《数据分析师》专题
-
Oracle开发之分析函数(Top/Bottom N、First/Last、NTile)
本文向大家介绍Oracle开发之分析函数(Top/Bottom N、First/Last、NTile),包括了Oracle开发之分析函数(Top/Bottom N、First/Last、NTile)的使用技巧和注意事项,需要的朋友参考一下 一、带空值的排列: 在前面《Oracle开发之分析函数(Rank、Dense_rank、row_number)》一文中,我们已经知道了如何为一批记录进行全排列、
-
JavaScript支持的最大递归调用次数分析
本文向大家介绍JavaScript支持的最大递归调用次数分析,包括了JavaScript支持的最大递归调用次数分析的使用技巧和注意事项,需要的朋友参考一下 你对JavaScript引擎能进行多少次递归调用好奇吗? 多少次递归调用 下面的函数可以让你找到答案: (灵感来自Ben Alman的 gist) 三个结果: 这些数字代表什么?Aleph先生指出,在V8中,递归调用的数量取决于两个量:堆栈的大
-
js中数组排序sort方法的原理分析
本文向大家介绍js中数组排序sort方法的原理分析,包括了js中数组排序sort方法的原理分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了js中数组排序sort方法的原理。分享给大家供大家参考。具体分析如下: 最近在百度的项目中要用到对数组进行排序,当然一开始自然想到了数组的sort方法,这方法应用非常简单,大致如下: 但是我突然想到,sort用法为什么这么简单,其原理到底是什么呢?于
-
 Keras自定义损失函数-截尾生存分析
Keras自定义损失函数-截尾生存分析我试图在Keras中构造一个自定义损失函数-这是用于生存分析中的删失数据。 这种损失函数本质上是二元交叉熵,即多标签分类,但是损失函数中的求和项需要根据Y_true标签的可用性而变化。见下面的例子: 示例1:Y_可用的所有标签均为True Y_true=[0,0,0,1,1] Y_pred=[0.1,0.2,0.2,0.8,0.7] 损失=-1/5(log(0.9)log(0.8)log(0.8)
-
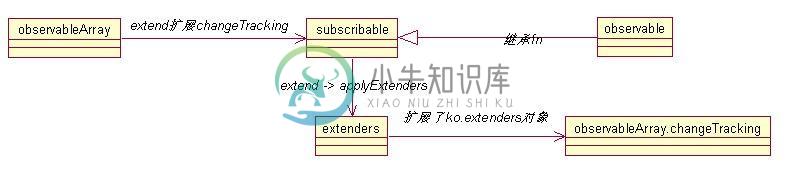 深入浅析knockout源码分析之订阅
深入浅析knockout源码分析之订阅本文向大家介绍深入浅析knockout源码分析之订阅,包括了深入浅析knockout源码分析之订阅的使用技巧和注意事项,需要的朋友参考一下 Knockout.js是什么? Knockout是一款很优秀的JavaScript库,它可以帮助你仅使用一个清晰整洁的底层数据模型(data model)即可创建一个富文本且具有良好的显示和编辑功能的用户界面。任何时候你的局部UI内容需要自动更新(比如:依赖于
-
 Docker镜像分析工具dive原理解析
Docker镜像分析工具dive原理解析本文向大家介绍Docker镜像分析工具dive原理解析,包括了Docker镜像分析工具dive原理解析的使用技巧和注意事项,需要的朋友参考一下 今天推荐一个这样的开源工具,用于探索 Docker 镜像,各层内容以及发现缩小 Docker/OCI 镜像大小的方法。这个工具就是:dive。 工具地址:https://github.com/wagoodman/dive,Star 数:22k+。 这个工具
-
 ATL 失效分析工程师(已oc)
ATL 失效分析工程师(已oc)09.04 投递 09.07 一面(hr面) 常见的HR面问题(一共15min) 自我介绍,公司了解,行业期待,职位看法这些东西吧 09.13 二面(专业面试) 讲了讲项目 讲了讲方法。反问了一下他们是怎么做失效的(感觉atl没弄懂什么叫失效分析) (面试过的里面相对简单的,差不多20min?) 09.17 测评(无聊) 证明你是一个正常人系列 09.19 谈薪 坐标厦门 base 9750 听到
-
无法将JSONObject转换为com。作语法分析分析地质点
我正在使用以下命令在JsonObject中保存geopoint: 在此之后,我将发送这个Jsonobject来解析云。 现在我试着用这个把它拿回来: 首先在线路上: 我得到了类型不匹配的错误。当我将其输入到parse对象中时,它运行良好;但是,当我尝试运行apk时,出现了以下错误:
-
使用频率分析/密码分析技术破译密码文本
本网站(https://www.guballa.de/substitution-solver)他做到了。 我必须通过频率分析来做到这一点(https://en.wikipedia.org/wiki/Frequency_analysis) 我面临的主要问题是,当我替换时,检查单词是否看起来像英语单词。 请指导我如何处理这个问题 谢谢哈基德
-
第10章 OpenCL的分析和调试 - 10.5 使用CodeXL分析内核
分析模式下,CodeXL可以当做静态分析工具使用。AMD显卡上,分析模式可以用来编译、分析和反汇编一个OpenCL内核。分析模式可选择界面方式和命令行方式。在这之后我们就称CodeXL为“内核分析器”。内核分析器也可以通过命令行使用,在CodeXL安装目录下,有一个CodeXLAnalyzer.exe,可以直接在命令行中执行。 内核分析器是一个离线编译器,还是一个分析工具。其能将内核源码编译成任意
-
如何根据数据帧的NAN百分比删除列?
问题内容: 对于的某些列,如果该列的80%是。 删除此类列的最简单代码是什么? 问题答案: 您可以使用与用于treshold,然后删除列用(因为删除列),还需要反转的条件-这样的手段删除所有列: 样品: 如果要通过最小值与参数一起很好地删除列,并且要删除列: 编辑:对于非布尔数据 列中的NaN条目总数必须少于条目总数的80%:
-
根据分区列从数据库增量表中删除
我有一个具有5个分区的delta表,其中一个分区是runid列。当我尝试使用runid删除时,使用真空命令后,底层拼花文件会被删除。但这不会删除runid分区。如果我运行相同的真空命令4次,那么它会删除runid分区。 对于配置单元,我们有删除分区,但这不适用于增量表! 这就是删除在增量表中的工作方式吗?或者有没有更好的方法从托管增量表中删除runid的数据和分区?
-
Spring部分更新对象数据绑定
问题内容: 我们正在尝试在Spring 3.2中实现特殊的部分更新功能。我们使用Spring作为后端,并且有一个简单的Javascript前端。我无法找到满足我们要求的简单解决方案,即 update()函数应采用任意数量的field:values并相应地更新持久性模型。 我们对所有字段进行了内联编辑,因此,当用户编辑字段并进行确认时,会将id和修改后的字段作为json传递给控制器。控制器应该能
-
Datagramsocket:receive(…)如何处理数据包的分段
问题内容: 我从我的教授那里得知,使用UDP套接字发送的数据报包在较低层中被分段,并且 可能 以多个包的形式到达接收器端。例如,如果我以数据报包的形式发送1000字节的数据,则在接收端 可能会 到达2字节,500字节,12字节,依此类推。因此,他建议执行多次receive(…)以接收发送方发送的整个1000字节数据包。 稍后,当我浏览Java文档中有关数据报套接字的receive(…)时,一行的内
-
Java操作MongoDB数据库示例分享
本文向大家介绍Java操作MongoDB数据库示例分享,包括了Java操作MongoDB数据库示例分享的使用技巧和注意事项,需要的朋友参考一下 MongoDB是一个文档型数据库,是NOSQL家族中最重要的成员之一,以下代码封装了MongoDB的基本操作。 MongoDBConfig.java MongoService.java MongoServiceImpl.java