《数分面经》专题
-
将百分位数传递给pandas agg函数
问题内容: 我想通过numpy percentile()函数通过熊猫的agg()函数,就像我在下面对其他各种numpy统计函数所做的那样。 现在我有一个数据框,看起来像这样: 我的代码如下所示: 上面的代码有效,但我想做类似的事情 即指定各种百分位数从agg()返回 应该怎么做? 问题答案: 也许不是超级有效,但是一种方法是自己创建一个函数: 然后将其包含在您的: 请注意,虽然这是 应 该如何做的
-
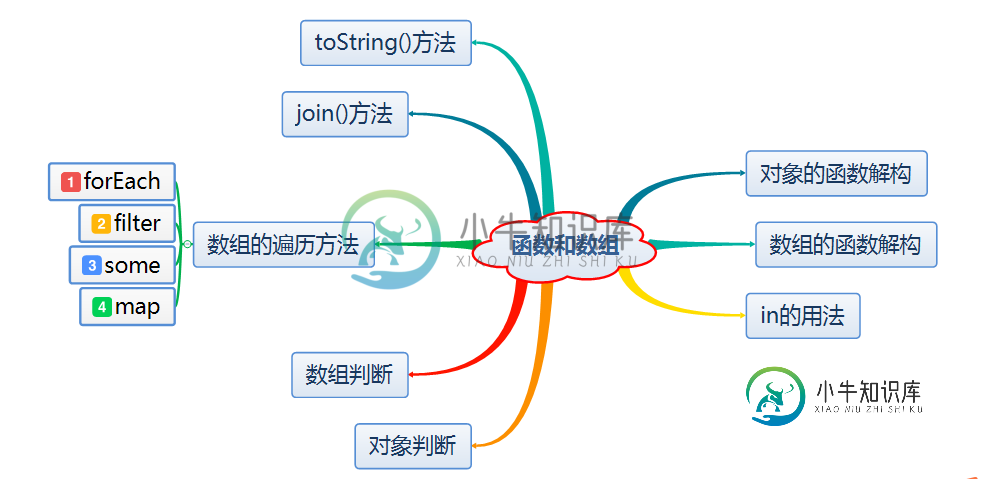 ES6函数和数组用法实例分析
ES6函数和数组用法实例分析本文向大家介绍ES6函数和数组用法实例分析,包括了ES6函数和数组用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了ES6函数和数组用法。分享给大家供大家参考,具体如下: 1.对象的函数解构 ES6为我们提供了这样的解构赋值使在前后端分离时,后端返回来JSON格式的数据,前端可以直接把这个JSON格式数据当作参数,传递到函数内部进行处理。比如: 结果为: 2.数组的函数解构 声
-
定点整数除法(“分数除法”)算法
霍尼韦尔DPS8计算机(和其他计算机)有一条“除分数”指令: “此指令将71位分数除数(包括符号)除以36位分数除数(包括符号),形成36位分数商(包括符号)和36位分数余数(包括符号)。余数的第35位对应于被除数的第70位。除非余数为零,否则余数符号等于被除数符号。” 据我所知,这是整数除法,小数点在左边。 (我确实在白天将整数数学进行了前移,但我对这些技术的记忆在时间的迷雾中消失了。) 要在D
-
CodeIgniter分页,在函数之间发送参数
我有一个问题与分页和codeigniter。我有一个快速搜索视图,我正在将信息提交给索引控制器函数,并在那里设置分页并调用快速搜索方法来获取我想要的数据。它就是不起作用。我花了5个多小时重写这些方法,甚至从快速搜索开始,然后传递到索引函数,但没有任何效果,请帮助。 快速搜索功能: sql是这样的: 显示了数据,但我看不到其中的页码。。甚至当我想更改url进行分段时,它也会说我没有任何数据。 该视图
-
ES分析器,它也标记数字,数字
问题内容: 我正在使用Elasticsearch内置的简单分析器https://www.elastic.co/guide/en/elasticsearch/reference/1.7/analysis- simple- analyzer.html ,其中使用了小写标记器。和文本 Apple 8 IS Awesome 以以下格式标记。 您可以清楚地看到,它缺少对数字进行标记的功能,因此,如果现在仅使
-
Spring数据可分页breaking Spring数据JPA OrderBy
我有一个简单的JpaRepository和一个finder,它返回按名为“number”的属性降序排列的记录。“number”属性也是我的实体的@Id。这很好,但是有数千条记录,所以我想返回一个页面而不是列表。 如果我将查找器更改为以下内容,则排序不再起作用。我尝试过使用可分页参数的排序功能,但不起作用。还删除了OrderByNumberDesc,但结果相同。 EDIT-添加控制器方法 以下是我的
-
Spring数据R2DBC如何查询分层数据
我是反应式编程的新手。我必须开发一个简单的Spring启动应用程序来返回一个json响应,其中包含公司及其所有子公司和员工的详细信息 创建了一个Spring Boot应用程序(Spring Webflow Spring data r2dbc) 使用以下数据库表来表示公司和子公司以及员工关系(这是一种与公司和子公司的层次关系,其中一个公司可以有N个子公司,而这些子公司中的每个子公司可以有另N个子公司
-
Kotlin函数参数:无法重新分配Val
-
对于复数,如何表示分叉函数
确实存在所谓的超操作序列。它的工作原理就像你构造乘法,加上许多重复次。然后是指数化,其中有许多的乘法重复次。然后,就有了四舍五入,表示为一个指数塔,就像,重复次。 我有兴趣如何写这个函数,对于浮点数和复数? 我已经用glsl编写了乘法和求幂函数: 但是我被卡住了!我们如何编写tetration函数,不仅针对浮点数,而且针对整个复平面本身?
-
在Swift中将数组拆分为子数组
给定一个值数组,我如何将它分成由相等元素组成的? 给定这个数组 我想要这个输出 解决这一问题的一种可能方法是创建某种索引,以指示每个元素的出现情况。 最后使用索引重建输出数组。 但是,使用此解决方案,我会丢失原始值。当然,在这种情况下,这不是一个大问题(一个值仍然存在,即使重新创建,),但我想将此解决方案应用于像这样更复杂的数据结构 实际上,我正在寻找的函数是与相反的函数 我希望我已经说清楚了,如
-
TfidfVectorizer如何计算测试数据的分数
在scikit learn中,我们可以拟合训练数据,然后使用相同的矢量器转换测试数据。列车数据转换的输出是一个矩阵,表示给定文档中每个单词的tf idf分数。 然而,安装的矢量器如何计算新输入的分数?我猜: 一个单词在一个新文档中的分数,通过将同一单词在训练集中的文档上的分数进行聚合计算得出 我曾经尝试过从Scikit学习的源代码中推断出这个操作,但不太明白。这是我之前提到的选择之一还是完全不同的
-
对数正态分布中的聚集参数
我想知道是否有可能从一个对数正态分布中得到一个聚合参数。在生态学中,通常使用负二项式中的聚集参数k,该参数度量数据中聚类或聚集或异质性的数量:越小的k意味着更多的异质性。负二项分布的方差为μ+μ2/k,当k变大时,方差接近均值,分布接近泊松分布。在R中,聚合参数称为size参数(Bolker,2008)。 当我在fitdistr中拟合我的数据时,我的数据比负二项式、gamma和Poisson更符合
-
 数据开发 - 面经 - 来未来(医疗大数据)
数据开发 - 面经 - 来未来(医疗大数据)2024.1.9 面试 Boss直聘沟通 公司要求驻场开发,接受加班,接受出差 你是25届是吧?能在六个月左右是吗?目前在校吗? 后续有什么规划? 你怎么理解数据开发这个岗位的? 讲讲简历上这两个项目?是你在学校做的是吧? 项目你是全程参与是吧? 聊天这个项目的数据源是哪里来的呀? 项目整体是落在HDFS上是吧? 单一架构,嗷,然后可视化,是哇? 下一个电商项目介绍一下? 数据来源讲讲? 那意思是
-
 华为集团IT数字化IT应用工程师一面二面面经
华为集团IT数字化IT应用工程师一面二面面经2022/8/23 9点一面 2022/8/25 11点二面 自我感觉两次面试面的都不咋样,但是居然过了(虽然主管面后面是池子) 面试问题大概如下: 自我介绍, 项目介绍,逮着项目一顿问; (由于项目与数据结构有关下面的问题数据结构偏多) 随便说三种底层数据结构的特点和差别; 介绍一下hash; 解决hash冲突除了开放地址法和开链法还有其他方法吗;(没答上来) hash的底层数据结构是如何设计
-
 双非跨专业cvte的一面-电商运营(面经及个人感受分享)
双非跨专业cvte的一面-电商运营(面经及个人感受分享)面试公司:cvte 面试岗位:电商运营 个人情况:双非本 跨专业 唯一亮点可能就是实习经历丰富(但没有电商相关实习经验) 面试感受:先分享面试感受好了,一面群面很简单,就是操作流程比较麻烦,约日期以及在公众号排队什么的有点费事,建议在指定的面试开始时间前就早早的排队进面。(我当时好像约的五六点的,但是早早的去排队了,然后两三点左右就开面了) 面试是群面,3(候选人)V1(面试官) 我那一场三位候选