《数据分析师》专题
-
c#预处理指令分析
本文向大家介绍c#预处理指令分析,包括了c#预处理指令分析的使用技巧和注意事项,需要的朋友参考一下 预处理指令 这些指令/命令不会转换为可执行代码,但会影响编译过程的各个方面;列如,可以让编译器不编译某一部分代码等。 C#中主要的预处理指令 #define和#undef #define指令定义: 它告诉编译器存在DEBUG这个符号;这个符号不是实际代码的一部分,而只是在编译器编译代码时候可能会根据
-
java时间 java.util.Calendar深入分析
本文向大家介绍java时间 java.util.Calendar深入分析,包括了java时间 java.util.Calendar深入分析的使用技巧和注意事项,需要的朋友参考一下 java.util.Calendar 在Java中时间的类有几个,但是随着Date被渐渐禁用,其中的方法慢慢打上了叉号,剩下能用的函数在Calendar中都已实现,而Calendar的子类GregorianCalenda
-
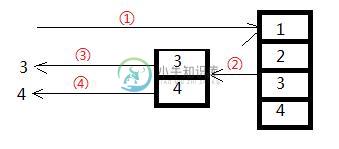 C#中yield return用法分析
C#中yield return用法分析本文向大家介绍C#中yield return用法分析,包括了C#中yield return用法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#中yield return用法,并且对比了使用yield return与不使用yield return的情况,以便读者更好的进行理解。具体如下: yield关键字用于遍历循环中,yield return用于返回IEnumerable<T>,y
-
Jackson的用法实例分析
本文向大家介绍Jackson的用法实例分析,包括了Jackson的用法实例分析的使用技巧和注意事项,需要的朋友参考一下 通俗的来说,Jackson是一个 Java 用来处理 JSON 格式数据的类库,其性能非常好。本文就来针对Jackson的用法做一个较为详细的实例分析。具体如下: 一、简介 Jackson具有比较高的序列化和反序列化效率,据测试,无论是哪种形式的转换,Jackson > Gson
-
 DevTools无法分析SourceMap:chrome扩展
DevTools无法分析SourceMap:chrome扩展一周前,我想,我开始在我的谷歌浏览器控制台上收到警告信息。 有没有办法摆脱这些警告?
-
使用antlr分析树深度
我有一个处理AND和OR表达式的antlr规则。看起来是这样的: 这将生成一个非常深的解析树。E、 g.如果你有 结果是这样的树: 这可能会变得非常深入和昂贵,所以我想添加一个优化。我想同时处理多个顺序AND表达式(类似于OR-s)。 所以我想这样做: 我认为这将为序列中的所有And-s生成一个节点。 然而,当我这样做的时候,antlr仍然选择生成递归树。我想那是因为规则是模棱两可的。有什么想法可
-
JAVA操作XML实例分析
本文向大家介绍JAVA操作XML实例分析,包括了JAVA操作XML实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JAVA操作XML的方法。分享给大家供大家参考。具体如下: java代码如下: XML文件如下: 希望本文所述对大家的java程序设计有所帮助。
-
CI框架Session.php源码分析
本文向大家介绍CI框架Session.php源码分析,包括了CI框架Session.php源码分析的使用技巧和注意事项,需要的朋友参考一下 CI的Session并不是原生的session,正是我前面所有的cookie based session,另外,CI可以根据用户选择配置是否将session存入数据库中,本人很喜欢这个功能,还有就是“闪出数据”的功能,既闪出数据只是对下次服务器请求可以,之后就
-
无法解析git push->分支
当我尝试向github推送一个新的远程分支时,我一直遇到同样的问题,我不知道如何处理它。事情就是这样: 我创建了一个分支,例如 对那个分支进行更改 提交这些更改 然后我签出到我的开发分支(如果由于这样或那样的原因我当时无法推送) 当我返回该分支我尝试推送 我收到消息: 要推送当前分支并将远程设置为上游,请使用 致命:功能/5110无法解析为分支。 我发现解决这个问题的唯一方法是删除我的分支,然后重
-
getJSON跨域SyntaxError问题分析
本文向大家介绍getJSON跨域SyntaxError问题分析,包括了getJSON跨域SyntaxError问题分析的使用技巧和注意事项,需要的朋友参考一下 昨天写一个功能:点击手机验证的同时获取json端的数据。 javascript代码如下: user.php代码如下: 相应如下: 问题出来了: 在火狐浏览器中: SyntaxError: missing ; before statement
-
 解析asp.net的分页控件
解析asp.net的分页控件本文向大家介绍解析asp.net的分页控件,包括了解析asp.net的分页控件的使用技巧和注意事项,需要的朋友参考一下 一、说明 AspNetPager.dll这个分页控件主要用于asp.net webform网站,现将整理代码如下 二、代码 1、首先在测试页面Default.aspx页面添加引用 <%@ Register Assembly="AspNetPager" Namespace="W
-
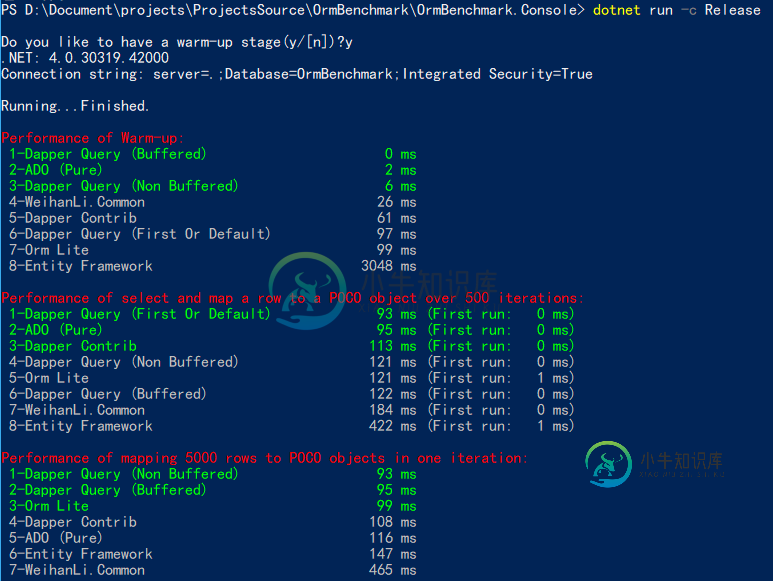 .NET Orm性能测试分析
.NET Orm性能测试分析本文向大家介绍.NET Orm性能测试分析,包括了.NET Orm性能测试分析的使用技巧和注意事项,需要的朋友参考一下 简介 OrmBenchmark 这个项目主要是为了测试主要的Orm对于 SqlServer 数据库的查询并将数据转换成所需 POCO 对象的耗时情况(好吧,实际上不完全orm,更像是SqlMapper ...) 测试结果: .NetFramework 4.6 有预热 .NetFr
-
LocalDate-解析区分大小写
我想知道,如果从年初到某个日期过去的天数是奇数。我尝试使用LocalDate从我的字符串()中解析日期,但我得到错误:
-
“索引”:elasticsearch中的“未分析”
我用cmd删除了映射 在我的配置文件中,我定义了如下索引:, 并尝试创建一个新的映射,但我得到了错误 {“error”:{“root_cause”:[{“type”:“index_not_found_exception”,“reason”:“no-this index”,“resource.type”:“index_or_alias”,“resource.id”:“logstash_log*”,“
-
模板分析期间出错
代码顺序 IndexController 订单控制器 订单生成器 订单服务 html 错误 模板解析时出错(模板:"类路径资源[模板/订单/list.html]") 评估SpringEL表达式的异常:“order.id”(模板:“订单/列表”-第19行,第9栏) EL1008E:在“reactor.core.publisher”类型的对象上找不到属性或字段“id”。FluxOnAssembly’-