等待任务具有等效的洗牌读取时间。这里有一个例子说明了它的含义:对于下面的服务器,一组任务等待大约7.7分钟,另一组等待大约26秒。 这是同一阶段运行的另一个例子。该图显示了3个执行器/服务器,每个执行器/服务器具有相同的洗牌读取时间的统一任务组。蓝色组
-
优化数据流池大小以提高点火性能
我正在使用ignite2.6,其中有数据流节点,从kafka消耗数据并放入Ignite缓存。服务器平均负载较高,吞吐量降低。 我已经尝试为缓存中定义的索引内联设置索引大小,这样可以提供良好的性能,但也增加了服务器内存利用率和较高的平均负载。请说明在这种情况下增加datastreamer线程池大小会产生什么影响。
-
如何确定Apache Spark数据帧中的分区大小
我一直在使用SE上发布的问题的一个极好的答案来确定分区的数量,以及跨数据帧的分区分布需要知道数据帧Spark中的分区详细信息 有人能帮我扩展答案来确定数据帧的分区大小吗? 谢谢
-
 思必驰大数据日常实习岗位面经(OC)
思必驰大数据日常实习岗位面经(OC)找了半个月的实习,面试了20多家,在同程HR面之后还被挂的惨痛经历之后,终于找到了一家不错的公司。(现在大环境下大数据实习太难找了,基本都是外包要人,BAT我都是一面挂,有些是简历挂) 下面讲讲我记得的一些问题 一面(40分钟) 自我介绍 熟悉二叉树吗,细说有多少种二叉树,哪些二叉树是用来排序的,并且将各个树的特点讲讲 了解MySQL存储引擎嘛,说说自己看法 计算机网络,TCP,UDP区别。Htt
-
 字节大数据开发-人力科技面经(已凉)
字节大数据开发-人力科技面经(已凉)字节大数据开发工程师- 人力科技面经 一面 网络模型,每一层的功能 访问一个网页的流程 tcp是如何保证可靠 线程和进程的区别 JVM的内存区域 垃圾回收算法 类加载的过程 Spark和MR的区别 Spark任务调度过程 spark中stag,job,task是如何划分的 spark宽窄依赖 为什么spark比MR快 Hadoop的框架 Hadoop提交作业的流程 Hadoop中是如何找到文件对应
-
 网易云音乐 大数据开发工程师 1面
网易云音乐 大数据开发工程师 1面30min 1. 自我介绍 2. 为什么走大数据 3. 项目介绍 4. hive和spark的区别 5. MR和spark有哪些区别,分别适用什么场景 6. 为什么不选择spark做离线 7. 开窗函数有哪些 8. 数仓怎么设计的 9. ODS层存在的意义 10. DWD和DIM怎么设计的,有什么指标 11. DWS层存放的哪些指标 12. 下一步准备学习什么?怎么学习? 反问 1. 部门做什么业
-
 深圳闻泰科技 大数据开发 技术面经
深圳闻泰科技 大数据开发 技术面经1、自我介绍 2、什么是维度建模?什么是关系建模? 3、星型模型和雪花模型有什么区别? 4、数据仓库分层的意义是什么? 5、对哪些大数据框架比较熟悉?(答了Hadoop和Kafka) 6、Hadoop的进程有哪些?作用分别是什么? 7、Kafka的特点是什么? 8、Kafka为什么可以支持海量数据吞吐? 9、问实习工作内容,以及实习收获 10、能否接受加班? 11、有什么问题要问我的?问了日常工作
-
 携程 大数据底层框架开发 面经回顾
携程 大数据底层框架开发 面经回顾去年秋招拿了携程-大数据底层框架开发岗位的offer,想着还是把面试回顾下吧,给后面的朋友一个参考。 这个岗位是做大数据组件底层二次开发的,我面试的是偏向离线方面,因此面试都是围绕hadoop、spark、hbase、hive这几个组件的底层原理去问,因为是偏向底层,所以也会注重java语言和多线程并发的知识。 HDFS的写入流程?如果一台机器宕机,HDFS怎么保证数据的一致性?如果只存活一台机器
-
 爱奇艺风控大数据Java日常实习(已OC)
爱奇艺风控大数据Java日常实习(已OC)选一个你觉得做的最好的项目,说一说 深挖项目,多问为什么这样设计,为什么这样做 选一个Java的项目,说一下 三级缓存是怎么实现的 那么一级缓存(nginx访问redis)和三级缓存redis的区别是什么,去掉了三级缓存可以么 介绍一下令牌桶算法数据结构,和漏斗桶的区别,为什么选令牌桶不用漏斗桶 如何保证mq消费者端更新数据库可以成功 如何保证消息可以不重复消费,使用redis做幂等是完全安全的么
-
 国企金融科技部门大数据实习面经
国企金融科技部门大数据实习面经目前已offer。 面试内容: 1.自我介绍:我就说了一下学校专业学的课然后之前的几段实习是做什么的。 2.SQL:这一块没有问具体的题目,问了一些窗口函数比如三个求rank的函数,sum() over 和groupby求和的区别,join后面跟where和on的区别,inner join 和left join使用场景这种,其他的记不清了。 3.Hadoop:问了Hadoop的组成,操作HDFS的
-
 多益网络 —— 大数据开发工程师 —— HR面挂
多益网络 —— 大数据开发工程师 —— HR面挂HR面感觉挺好的不知道咋挂了 1、自我介绍 2、如何看待实习和学校学习 3、期望薪资 (感觉是这个问题,我答的是:该岗位一般是10k-15k,所以我觉得不能少于10k) 3、为什么来广州,为什么不在武汉找工作 4、手里有Offer 吗,不满意的点,(我答的薪资和公司文化) 5、抽取的问卷题,物业不让养狗,怎么看 今天看到消息,挂掉了,没搞懂为何挂了,自我感觉答得还不错,也不紧张 心里还好没有多大落
-
 58同城大数据开发工程师面经(一面)
58同城大数据开发工程师面经(一面)开局自我介绍,然后问我两段实习经历,分别做了什么?照实回答,问我有没有接触过BI工具,我说是内部封装好的;日常工作,处理的数仓规模,人员规模,主要负责内容,处理的数据的大小。之后让我写一道题目,求连续三天消费金额大于100的用户ID,不想用排序函数再写了所以用了LAG函数来写,面试官给了我一个不置可否的表情(坏了可能写错了......)然后说我明白你的思路了,我解释说因为不想用排序函数来写所以尝试
-
 天翼云 大数据开发工程师 二面 面经
天翼云 大数据开发工程师 二面 面经投递岗位:大数据开发工程师(广州) 时间线:9.5投递,9.13技术一面,9.17技术+hr二面,9.19测评,10.7 意向 JD如下,岗位偏数据平台建设,非数仓 面经 技术 自我介绍 项目中最大的收获是什么,数据治理讲一下 hive分区表怎么创建(具体到关键字),分区的好处,怎么设计分区 hive分桶表怎么创建(具体到关键字),分桶的好处 hive外部表建表语句 (具体到关键字) hive s