《数据分析师》专题
-
Seata config 模块源码分析
一 . 导读 根据大佬定义的分类,配置可以有三种:环境配置、描述配置、扩展配置。 环境配置:像一些组件启动时的参数等,通常是离散的简单值,多是 key-value 型数据。 描述配置:与业务逻辑相关,比如:事务发起方和参与方,通常会嵌到业务的生命周期管理中。描述配置信息较多,甚至有层次关系。 扩展配置:产品需要发现第三方实现,对配置的聚合要求比较高,比如:各种配置中心和注册中心,通常做法是在 ja
-
MOSN 源码分析 - 连接池
本文的内容基于 MOSN v0.10.0。 在连接管理中我们主要介绍 MOSN 实现连接池的功能,连接池是上下游 MOSN 之间进行长连接复用以提高转发效率与降低时延的关键,MOSN 连接池提供基于 HTTP1, HTTP2, SOFARPC, XProtocol 协议的连接池。 而“健康检查”是一种实时检测上游服务器是否正确提供服务的机制,一般分为“主动健康检查”和“被动健康检查”。主动健康检查
-
1.2.2 分析云能做什么
1. 赋能各业务角色提升工作效能 百度统计分析云能够全面提升客户各职能角色工作效能,助力达成用户全生命周期增长 支持产品进行功能评估提升转化率 产品角色作为产品规划者,重点关注产品的流程设置和功能设计是否给予用户良好的使用体验,并确保用户充分体验产品的核心价值。 支持运营进行用户分群实现精准营销 运营角色重点关注用户构成现状及变化,并从用户行为角度剖析用户的活跃程度、流失情况。针对不同用户
-
GPERF 内存和性能分析
valgrind一个很好用的内存和CPU分析工具,srs由于使用了st(state-threads),st是基于c函数setjmp和longjmp,valgrind不支持这两个函数,所以srs没法用valgrind分析内存错误和泄漏。 gperf是google用作内存和CPU分析的工具,基于tcmalloc(也是google内存分配库,替换glibc的malloc和free)。好消息是gperf可
-
源码分析之总结篇
Memcached源码分析共8篇文章,前7篇文章主要分析每个模块的c源代码。这一篇文章主要是将之前的流程串起来,总结和回顾。同时通过这篇文章可以全局去看Memcached的结构。 一、Memcache的网络模型 Memcached主要是基于Libevent 网络事件库进行开发的。 Memcached的网络模型分为两部分:主线程和工作线程。主线程主要用来接收客户端的连接信息;工作线程主要用来接管客户
-
6. 试验运行和分析
试验运行和分析 将前期配置工作都完成之后,您就可以按照该文档正式开始运行试验了。在此期间,您可以随时调整流量分配,并实时查看数据,监控不同版本的数据表现,分析判断试验结果。
-
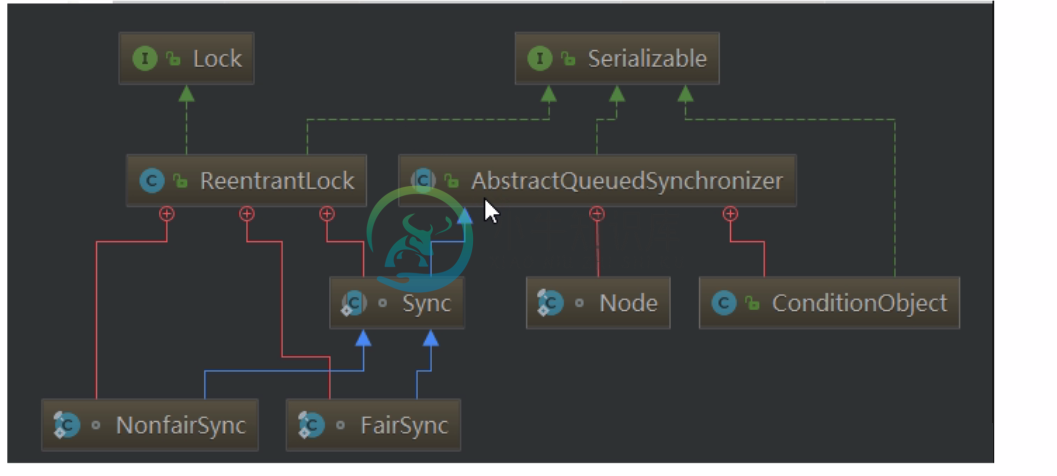 AQS之共享锁分析 (三)
AQS之共享锁分析 (三)主要内容:文章目录,1.AQS 内部体系架构,2.获取资源,3.释放资源,4.其他获取资源1.AQS 内部体系架构 FairSync: 公平锁 NoFairSync: 非公平锁 Shared: 共享模式 Exclusive: 排他模式 2.获取资源 尝试获取共享资源, 返回值为整数, 负数为失败, 0为成功, 但是其他线程无法再成功, 正数为成功, 其他线程也可以成功。 由于共享锁允许多个线程同时获取成功,因此可以用 返回值代表还能有几个线程可以继续获取资源,但并不是强制性的。 2.1
-
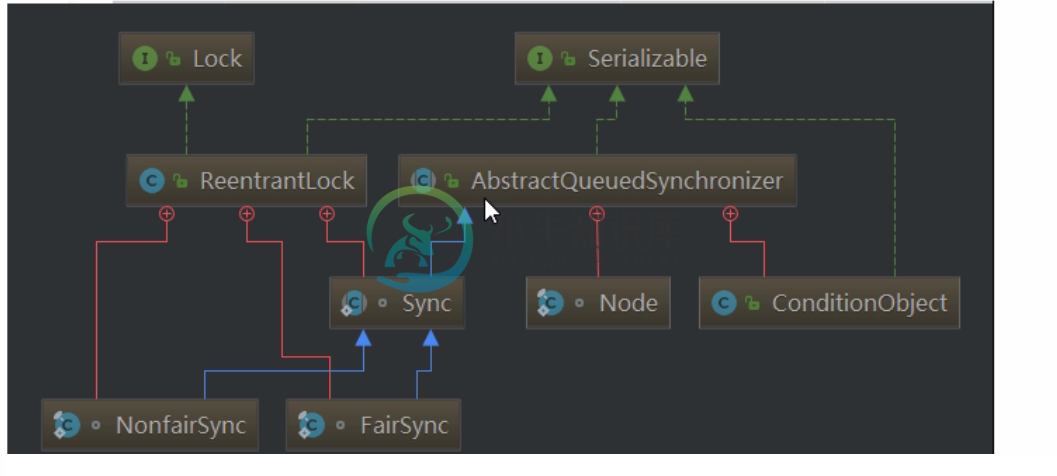 AQS之排斥锁分析 (二)
AQS之排斥锁分析 (二)主要内容:1.AQS 内部体系架构,2.获取资源,3.释放资源,4.获取&释放资源总流程,5.其他获取资源的方法1.AQS 内部体系架构 FairSync: 公平锁 NoFairSync: 非公平锁 Shared: 共享模式 Exclusive: 排他模式 2.获取资源 AbstractQueueSynchronized.acquire() 尝试获取资源,成功则结束 获取资源失败,新建节点插入队列 在队列里排队并获取资源 如果等待过程中出现线程中断,则中断自身 (1) 首先就是一次资源获取的尝试
-
InnoDB的内存结构分析
主要内容:一、基本的数据结构,二、Buffer Pool,三、Change Buffer,四、ADaptive Hash Index,五、Log Buffer,六、总结一、基本的数据结构 在InnoDB中,数据的分配和存储也有自己的数据结构,在前面分析过MySql中的内存管理,但是内存管理是有一个不断抽象的过程。在InnoDB中还会有一层自己的内存管理。在InnoDB引擎中的内存结构主要有四大类: 1、Buffer Pool 在MySql中,数据都是存储在磁盘中的,也就是说,从理论上讲,每次做S
-
Golang 如何分析一个类
一般名词都是类(名词提炼法) 飞机发射两颗炮弹摧毁了8辆装甲车 飞机 炮弹 装甲车 隔壁老王在公车上牵着一条叼着热狗的草泥马 老王 热狗 草泥马
-
 快手 二面 项目分析
快手 二面 项目分析1.简单说了一下我的前后端项目。 答:微信小程序,发帖、查课表、查成绩、下载试卷PDF。 2.说说全文索引,测试过用like做模糊查询在某个数据量下的效率吗? 答:我说测试过100w数据量下,查询一条数据要二三十秒,面试官觉得不应该会这么久。 3.面试官建议学学es解决模糊查询问题。 4.JWT技术,token放在哪?token放在浏览器的哪个位置? 5.解释session和cookie? 6.有
-
 pandas数据分组groupby()和统计函数agg()的使用
pandas数据分组groupby()和统计函数agg()的使用本文向大家介绍pandas数据分组groupby()和统计函数agg()的使用,包括了pandas数据分组groupby()和统计函数agg()的使用的使用技巧和注意事项,需要的朋友参考一下 数据分组 使用 groupby() 方法进行分组 group.size()查看分组后每组的数量 group.groups 查看分组情况 group.get_group('名字') 根据分组后的名字选择分组数据
-
计算数据框列中每个值的百分位数
问题内容: 我正在尝试从DataFrame计算列中每个值的百分位数。 有没有更好的方法来编写以下代码? 我希望看到更好的性能。 问题答案: 似乎您想要: 性能:
-
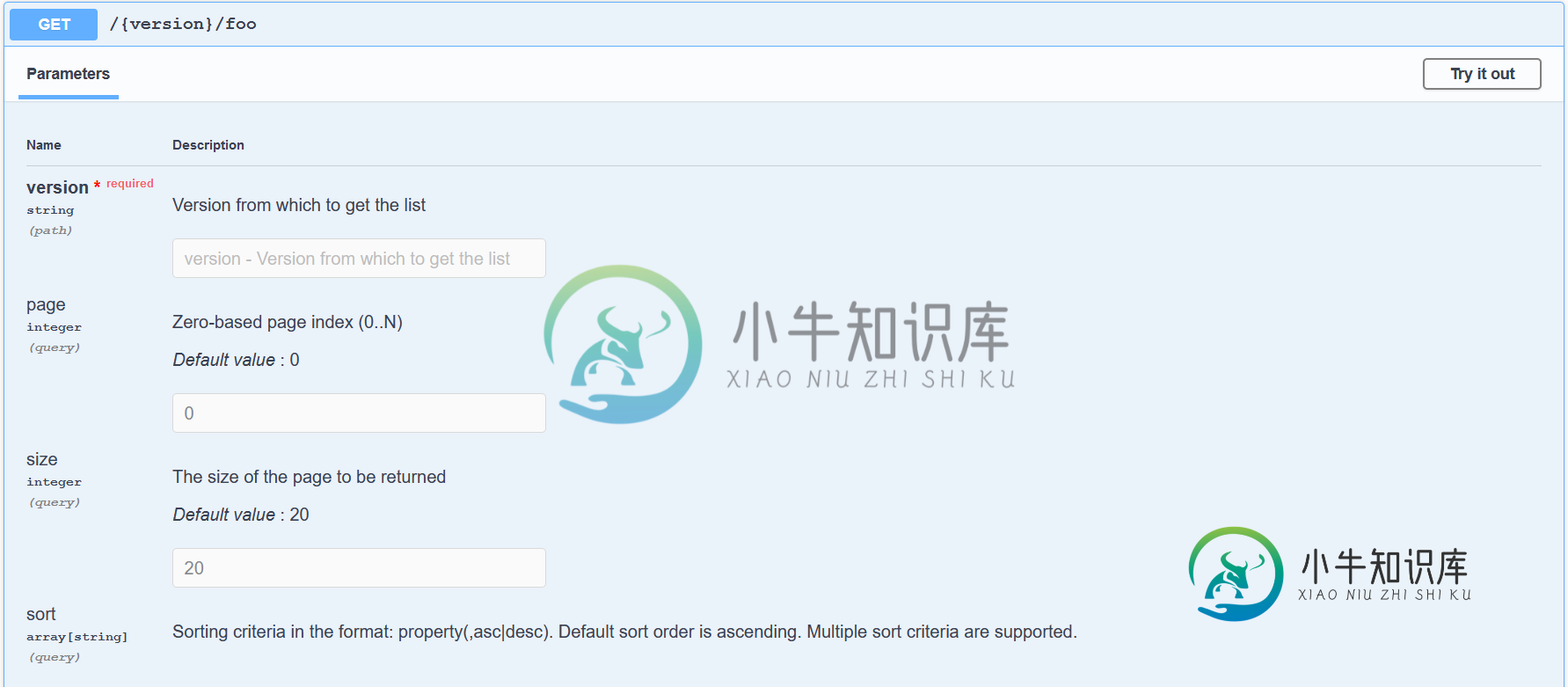 Springdoc数据REST忽略覆盖可分页参数名称
Springdoc数据REST忽略覆盖可分页参数名称在我的申请中。属性,我已覆盖可分页参数的名称: 但是当我去Swagger UI检查我的Swagger留档时,没有使用新的name参数: 这是我的职能部门的签名: 如何将新名称绑定到文档?我可以更改默认描述吗? 谢谢你的回答!
-
 中信银行 大数据中心 数分 一面面经
中信银行 大数据中心 数分 一面面经背景:双211,研究方向:计算机视觉(遥感变化检测) 一志愿:AI算法(应该是挂了一志愿) 二志愿:数分 10.26上午 腾讯会议视频面试 1个hr/3个面试官 1.自我介绍 2.有没有实习? 3.介绍一个项目所做的工作 4.技术栈:会什么编程语言,数据处理都是自己用python写的方法吗?有没有使用过什么大型数据处理软件或许使用过哪些python数据分析库 ? 5.了不了解结构化数据,大数据?(