《数据分析师》专题
-
19.5. 分析空间信息
19.5.1. Geometry格式转换函数 19.5.2. Geometry函数 19.5.3. 从已有Geometry创建新Geometry的函数 19.5.4. 测试几何对象间空间关系的函数 19.5.5. 关于几何最小边界矩形(MBR)的关系 19.5.6. 测试几何类之间空间关系的函数用值填充了空间列后,即可查询和分析它们。MySQL提供了一组在空间数据上执行各种操作的函数。根据它们所执
-
分析和管理网络
ANALYZING AND MANAGING NETWORKS 了解网络对任何一个有追求的黑客都是至关重要的。在许多情况下,你将通过网络攻击某些东西,而优秀的黑客需要知道怎样去和目标网络连接和交互。例如,您可能需要连接到视图中隐藏了 Internet 协议(IP)地址的计算机,或者你可能需要将目标的域名系统(DNS)查询重定向到您的系统,这些任务都相对比较简单,但是都需要一点 Linux 网络知识
-
HashMap-和-ConcurrentHashMap-源码分析
1.1 构造器 initialCapacity:初始容量,HashMap 在创建时桶的数量。 loadFactor:加载因子,HashMap 在容量自动增加前可以达到多满的尺度。 当 size 达到当前 Capacity 乘以加载因子时,resize 方法被调用。 // 给 initialCapacity、loadFactor、threshold 赋值。 public HashMap(int in
-
语法和语义分析
顾名思义,一个命令式语言是由一个个“命令”为单元组成,不过一般很少用命令这个词,而是细分一下,比较低级的语言用指令(instruction),高低的语言一般认为是一个语句(statement,以后简称stmt),词法分析只将一段高级语言代码分解成一个个词,接下来还要做语句层面的分析,最终目标是生成抽象语法树(ast) 代码: a = 1; s = 0; while (a <= 100)
-
链接分析(已下线)
链接分析(该工具已下线) 什么是内链死链、链出死链、链入死链 假设您的网站是www.abc.com,第三方网站是www.example.com。 内链死链:在您网站上发现同一个域名内的死链,即:如果在http://www.abc.com/1.html上发现了一条死链http://www.abc.com/2.html,那么我们称http://www.abc.com/2.html为内链死链;
-
启动查询分析器
“查询分析器”工具为查询日志提供图形表示,使你能够监控和优化查询性能,可视化查询活动统计数据,分析 SQL 语句,快速识别和解决长时间运行的查询。若要开始使用查询分析器,请在左侧窗格中选择要分析的实例,分析会立即开始。分析完成后,结果会显示出来: Navicat Monitor 每 60 秒刷新查询分析器中的指标。若要停止或开始刷新指标,请点击 或 图标。服务器数据收集在停止期间不会停止。 最新的
-
profile and pstats — 性能分析
yunx Profiler # profile_fibonacci_raw.py import profile def fib(n): # from literateprograms.org # http://bit.ly/hlOQ5m if n == 0: return 0 elif n == 1: return 1 e
-
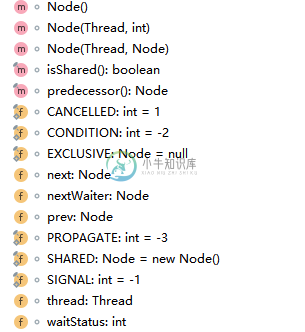 AQS之基础分析 (一)
AQS之基础分析 (一)主要内容:1.简介,2.内部类Node,3.AbstractQueuedSynchronizer,4.AQS 内部体系架构,5.AQS 子类1.简介 抽象队列同步器,是一系列同步实现的模板类,如锁Lock,信号量Semaphore,倒排计数器CoundDownLatch等都是基于AQS实现的,同时还提供了Condition对象,其await和sign、signAll对象可以用于代替Object的wait和notofy、notifyAll方法。 CLH队列是是一种先进先出FIFO的双向队列,AQS
-
InnoDB引擎启动分析
主要内容:一、InnoDB启动,二、源码分析,三、总结一、InnoDB启动 在MySql中,InnoDB的启动流程其实是很重要的。一些更细节的问题,就藏在了这其中。在前面分析过整个数据库启动的流程,本篇就具体分析一下InnoDB引擎启动所做的各种动作。在这期间,分析一下对数据库索引的处理过程。在前面的分析中已经探讨过,今天重点分析一下数据引擎的启动和加载流程。 在MySql中,方向是朝着插件化发展,所以InnoDB本身也是做为一个插件进行引用的。通过
-
9.2 网络通信分析
在网络流量工具Charles的安装和用法和6.1 分析HTTP/HTTPS网络流量 这两节,我们介绍了对iOS的网络通信进行分析的方法。 利用文章介绍的方法,可以发现有以下几类: 发送明文密码 有的应用一点也不注意用户数据的安全,竟然发送明文密码。读者可以拿自己常用的App试试,应该能发现这种App,我发现我常用的一个电影相关App竟然用HTTP直接发送用户的明文密码。 发送密码的md5 有的应用
-
Apache日志分析程序
这是一个我(站长)多年以前用 VC++ 写的用来简单分析 Apache 日志文件的工具,下载地址中包含整个项目的源码打包,可以直接用VC 打开并编译。
-
后端 - mongodb查询分析?
场景:有一个关于分类记录collection,分类name(string,中文,英文,数字等组成)字段上有索引方便快速筛选某个分类记录,现在查询出来需要排序,查询条件{name:"F1"},排序条件{_id:-1} mongodb查询explain分析,这是winningPlan SORT + FETCH + IXSCAN 这算不算bad查询,通常是FETCH + IXSCAN。
-
Spark Scala:使用分析函数获取累积和(运行总数)
我正在使用窗口函数实现火花中的累积总和。但是在应用窗口分区函数时记录输入的顺序没有保持 输入数据: 预期产出: 我试过下面的逻辑 对于dept_no=10,记录是按预期顺序计算的,而对于dept_no=30,记录不是按输入顺序计算的。
-
使用scikit-learn在朴素贝叶斯分类器中混合分类数据和连续数据
问题内容: 我正在Python中使用scikit-learn开发分类算法,以预测某些客户的性别。除其他外,我想使用Naive Bayes分类器,但是我的问题是我混合使用了分类数据(例如:“在线注册”,“接受电子邮件通知”等)和连续数据(例如:“年龄”,“长度”成员资格”等)。我以前没有使用过scikit,但我想高斯朴素贝叶斯适用于连续数据,而伯努利朴素贝叶斯可以用于分类数据。但是,由于我想在模型中
-
C#二分查找算法实例分析
本文向大家介绍C#二分查找算法实例分析,包括了C#二分查找算法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#二分查找算法。分享给大家供大家参考。具体实现方法如下: 希望本文所述对大家的C#程序设计有所帮助。