《数据分析师》专题
-
交易分析
一、交易分析 点击进入交易分析页:该页主要展示的是交易分析、下单数量、订单来源(包含所有订单)、订单类型(包含所有订单)。 1、交易分析:展示的是订单金额(所有的订单总金额)和毛利润(售出商品的纯利润金额),可根据时间查找具体的信息,将鼠标放在统计图的某个时间上就会显示出具体信息。 2、下单数量:展示的是下单数量(已经下单的总数)、支付数量(下单后的所有金额)、下单-支付妆化率。可根据搜索时间查看
-
会员分析
一、会员分析 点击进入会员分析页:该页主要展示的是基本数据和会员数据分析。 1、基本数据:展示的是会员总数,下了单的会员总数,微信的粉丝总数。 2、会员数据分析:可查看新增会员数(点击新增会员数会将此信息对应的颜色线条显示或者隐藏后显示其他的信息统计)、成交会员数(点击成交会员数会将此信息对应的颜色线条显示或者隐藏后显示其他的信息统计)、新增粉丝数(点击新增粉丝数会将此信息对应的颜色线条显示或者隐
-
商品分析
一、商品分析 点击进入商品分析页:该页主要展示的是基本数据、商品售出分析、商品构成比例以及商品销售排行。 1、基本数据: (1)商品总数:展示的是商城里商品总个数。 (2)在售商品数:指目前已上架正在售卖的商品数量。 (3)仓库中商品数:指目前仓库里待售出的商品总数。 (4)分销商品数:指参与分销(体现在佣金)的商品总数。 2、商品售出分析:展示的是商品每天或者每月售出的统计图。可根据时间查看,可
-
路径分析
路径分析是用户浏览网站各个不同的可视化呈现,它展示了用户从进入网页之后,到不同浏览路径以及各个退出节点。 利用路径分析,可查看用户浏览路径,检视站点是否存在不利于引导用户浏览的设计缺陷页面等。 6.5.1 路径分析的维度、指标介绍 维度介绍 维度名称 含义 起始页面 用户进入网站的落地页面 首次互动 用户在网站中产生交互行为后,浏览的第一个页面 第N次互动 用户在网站中产生交互行为后,浏览的第N个
-
受众分析
引言 对于网站用户分析, SiteMonitor V5 支持从网站访客使用的设备,操作系统,客户端(如浏览器、App)等角度进行分析挖掘,同时也支持统计网站访客的地域分布; 设备相关信息的获取 在HTTP 传输协议中,其Header部分包含了user-agent ( 用户代理 ) 信息,它对所访问的网站提供了用户所使用的浏览器类型及版本,操作系统及版本,浏览器内核,用户移动设备等信息; 通过这些信
-
来源分析
网站访客的来源渠道众多,网站分析系统,根据自身处理逻辑,对网站访客来源进行分割、匹配,访客来源主要可分为广告活动,搜索引擎,社交媒体,其他来源,直接访问等; 4.2.1 互斥来源分类 4.2.1.1 什么是互斥来源分类? 互斥来源分类,即根据不同渠道权重不同的原则,将同时具有2个来源渠道的流量,归结到单一优先渠道来源。 4.2.1.2 互斥来源分类场景示例 当我们分析网站访客的来源时,会发现存在一
-
C#虚函数用法实例分析
本文向大家介绍C#虚函数用法实例分析,包括了C#虚函数用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#虚函数用法。分享给大家供大家参考。具体如下: 希望本文所述对大家的C#程序设计有所帮助。
-
Oracle开发之分析函数总结
本文向大家介绍Oracle开发之分析函数总结,包括了Oracle开发之分析函数总结的使用技巧和注意事项,需要的朋友参考一下 这一篇是对前面所有关于分析函数的文章的总结: 一、统计方面: 具体请参考《Oracle开发之分析函数简介Over用法》和《Oracle开发之窗口函数》 二、排列方面: 具体请参考《Oracle开发之分析函数(Rank, Dense_rank, row_number)》 三、最
-
C++析构函数解分配失败
在下面的C++代码中,在析构函数调用期间,它会崩溃,并出现以下错误。 如果打印了这条消息,至少程序还没有崩溃!但您可能还想打印其他诊断消息。DSCodes(16782,0x1000EFE00)malloc:***对象0x10742E2F0错误:未分配释放的指针DSCodes(16782,0x1000EFE00)malloc:***在malloc_error_break中设置断点以调试 有人能告诉我
-
PHP函数func_num_args用法实例分析
本文向大家介绍PHP函数func_num_args用法实例分析,包括了PHP函数func_num_args用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP函数func_num_args用法。分享给大家供大家参考,具体如下: 运行结果如下: 希望本文所述对大家php程序设计有所帮助。
-
smarty内置函数capture用法分析
本文向大家介绍smarty内置函数capture用法分析,包括了smarty内置函数capture用法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了smarty内置函数capture用法。分享给大家供大家参考。具体分析如下: {capture}可以捕获标记范围内的输出内容,并存到变量中而不显示。有三种用法, 代码如下: 第一种:{capture}使用name属性; 第二种:{capt
-
 JS数组splice操作实例分析
JS数组splice操作实例分析本文向大家介绍JS数组splice操作实例分析,包括了JS数组splice操作实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS数组splice操作。分享给大家供大家参考,具体如下: node2:/var/www/html/js#cat h23.js ps:数组长度相应改变,但是原来的数组索引也相应改变,splice参数中第一个2,是删除的起始索引(从0算起),在此是数组第二个元
-
Javascript数组与字典用法分析
本文向大家介绍Javascript数组与字典用法分析,包括了Javascript数组与字典用法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了Javascript数组与字典用法。分享给大家供大家参考。具体分析如下: Javascript 的数组Array,既是一个数组,也是一个字典(Dictionary). 先举例看看数组的用法。 上面的代码创立了一个数组,每个元素都是一个字符串对象。
-
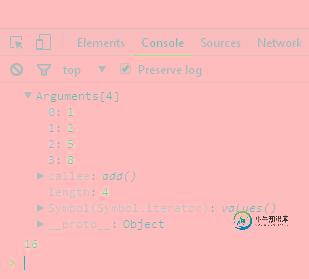 JavaScript伪数组用法实例分析
JavaScript伪数组用法实例分析本文向大家介绍JavaScript伪数组用法实例分析,包括了JavaScript伪数组用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JavaScript伪数组用法。分享给大家供大家参考,具体如下: 在Javascript中什么是伪数组? 伪数组(类数组):无法直接调用数组方法或期望length属性有什么特殊的行为,但仍可以对真正数组遍历方法来遍历它们。 1.典型的是函数的 a
-
使用Python解析数据以创建json数据对象
问题内容: 这是我从Google bigquery解析的数据: 作为Python新手,我真的不知道如何解析该数据以创建一个json对象,如下所示: 任何人都可以给我一些入门的提示吗? 例 在这个单词中,是995和1600。因此也是如此。 问题答案: 如果“ Z”是您的大词典,则在“响应”上您将获得所需的结构。 响应后,您将获得以下信息: 我相信它是您所需要的。比仅使用json对响应做一个就可以了。