《阿里云分布式块存储》专题
-
如何启用分布式/集群缓存时使用redis与Spring数据高速缓存
如何启用分布式/集群缓存时使用Redis与缓存。 尤其是通过
-
1.3.3.5 分布分析
1. 简介 分布分析报告可以帮助您查看事件在不同区间的发生频次,从而判断用户的使用习惯和活跃情况。除了次数,您还能够查看其它事件指标的用户数量分布。 分布分析能够帮助您洞察这些问题: · 对比不同来源渠道的用户在站点的行为次数分布,如浏览页面1-3次,3-10次,10次以上,不同区间的用户数量有多少 · 上周推广活动客单价的人数分布情况 · 改版后,用户的每日启动次数是否增加 2. 使用说明 2
-
集中式网络,分散式网络和分布式分类帐之间有什么区别?
本文向大家介绍集中式网络,分散式网络和分布式分类帐之间有什么区别?相关面试题,主要包含被问及集中式网络,分散式网络和分布式分类帐之间有什么区别?时的应答技巧和注意事项,需要的朋友参考一下 回答: 分布式分类帐:这是共享分类帐,不受任何中央机构的控制。它本质上是分散的,并充当金融,法律或电子资产的数据库。 集中式网络:集中式网络具有中央机构以方便其操作。 分散网络:分散网络中连接的节点不依赖于单个服
-
基于google云存储的云CDN开发
新手问题:我想使用一个云存储桶作为云CDN的原点。不确定这是否可能。目前,我已经为负载均衡器打开了CDN,但我的理解是,它将只缓存来自我的domain.com的内容,并有适当的标题集。当然,我们的假设是,CDN pops比bucket离我的用户位置更近,而bucket离我的用户位置更远,并且从CDN中获取比使用bucket URL(主要是静态图像)更快。谢了。
-
阿里云Linux CentOS 7.2下自建MySQL的root密码忘记的解决方法
本文向大家介绍阿里云Linux CentOS 7.2下自建MySQL的root密码忘记的解决方法,包括了阿里云Linux CentOS 7.2下自建MySQL的root密码忘记的解决方法的使用技巧和注意事项,需要的朋友参考一下 验证环境: 首先确认服务器出于安全的状态,也就是没有人能够任意地连接MySQL数据库。 因为在重新设置mysql的root密码的期间,MySQL数据库完全出于没有密码保护的
-
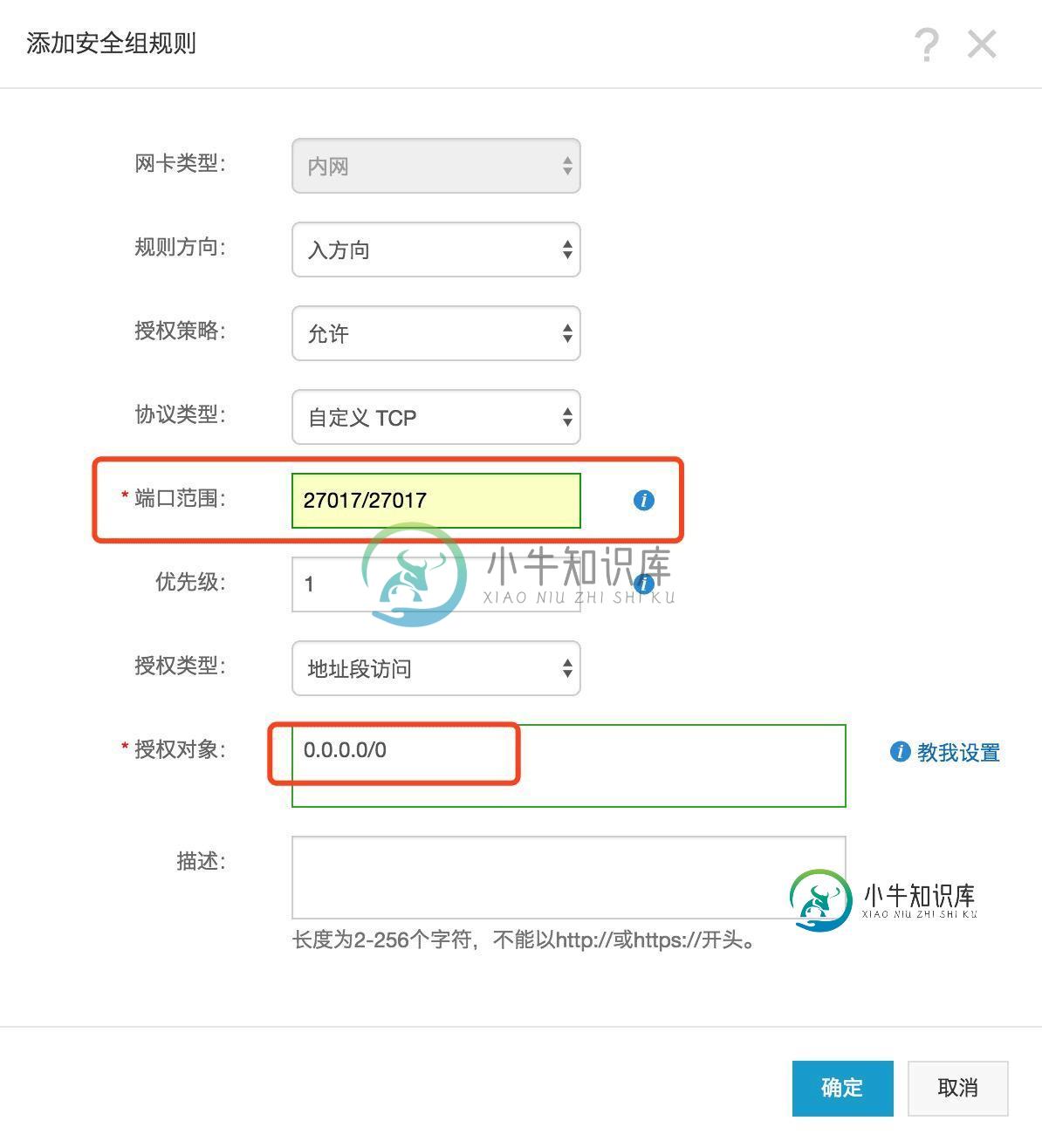 node链接mongodb数据库的方法详解【阿里云服务器环境ubuntu】
node链接mongodb数据库的方法详解【阿里云服务器环境ubuntu】本文向大家介绍node链接mongodb数据库的方法详解【阿里云服务器环境ubuntu】,包括了node链接mongodb数据库的方法详解【阿里云服务器环境ubuntu】的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了node链接mongodb数据库的方法。分享给大家供大家参考,具体如下: 一、安装2.6版本以上的mongodb在云服务器上(百度就能查到安装方法,以及验证是否安装成功一般是
-
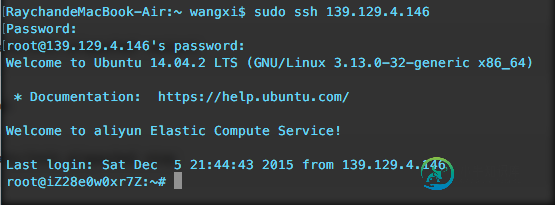 mac下配置和访问阿里云服务器(Ubuntu系统)的图文教程
mac下配置和访问阿里云服务器(Ubuntu系统)的图文教程本文向大家介绍mac下配置和访问阿里云服务器(Ubuntu系统)的图文教程,包括了mac下配置和访问阿里云服务器(Ubuntu系统)的图文教程的使用技巧和注意事项,需要的朋友参考一下 1、购买云服务器(http://www.aliyun.com/?spm=5176.3047821.1.1.vHFBuw) 注册帐号,在产品页面选择合适的服务器,进入详细页面选择配置,购买。 购买完成后进入管理控制台—
-
后端 - 可以自己搭建阿里云服务器合法访问国外吗?
在阿里云上自己搭建服务器,是不是就可以合法访问国外了?
-
1.3.3 分析云
事件分析 例行导出服务
-
Logistic分布
Logistic分布 Logistic分布的定义: 设$$X$$是连续随机变量,$$X$$服从Logistic分布是指具有下列分布函数和密度函数: $$ F(x)=P(X\leqslant x)= \dfrac{1}{1+e^{-(x-\mu)/\gamma}} $$ $$ f(x)=F'(X\leqslant x)= \dfrac{e{-(x-\mu)/\gamma}}{\gamma(1+e{-
-
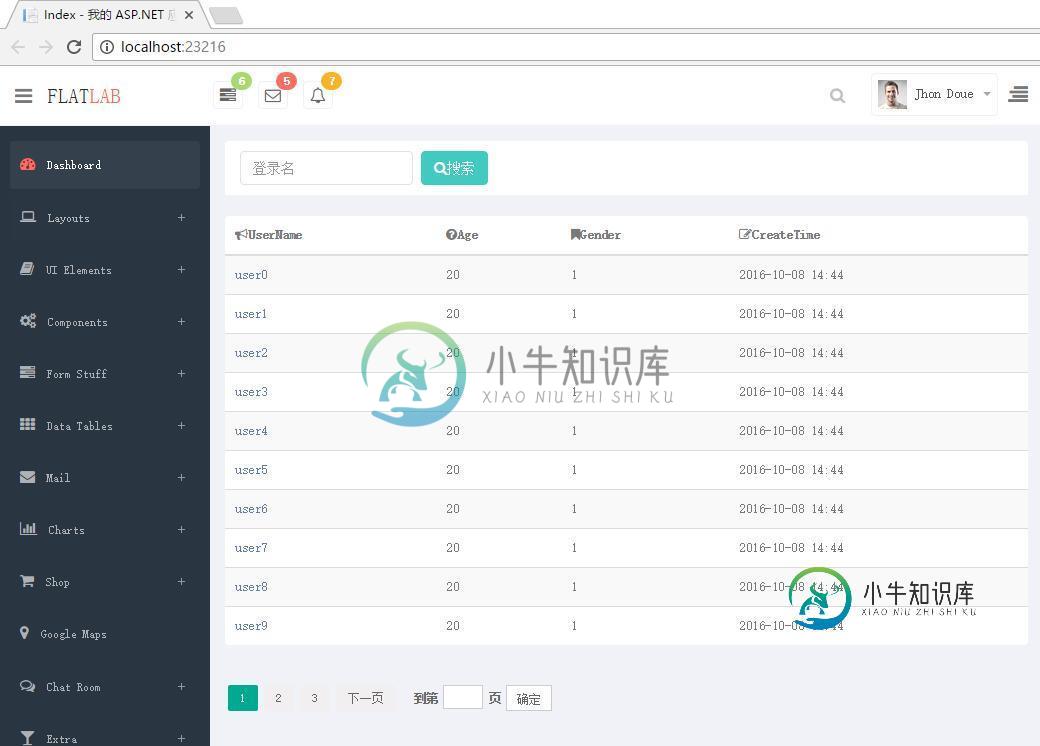 mvc 、bootstrap 结合分布式图简单实现分页
mvc 、bootstrap 结合分布式图简单实现分页本文向大家介绍mvc 、bootstrap 结合分布式图简单实现分页,包括了mvc 、bootstrap 结合分布式图简单实现分页的使用技巧和注意事项,需要的朋友参考一下 分页采用laypage使用起来比较简单但是功能很齐全,数据库访问使用petapoco,bootstrap用的是flatlab模版,采用mvc的repository模式。 先来一张效果图; 下面来看具体实现; Controller
-
 实例讲解分布式缓存软件Memcached的Java客户端使用
实例讲解分布式缓存软件Memcached的Java客户端使用本文向大家介绍实例讲解分布式缓存软件Memcached的Java客户端使用,包括了实例讲解分布式缓存软件Memcached的Java客户端使用的使用技巧和注意事项,需要的朋友参考一下 Memcached介绍 下面就来介绍一下Memcached。 1、什么是Memcached Memcached是一个开源的高性能,分布式的内存对象缓存系统,通过键值队的形式来对数据进行存取,Memcached是简单而
-
具有分布式查询模型的Axon寄存器跟踪处理器
我使用axon和Spring-Boot实现了CQRS+ES应用程序。我使用单独的查询模型和命令模型应用程序。我使用rabbitmq从命令模式发布事件。它工作正确。但是跟踪处理器实现在我的应用程序中不工作。 这是yml配置 我怎么才能做正确。(有人能推荐教程或代码示例吗)
-
从群集中的Ignite本地缓存获取分布式查询数据
我在启用了本地模式集群(由2个服务器组成)中的每个节点上都有名为“igniteCache”的Ignite缓存。一定数量的条目被加载到这些本地缓存中。现在,我已经启动了单独的客户机节点,它从集群上的“igniteCache”查询数据。但当我查询数据时,总是得到空结果(而不是从两个服务器节点获取数据)
-
如何在分布式模式下运行Kafka-connect-replicator?
我想使用 Confluent 的复制器将数据从一个系统复制到另一个系统。我正在使用两个Ubuntu 18.04系统,其中一个充当源,另一个充当目的地。 我尝试在分布式模式下运行kafka connect replicator,更改了以下配置: < li >在confluent/etc/Kafka/server . properties中,我做了以下更改 源 目的地 然后,我在源系统中创建了主题,并