《数分面经》专题
-
 得物秋招Java一面30分钟
得物秋招Java一面30分钟实习和项目挑一个熟悉的说一下难点 围绕项目进行场景题拷打 穿插几个八股 消息队列的原理 消息队列的架构 怎么保证顺序消费 为什么redis用跳表不用红黑树不用b➕树 为什么hashmap用红黑树不用其他两个 为什么数据库用b➕树不用其他两个 反问无手撕,准时三十分钟结束 #软件开发笔面经#
-
 人保科技二面(三十分钟:三位面试官)
人保科技二面(三十分钟:三位面试官)第一位面试官 现在找工作的方向或者类型是? 互联网实习为什么来国企? 手头有offer么? 学习经历:建模大赛选择的题目是什么?解决方案? 实习 前端比较新的技术?答了react18和vue3,面试官感觉不是很满意的压子 前端页面上的动态效果怎么做 异步加载js的方式有哪些 第二位面试官 为什么不从事大学专业相关的工作 做好前端需要学习那些方面的知识 数组方法 实习 第三位面试官 为什么不在学校所
-
 顺丰科技测开一面 9.13 22分半 (已二面)
顺丰科技测开一面 9.13 22分半 (已二面)听说写面经可以赞人品 自我介绍 为什么不找研究生学习的算法岗位 为什么不找开发岗位 为什么感觉测试比较适合你 有没有了解过测试岗位的一些要求 对边界值的理解 微信手机端的登录功能如何测试 你觉得测试人员应该具备哪些素质 说一个你遇到的困难,以及如何去克服的 为什么选择来顺丰?为什么不选择像字节、腾讯这些? 当时有点尴尬 如果来顺丰之后,跟你想象的不太一样,会怎么样呢? 职业规划是怎样的?会在测
-
 顺丰科技 测开 二面 9.17 28分钟(9.21终面)
顺丰科技 测开 二面 9.17 28分钟(9.21终面)自我介绍 没实习经验?我:嗯 为什么选测试而不去做算法? 对测试的了解有哪些? 场景题,抢票,把你的测试理论放进去。然后开始讨论(占大部分时间) 有没有遇到过什么挫折,怎么应对的?(一面问过) 假如你去了新公司,去了你自己不是特别喜欢的部门你会怎么办?(一面问过) 反问 总结:测试用例讨论的时候还是说的少了,面试官建议如果面测试的话可以再准备下。过不过心里没谱呀,感觉第一个问题没实习经验感觉他有点
-
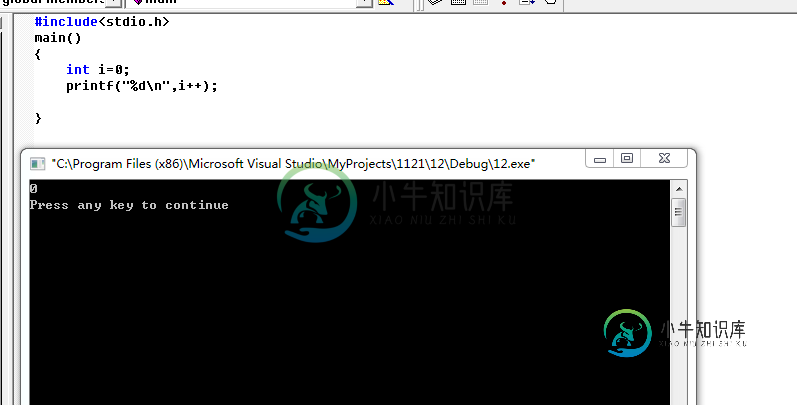 c语言++放在前面和后面的区别分析
c语言++放在前面和后面的区别分析本文向大家介绍c语言++放在前面和后面的区别分析,包括了c语言++放在前面和后面的区别分析的使用技巧和注意事项,需要的朋友参考一下 咱们先看第一个 i被赋值0,i++(后++)并没有输出1。 现在i被赋值0,++i,也就是前++后输出了1。 i被赋值0,前++ 的话,就是自身先加1 就自身赋值变成1 ,后面的i的值都是1了。 i被赋值0,先是后++,后++意思是 自己先被赋值,赋值
-
 深圳数马电子(C++)面经
深圳数马电子(C++)面经2022.8.31投递 9.3笔试 9.16技术面(15min) 10.9HR面(30min) 1、自我介绍 2、介绍项目? 3、内存分区? 4、delete和delete[]区别? 5、int[]一个数组应该用哪个(delete?delete[]?),如果选delete有什么后果? 6、原码、反码、补码? 7、自己是外向型还是内向型? 8、反问? HR面 1、为什么选择这个
-
 卓望数码java一面凉经
卓望数码java一面凉经面试官人挺好一直说没事。面试时间大概有30分钟左右,问的大部分都是八股文内容,但国庆假期一过都忘了 1. 介绍JVM线程私有、共有区域,垃圾回收,对象引用算法; 2. GC调优思路,如何查看JVM垃圾回收次数、内存大小? 2. java集合:ArrayList和LinkedList底层数据结构、效率对比、用途,ArrayList扩容机制; 3. 如何创建线程?Callable和Runnable的区
-
 卓望数码c++开发面经
卓望数码c++开发面经自我介绍 1.类里面默认的函数 2.构造函数能不能是虚函数,为什么 3.指针和引用区别 4.c++特性 5.继承和重写 6.select和echo 7.指针数组和数组指针的书写 8.二维数组按行遍历和按列遍历效率 9.多个人围成一圈 10.单链表中心节点 11.结构体和类的区别 12.数组越界没有占用其他内存空间对其他线程会不会有影响 13.内存泄漏后进程结束后对系统的危害
-
 兴业数金817 前端面经
兴业数金817 前端面经#面经# 等了好久突然被拉进会议室,没来得及开录音,记到啥写啥 先自我介绍 react-router怎么用的 == 和 === 区别 页面没出现数据,如何判断是前端还是后端问题(考开发者工具的使用 组件通信讲一下 学没学过vue(没有 要你学的话怎么学 ? 项目评价模块有什么功能?能回复评价内容么(没写这个功能 项目购物车怎么实现 关闭页面重开会恢复购物车状态么 反问
-
 华芯巨数 测试岗面经
华芯巨数 测试岗面经面试时长:1h 内容:python使用过的库,Python pil库的使用:图像处理库,元类创造的对象,白盒测试的覆盖方法:路径覆盖,测试理论:可靠性稳定性易用性,如何分析代码覆盖率,测试准则,代码规范与测试规范,性能测试的纬度与指标 智力题,站一排黑白两个色的帽子,从后往前看 算法题,找出最长不重复子字符串 面试官人还是挺好的,有不会的问题会给出引导,感觉水平很高 当然我自己菜,最终没过
-
 招联金融-数据岗-面经
招联金融-数据岗-面经笔试(10.11) 岗位是数据开发,一道编程,几十道选择。难度不大,但涉及面挺广。 一面(10.15) 笔试完,隔天约面,效率很高。 项目介绍,自己的分工 特征选择方法 数据挖掘中对于缺失值的处理方案 说一下Python(pandas)中常用的数据处理算子。 Spark的原理,分布式是怎么搭建的。 Sql中union和union all的区别 数据行转列怎么操作 xgboost和gbdt的区别 x
-
 苏小研 数据运营 面经
苏小研 数据运营 面经本来以为是偏运营 没想到是偏数据。感觉凉了 面试官迟到了三十分钟!!! 问了对数据运营的理解 数据分析项目深挖 sql 数据库知识 然后是你觉得自身的优势 两个面试官都很冷漠 对我不是很感兴趣😂
-
 叶子科技面经——大数据
叶子科技面经——大数据1、自我介绍 2、数据仓库为什么要分层,目的是什么 3、DWS层和DWT层是怎样划分的 4、PV和UV分别是什么 5、数据仓库建模的两种形式 6、范式建模中的第三范式的原则 7、维度建模中最常见的建模形式是什么区别是什么 8、如何评判数仓的优劣性 9、MR流程是写的MR程序,还是通过hql 10、用户留存率的计算公式 11、HDFS的写流程 12、MR的底层原理 13、MR
-
 佳都 大数据开发 面经
佳都 大数据开发 面经一面 1、自我介绍 2、先问实习内容,实习涉及了实时数仓,细问了一些点 3、再问项目内容,做的是离线数仓 4、离线数仓的数据源有哪些?是怎么收集这些数据的? 5、离线数仓是怎么分层的?分层依据是什么? 6、JVM的内存模型介绍一下 7、说一下你知道的垃圾回收算法 8、MySQL的存储引擎有哪些? 9、做过哪些HiveSQL优化?或者说你了解哪些优化措施? 10、怎么解决数据倾斜问题? 11、有接触
-
 字节数据科学12.27面经
字节数据科学12.27面经年龄:正态分布 性别:0-1变量 GMV:偏态分布 如何对对照组和实验组数据是否是否一致进行比较? 面试官答案: 年龄:正态检验,如果不想对均值和方差分别进行检验的话,就用ks检验 性别:比例检验,用卡方检验(列联表检验),或者转化成正态检验 GMV:偏态,方差不存在,不能用中心极限定理,所以不能用正态分布检验,所以用什么呢?