《数据分析师》专题
-
全面分析c# LINQ
本文向大家介绍全面分析c# LINQ,包括了全面分析c# LINQ的使用技巧和注意事项,需要的朋友参考一下 大家好,这是 [C#.NET 拾遗补漏] 系列的第 08 篇文章,今天讲 C# 强大的 LINQ 查询。LINQ 是我最喜欢的 C# 语言特性之一。 LINQ 是 Language INtegrated Query 单词的首字母缩写,翻译过来是语言集成查询。它为查询跨各种数据源和格式的数据提
-
Elasticsearch定制分析器
问题内容: 是否可以创建可按空间拆分索引然后创建两个令牌的自定义elasticsearch分析器?一是空间前的一切,二是空间。例如:我存储的记录字段包含以下文本:“ 35 G”。现在,我想通过仅在该字段中键入“ 35”或“ 35 G”查询来接收该记录。因此,Elastic应该创建两个令牌:[‘35’,‘35 G’],并且不再更多。 如果可能,如何实现? 问题答案: 可使用tokenizer实现。
-
Elasticsearch中的分析器
问题内容: 我在理解带轮胎宝石的elasticsearch中分析仪的概念时遇到了麻烦。我实际上是这些搜索概念的新手。这里有人可以帮我提供一些参考文章还是解释一下分析仪的实际作用以及为什么要使用它们? 我看到在Elasticsearch中提到了不同的分析器,例如关键字,标准,简单,滚雪球。没有分析仪的知识,我无法确定真正适合我的需求。 问题答案: 我给你一个简短的答案。 在索引时间和搜索时间使用分析
-
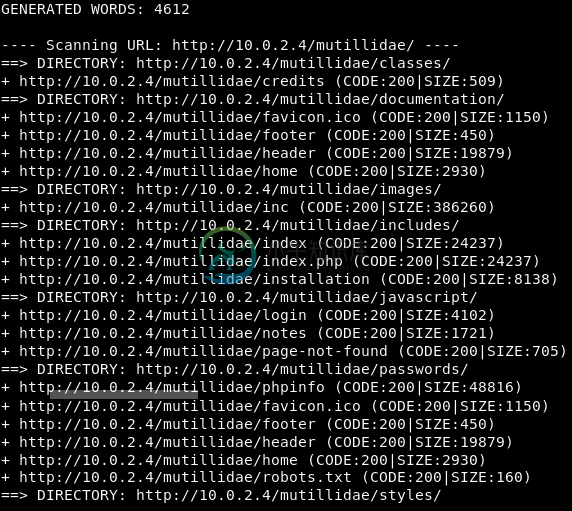 分析发现文件
分析发现文件在下面的屏幕截图中,可以看到dirb工具能够找到许多文件的结果。下面是我们已经知道的一些文件: 在下面的屏幕截图中,我们可以看到只是一个图标文件。是我们经常看到的索引。页脚和标题可能只是样式文件。可以看到有一个登录页面。 现在,我们可以通过利用一个非常复杂的漏洞找到目标的用户名和密码。但我们最终无法登录,因为无法找到登录的位置(页面)。在这种情况下,像这样的工具会很有用。我们查看文件通常非常有用,
-
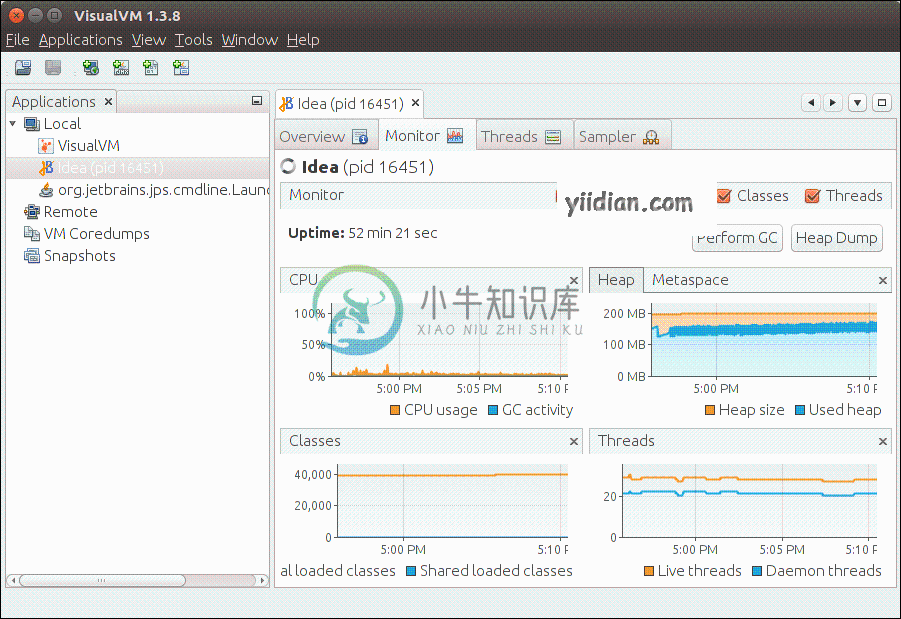 Intellij Idea Profiler分析器
Intellij Idea Profiler分析器主要内容:什么是 VisualVM?,配置,监控应用,螺纹测量,抽样申请,CPU采样,内存采样,内存泄漏Profiler 提供了有关我们应用程序性能的准确信息。它通过我们的应用程序测量 CPU、内存和堆使用的性能。它还为我们提供了有关应用程序线程的详细信息。VisualVM 工具用于测量 Java 应用程序分析。 什么是 VisualVM? 它是一个可视化工具,已与 JDK 以及 Java 6 或更高版本捆绑在一起。它适合初学者,并提供有关我们应用程序性能的详细信息。 配置 在 Windows
-
 Java HashMap原理分析
Java HashMap原理分析主要内容:1 什么是哈希(散列)(Hashing),2 HashMap hashCode()方法,3 HashMap equals()方法,4 HashMap 存储桶,5 HashMap的索引计算过程,6 HashMap get()方法,7 HashMap原理分析完整代码本文主要介绍HashMap工作原理,了解哈希算法的计算过程。 1 什么是哈希(散列)(Hashing) 哈希是通过使用方法hashCode() 将对象转换为整数形式的过程。必须正确编写hashCode() 方法,以提高HashM
-
7.21.Dijkstra 算法分析
最后,让我们看看 Dijkstra 算法的运行时间。我们首先注意到,构建优先级队列需要 $$O(V)$$ 时间,因为我们最初将图中的每个顶点添加到优先级队列。 一旦构造了队列,则对于每个顶点执行一次 while 循环,因为顶点都在开始处添加,并且在那之后才被移除。 在该循环中每次调用 delMin,需要 $$O(logV)$$时间。 将该部分循环和对 delMin 的调用取为 $$O(Vlog(V
-
6.14.查找树分析
随着二叉搜索树的实现完成,我们将对已经实现的方法进行快速分析。让我们先来看看 put 方法。其性能的限制因素是二叉树的高度。从词汇部分回忆一下树的高度是根和最深叶节点之间的边的数量。高度是限制因素,因为当我们寻找合适的位置将一个节点插入到树中时,我们需要在树的每个级别最多进行一次比较。 二叉树的高度可能是多少?这个问题的答案取决于如何将键添加到树。如果按照随机顺序添加键,树的高度将在 $$log2
-
代码静态分析
代码静态分析可以在不运行代码的情况下,提前检测代码。 主要可以做两点 语法检测 编码规范检测 作为开发人员,在日常编码中,难免会范一些低级错误,比如少个括号,少个逗号,使用了未定义变量等等,我们往往会使用编辑器的 lint 插件来检测此类错误。 对于我们 OpenResty 开发中,日常开发的都是 Lua 代码,所以我们可以使用 luacheck 这款静态代码检测工具来帮助我们检查,比较好的一点是
-
1.7.2 分析云下载
在事件分析报告中,可对已生成的报告进行导出,导出按钮位置如图。 每日导出次数根据版本不同有所限制,剩余次数会在导出确认框中进行提示。 开通全量导出的用户,可在导出时选择是否全量导出。 导出后的报告,可在管理-分析云设置-分析云下载中进行下载,下载次数无限制。
-
算法 - 算法分析
数学模型 1. 近似 2. 增长数量级 3. 内循环 4. 成本模型 注意事项 1. 大常数 2. 缓存 3. 对最坏情况下的性能的保证 4. 随机化算法 5. 均摊分析 ThreeSum 1. ThreeSumSlow 2. ThreeSumBinarySearch 3. ThreeSumTwoPointer 倍率实验 数学模型 1. 近似 N3/6-N2/2+N/3 ~ N3/6。使用 ~f(
-
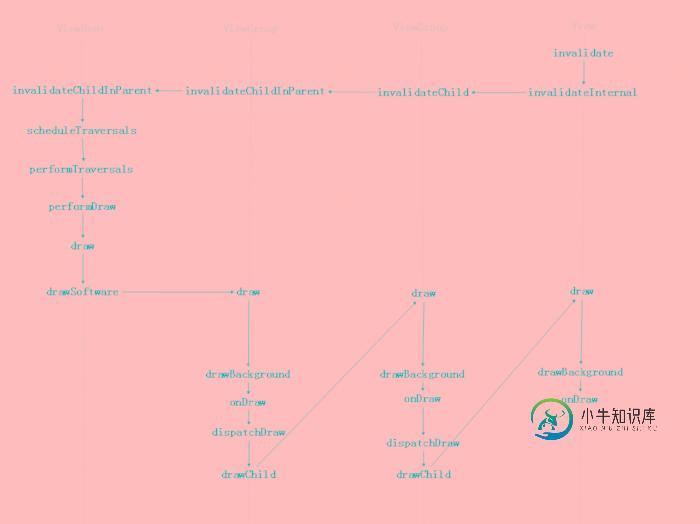 浅谈Android invalidate 分析
浅谈Android invalidate 分析本文向大家介绍浅谈Android invalidate 分析,包括了浅谈Android invalidate 分析的使用技巧和注意事项,需要的朋友参考一下 1. invalidate 和 postInvalidate 的关系 postInvalidate 是通过 Handler 切换回到主线程,然后在调用 invalidate 的,源码: 2. 子线程是否可以更新 UI ? 可以的,在 Activ
-
Python多进程分析
问题内容: 我正在努力弄清楚如何分析一个简单的多进程python脚本 我正在启动5个进程,因此cProfile会生成5个不同的文件。在每个方法的内部,我想看到我的方法’worker’大约需要3秒钟才能运行,但是相反,我只看到了’start’方法中正在发生的事情。 如果有人可以向我解释这一点,我将不胜感激。 更新:基于公认答案的工作示例: 问题答案: 您正在对流程启动进行概要分析,这就是为什么您只看
-
Android LayoutInflater.inflate源码分析
本文向大家介绍Android LayoutInflater.inflate源码分析,包括了Android LayoutInflater.inflate源码分析的使用技巧和注意事项,需要的朋友参考一下 LayoutInflater.inflate源码详解 LayoutInflater的inflate方法相信大家都不陌生,在Fragment的onCreateView中或者在BaseAdapter的
-
分析字符串antlr
我将字符串作为解析器规则而不是词法分析器,因为字符串可能包含带有表达式的转义,例如。 这不起作用,因为